El RAG: Consultar sus datos con un LLM
Este documento explica los conceptos fundamentales detrás de la técnica de Retrieval-Augmented Generation (RAG).
Los conceptos abordados aquí se ilustran en un demo completo y funcional disponible en nuestro GitHub. Es una excelente base de partida para comprender el funcionamiento práctico de un pipeline RAG.
El problema: Los LLMs no tienen memoria a largo plazo
Un gran modelo de lenguaje (LLM) como Mistral o Granite es muy potente, pero solo conoce los datos en los que fue entrenado. No conoce sus documentos internos, los últimos artículos de prensa o las especificidades de su profesión.
El RAG es una técnica que permite darle al LLM un "memoria externa" proporcionándole, en el momento de la pregunta, los extractos de documentos más relevantes para ayudarle a formular su respuesta.
El proceso se desarrolla en dos etapas:
- Recuperación (Retrieval): Encontrar los buenos documentos.
- Generación Aumentada (Augmented Generation): Utilizar estos documentos para generar una respuesta.
Es esta etapa de Recuperación la que está en el centro de nuestro tema. ¿Cómo logra un ordenador "entender" que una pregunta y un párrafo hablan de lo mismo? La magia ocurre gracias a los vectores.
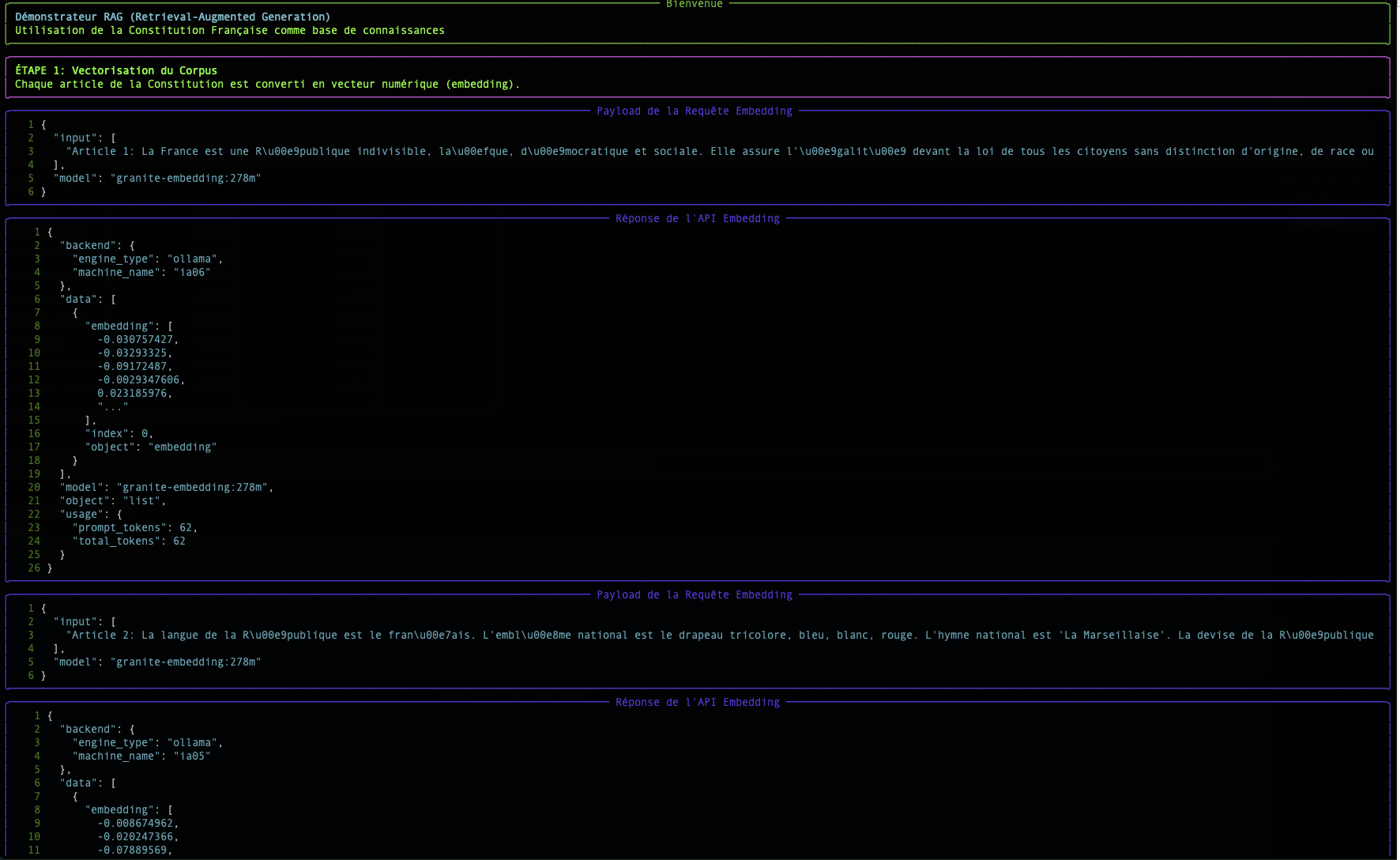
Paso 1: El Embedding: Transformar las palabras en números
Un ordenador no entiende las palabras, pero es excelente para manipular números. El embedding es el proceso que traduce un texto (una palabra, una frase, un documento) en una lista de números, llamada vector.
En términos simples, un vector es una lista de números que representa un punto en un espacio de múltiples dimensiones. Cada número en el vector corresponde a una coordenada en un "eje" de este espacio. Para los embeddings de texto, estos ejes no son x, y, z sino dimensiones semánticas abstractas (por ejemplo, un eje podría representar el concepto de "monarquía", otro el de "gato", etc.).
"El gato está en la alfombra." → [-0.01, 0.98, 0.45, ..., -0.33]
Este vector no es aleatorio. Representa la "posición" del texto en un espacio semántico multidimensional. Textos con un significado similar tendrán vectores que apuntan en direcciones similares.
Imagina un mapa geográfico. "París" y "Francia" estarían muy cerca, al igual que "Roma" e "Italia". "París" estaría más lejos de "Roma" que de "Francia", pero más cerca que de "Tokio". El embedding hace lo mismo, pero con miles de "dimensiones" en lugar de dos, para capturar matices de significado complejos.
En nuestro script, el endpoint /v1/embeddings y el modelo granite-embedding:278m son responsables de esta traducción.
Enfoque en los modelos Granite Embedding
Los embeddings son una parte integral del ecosistema LLM. Un medio preciso y eficaz para representar palabras, consultas y documentos en formato numérico es esencial para una serie de tareas empresariales, incluida la búsqueda semántica, la búsqueda vectorial y la RAG, así como para mantener bases de datos vectoriales eficientes. Un modelo de embedding eficaz puede mejorar significativamente la comprensión de la intención del usuario por parte del sistema y aumentar la relevancia de la información y las fuentes en respuesta a una consulta.
Mientras que en los últimos dos años se ha producido una proliferación de LLM open source autoregresivos cada vez más competitivos para tareas como la generación y síntesis de texto, los modelos de embedding open source publicados por los principales proveedores son relativamente escasos.
¿Por qué Granite Embedding?
Los nuevos modelos Granite Embedding de IBM, que ponemos a su disposición, son una evolución mejorada de la familia de modelos de lenguaje de solo codificación basados en RoBERTa, denominada Slate. Se distinguen en varios puntos clave para su uso en entornos empresariales:
- Entrenamiento ético y comercialmente seguro: Mientras que la mayor parte de los modelos de embedding abiertos del ranking MTEB de Hugging Face se basan en conjuntos de datos de entrenamiento únicamente con licencia para fines de investigación (como MS-MARCO), IBM ha verificado la viabilidad comercial de todas las fuentes de datos utilizadas para entrenar Granite Embedding.
- Indemnización de propiedad intelectual: Destacando el cuidado en su uso en entornos empresariales, IBM respalda a Granite Embedding con el mismo nivel de indemnización sin límite para reclamaciones de terceros relacionadas con propiedad intelectual que el previsto para el uso de otros modelos desarrollados por IBM.
- Rendimiento y eficiencia: Los esfuerzos de IBM en la organización y filtrado de los datos de entrenamiento no han impedido que los modelos Granite Embedding mantengan el ritmo de los principales modelos de embedding de código abierto de tamaño similar.
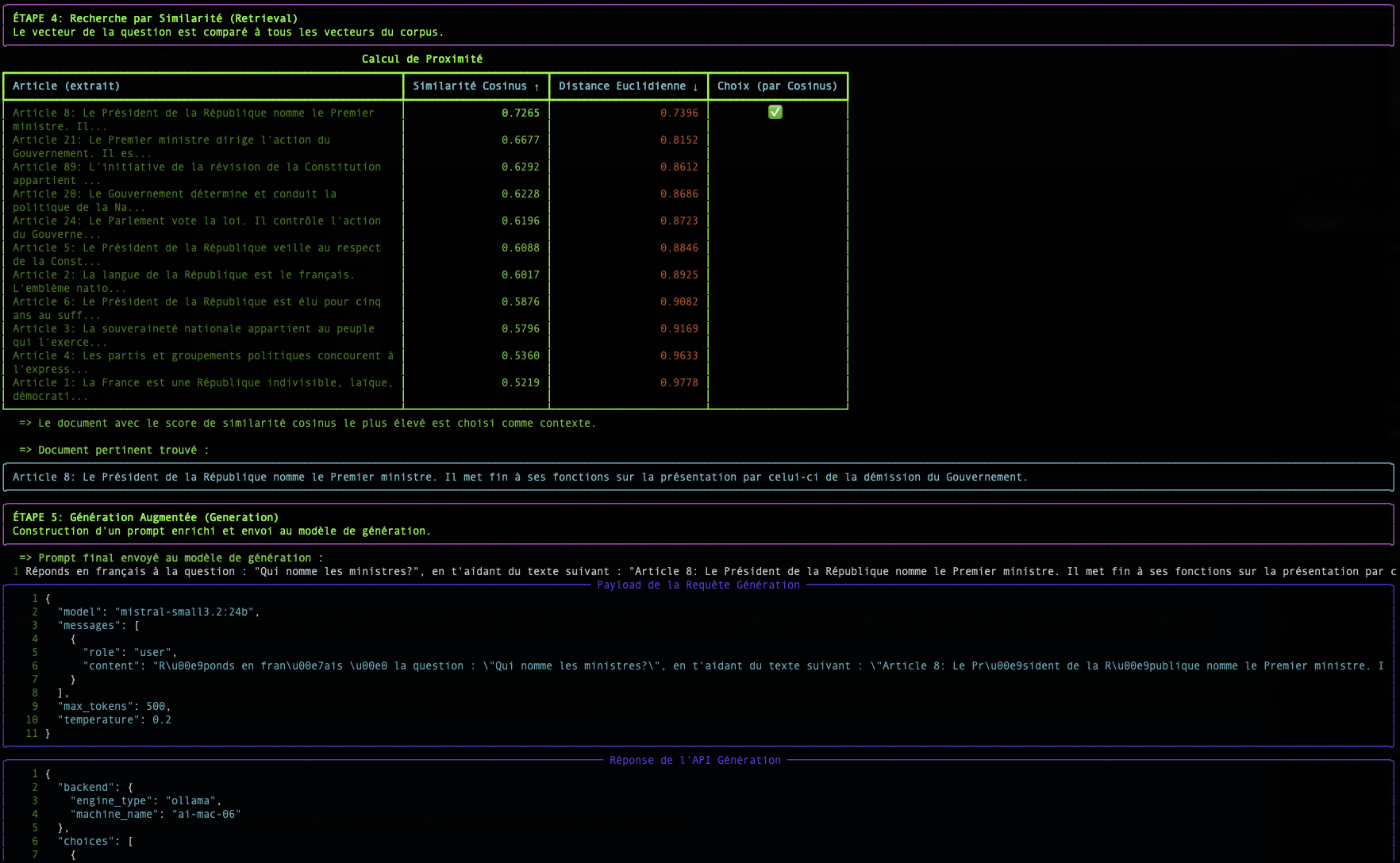
Los benchmarks a continuación ilustran dos ventajas clave:
- Precisión de la búsqueda: El primer gráfico muestra que los modelos Granite (en azul) son muy competitivos, e incluso superiores, a modelos de tamaño similar en tareas de búsqueda semántica (
Retrieval Tasks). - Velocidad de inferencia: El segundo gráfico muestra que los modelos Granite son notablemente más rápidos (tiempo por consulta más bajo) que la mayoría de las alternativas populares, lo que es una ventaja considerable para aplicaciones que requieren respuestas en tiempo real.
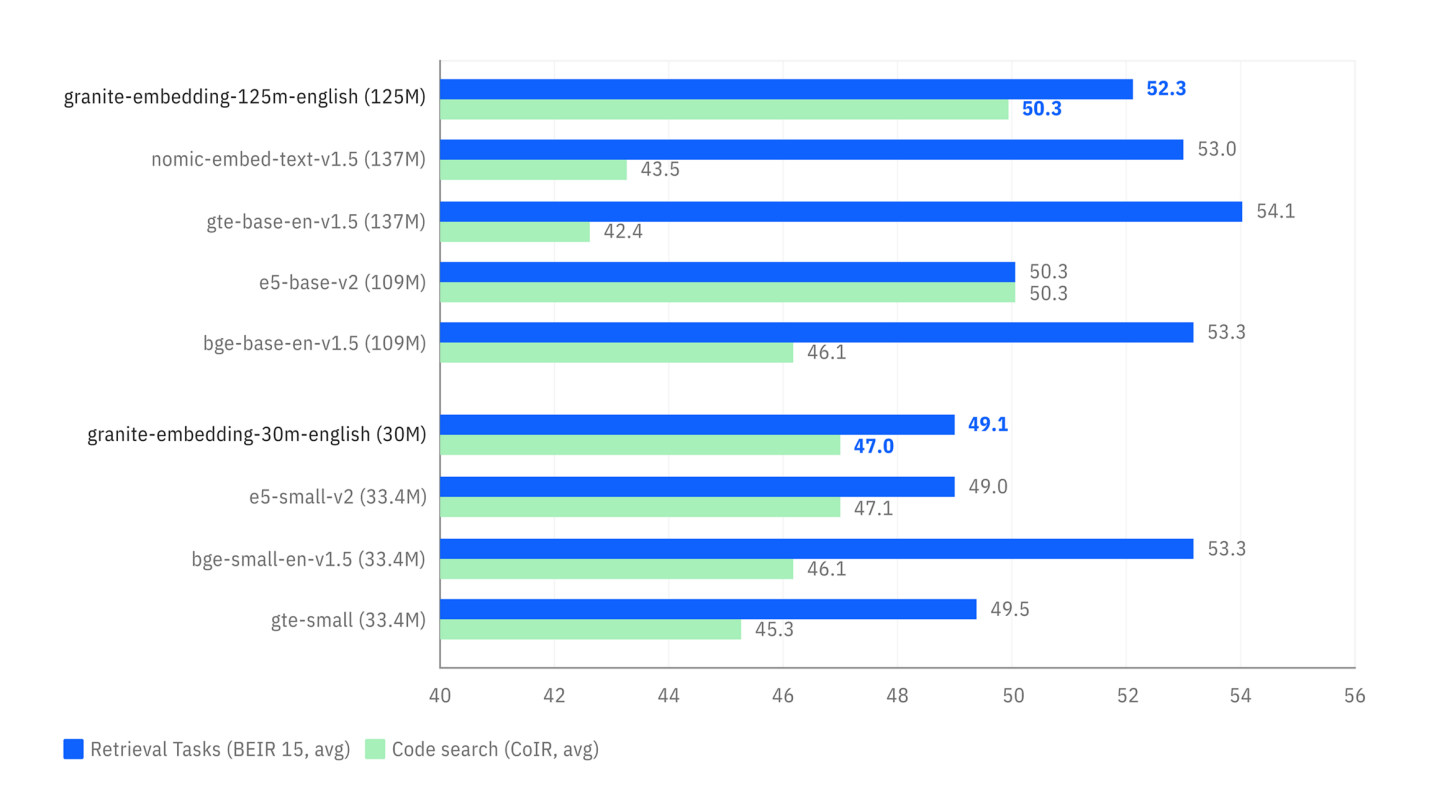 Comparación del rendimiento en tareas de búsqueda (BEIR) y búsqueda de código (CoIR).
Comparación del rendimiento en tareas de búsqueda (BEIR) y búsqueda de código (CoIR).
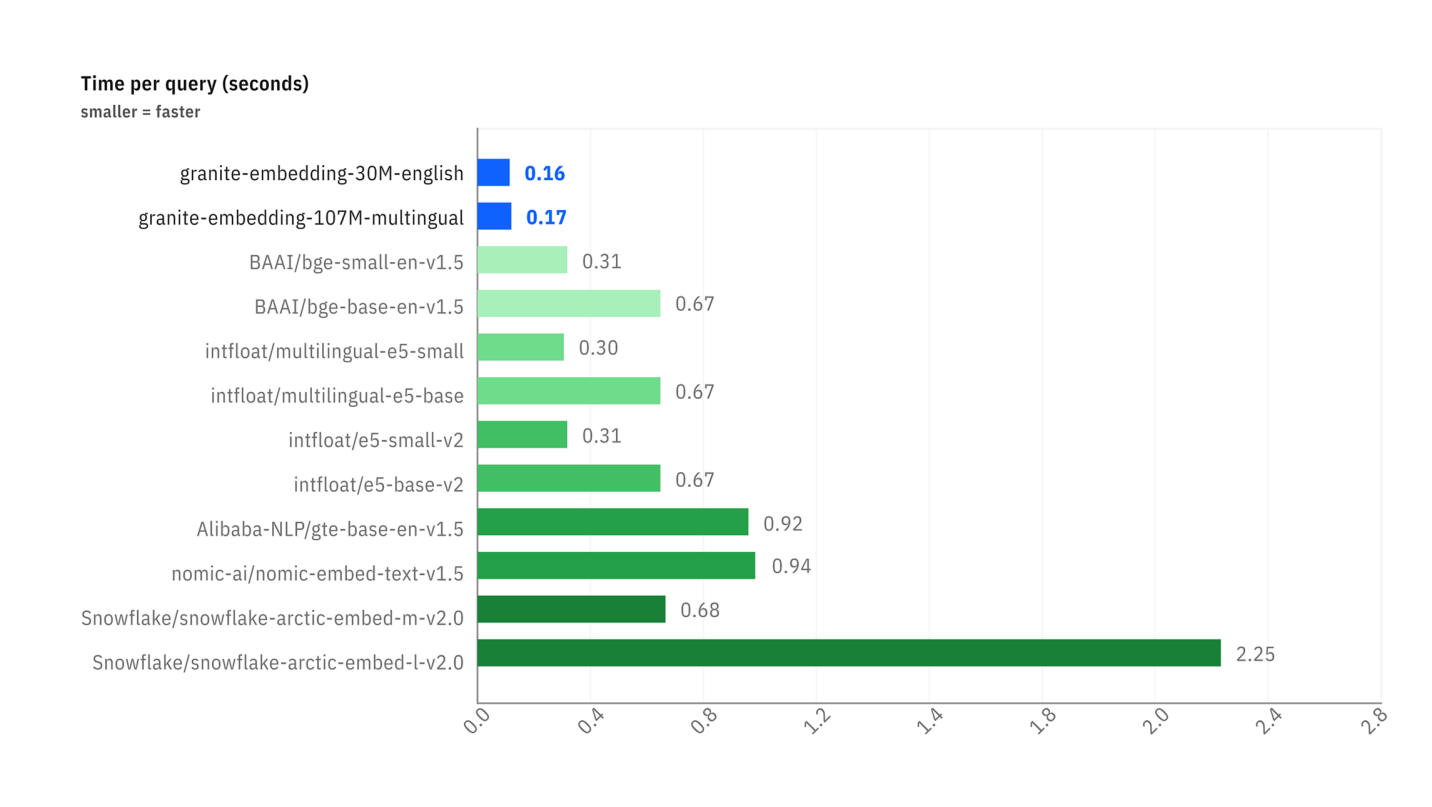 Comparación de la latencia (tiempo por consulta en segundos) entre diferentes modelos de embedding.
Comparación de la latencia (tiempo por consulta en segundos) entre diferentes modelos de embedding.
Es por este equilibrio entre rendimiento, velocidad, seguridad jurídica y ética que hemos elegido integrar el modelo granite-embedding:278m (la versión multilingüe más potente) como servicio de embedding predeterminado.
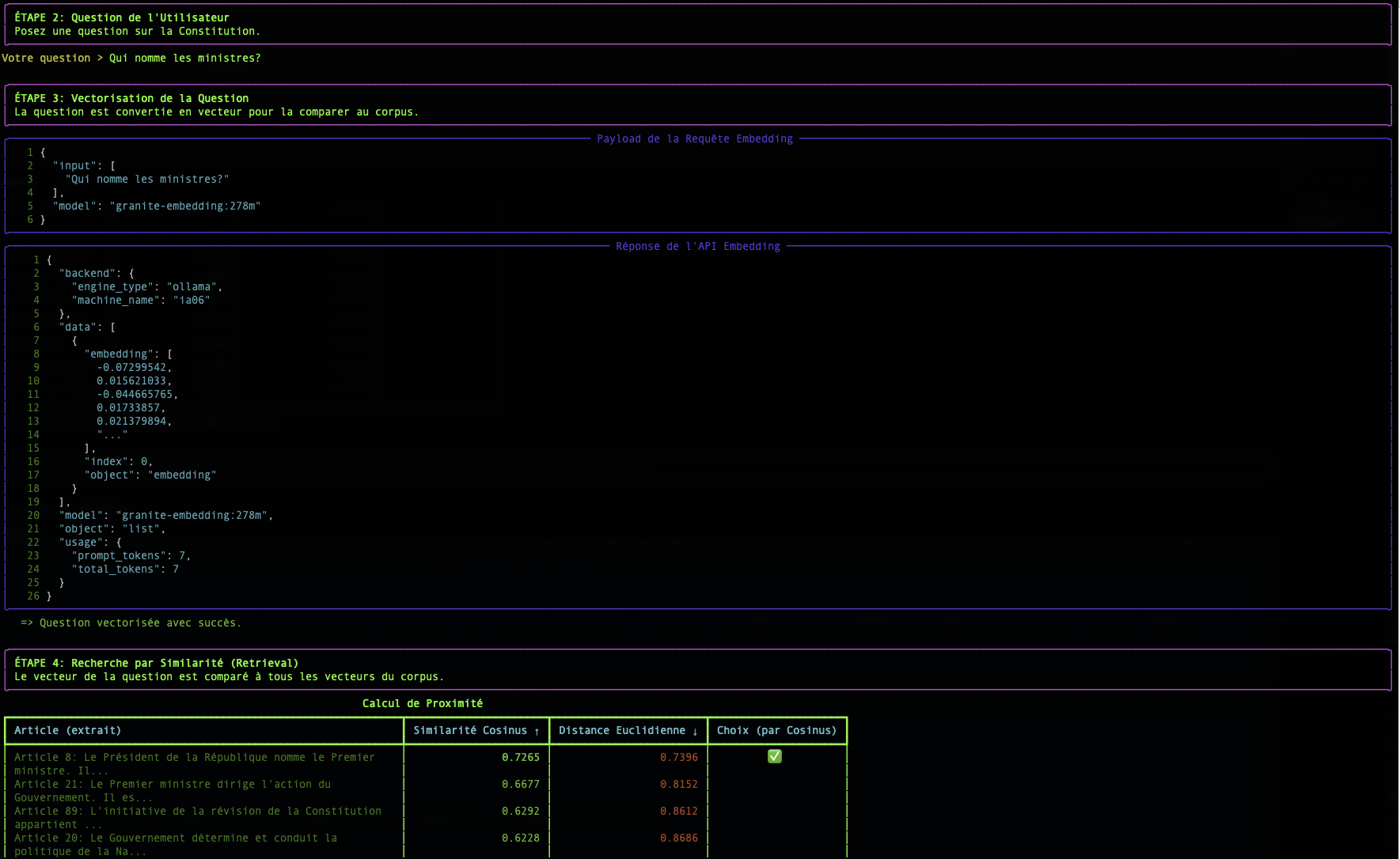
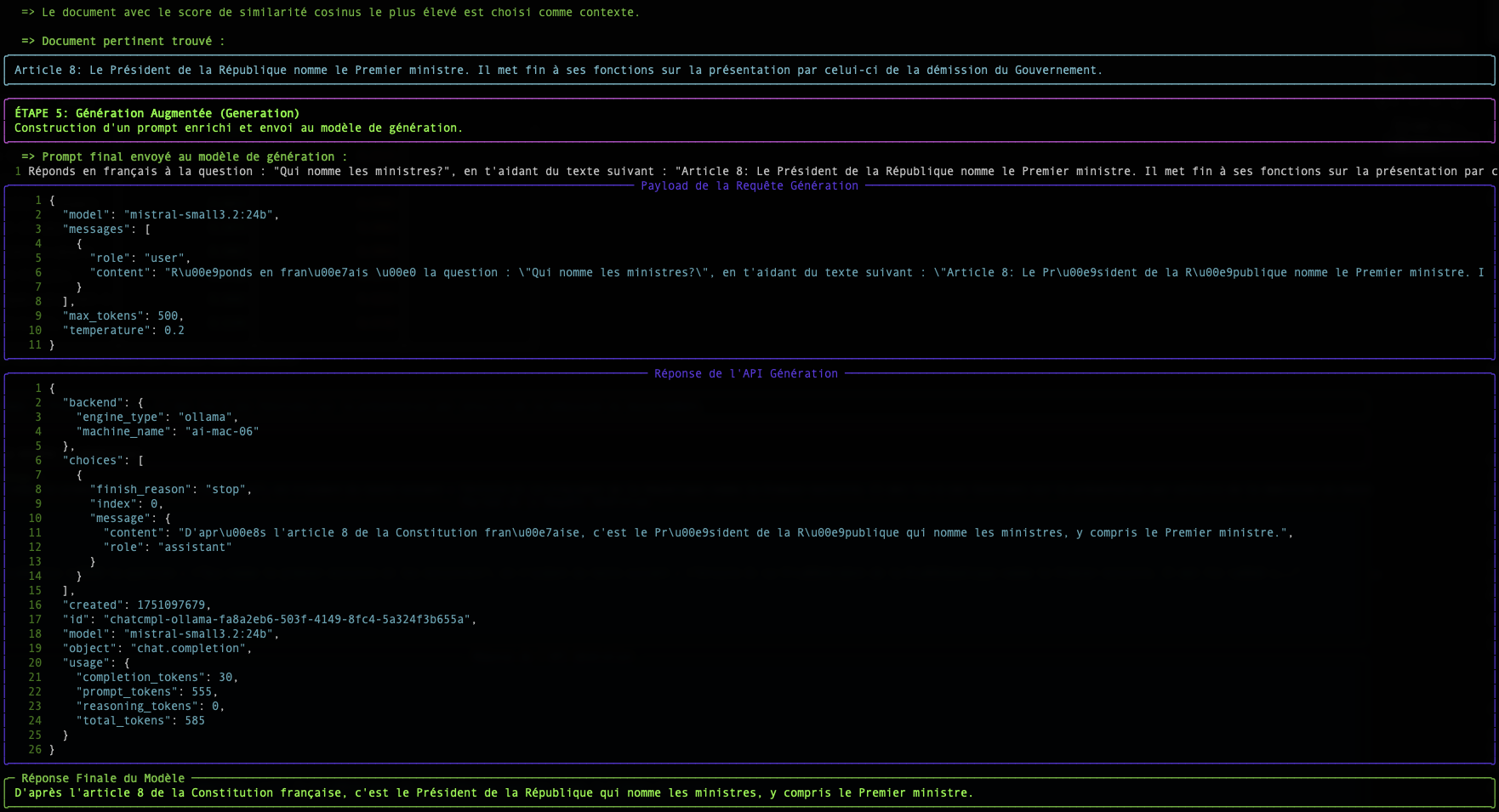
Paso 2: La Búsqueda: Medir la Proximidad Semántica
Una vez que nuestra pregunta y todos nuestros documentos son transformados en vectores, la búsqueda se convierte en un problema matemático: encontrar el vector de documento más "cercano" al vector de la pregunta.
Existen varias formas de medir esta "proximidad". Nuestro script utiliza dos: la Similitud Coseno y la Distancia Euclidiana.
La Similitud Coseno (el estándar)
- Concepto : No mide la distancia, sino el ángulo entre dos vectores. Un ángulo pequeño (cerca de 0°) significa que los vectores apuntan en la misma dirección, por lo tanto, los textos tienen un significado muy similar.
- Puntuación : El coseno de un ángulo de 0° es 1 (similitud perfecta). El coseno de un ángulo de 90° es 0 (ninguna similitud).
- ¿Por qué es tan utilizada? Para el texto, la dirección semántica es mucho más importante que la magnitud (la longitud) del vector. La similitud coseno ignora la magnitud y se enfoca únicamente en la dirección.
Ejemplo simple en 2D :
- Pregunta :
v_q = [2, 2] - Doc A :
v_a = [4, 4](mismo sentido, más largo) - Doc B :
v_b = [-2, 2](dirección diferente)
El cálculo de la similitud coseno dará:
cos(v_q, v_a) = 1.0→ Ángulo de 0°. Similitud perfecta.cos(v_q, v_b) = 0.0→ Ángulo de 90°. Ninguna similitud.
Este es el resultado que queremos: el Documento A es semánticamente idéntico a la pregunta, incluso si su formulación es más larga.
La Distancia Euclidiana (La Regla)
- Concepto : Es la distancia "a vuelo de pájaro" entre los puntos terminales de los dos vectores.
- Puntuación : Una puntuación de 0 significa que los vectores son idénticos. Cuanto mayor sea la puntuación, más alejados estarán.
- Inconveniente para el texto : Es sensible a la magnitud. En nuestro ejemplo anterior, la distancia entre
v_qyv_ano sería nula, ya que los vectores no tienen la misma longitud, aunque tengan la misma dirección.
Conclusión
La tabla mostrada por el script simple-rag-demo le permite visualizar estas dos métricas. Usted notará que, aunque los rankings pueden diferir ligeramente, la similitud coseno es generalmente la métrica de elección para las aplicaciones de búsqueda semántica basadas en texto.
El mayor desafío, como muestra el ejemplo, sigue siendo la calidad del modelo de embedding. Un buen modelo producirá vectores que capturan fielmente el significado, haciendo que el cálculo de proximidad, cualquiera que sea el método, sea mucho más confiable.