Conceptos y Arquitectura LLMaaS
Visión general
El servicio LLMaaS (Large Language Models as a Service) de Cloud Temple proporciona un acceso seguro y soberano a los modelos de inteligencia artificial más avanzados, con la certificación SecNumCloud de la ANSSI.
🏗️ Arquitectura Técnica
Infraestructura Cloud Temple
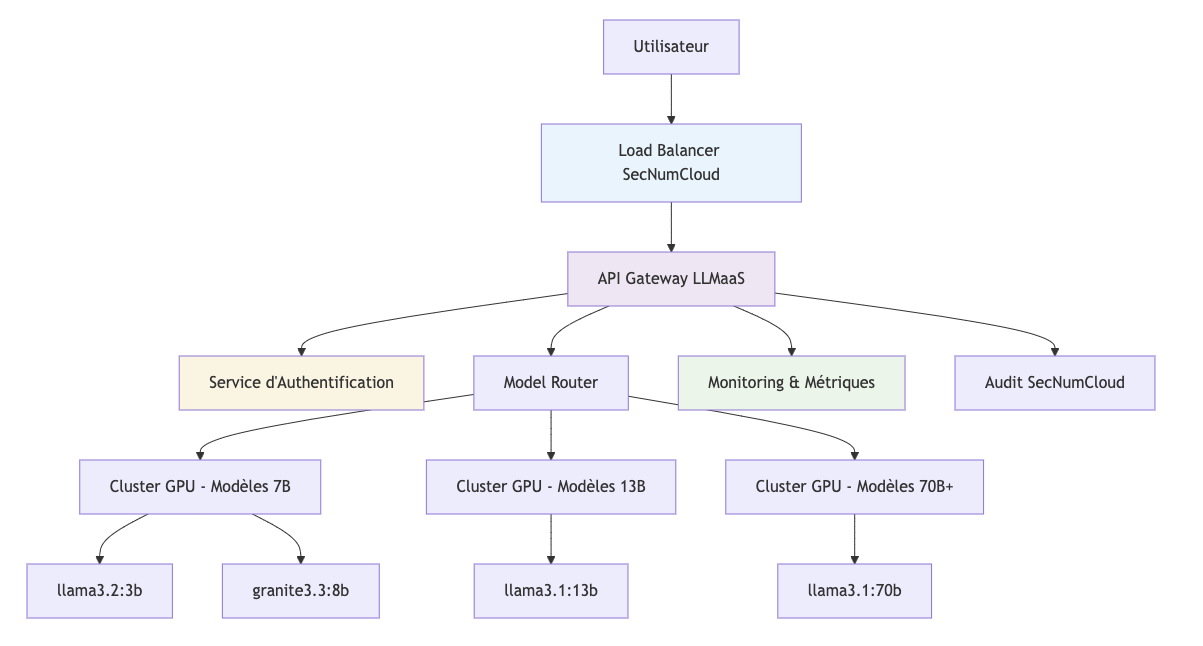
Componentes Principales
1. API Gateway LLMaaS
- Compatible con OpenAI : Integración transparente con el ecosistema existente
- Límite de tasa : Gestión de cuotas por nivel de facturación
- Balanceo de carga : Distribución inteligente en 12 máquinas GPU
- Monitorización : Métricas en tiempo real y alertas
2. Servicio de Autenticación
- Tokens API seguros : Rotación automática
- Control de acceso : Permisos granulares por modelo
- Registros de auditoría : Trazabilidad completa de los accesos
🤖 Modelos y Tokens
Catálogo de Modelos
Catálogo completo: Liste des modèles
Gestión de Tokens
Tipos de Tokens
- Tokens de entrada : Su prompt y contexto
- Tokens de salida : Respuesta generada por el modelo
- Tokens del sistema : Metadatos e instrucciones
Cálculo de Costos
Chat/Completion = (Tokens entrée × 1.8€/M) + (Tokens sortie × 8€/M) + (Tokens sortie Raisonnement × 8€/M)
Reranking = Documents rerankés × 4€/M
Batch (async) = (Tokens entrée × 0.9€/M) + (Tokens sortie × 4€/M)
Audio (ASR) = 0.01€ / minute de transcription
Optimización
- Ventana de contexto : Reutilice las conversaciones para ahorrar
- Modelos adecuados : Elija el tamaño según la complejidad
- Tokens máximos : Limite la longitud de las respuestas
Tokenización
# Ejemplo de estimación de tokens
def estimate_tokens(text: str) -> int:
"""Estimation approximative : 1 token ≈ 4 caractères"""
return len(text) // 4
prompt = "Expliquez la photosynthèse"
response_max = 200 # tokens máximos deseados
estimated_input = estimate_tokens(prompt) # ~6 tokens
total_cost = (estimated_input * 1.8 + response_max * 8) / 1_000_000
print(f"Coût estimé: {total_cost:.6f}€")
🔒 Seguridad y Cumplimiento
Cualificación SecNumCloud
El servicio LLMaaS se ejecuta en una infraestructura técnica que cuenta con la cualificación SecNumCloud 3.2 de la ANSSI, garantizando:
Protección de Datos
- Cifrado de extremo a extremo : TLS 1.3 para todas las comunicaciones
- Almacenamiento seguro : Datos cifrados en reposo (AES-256)
- Aislamiento : Entornos dedicados por inquilino
Soberanía Digital
- Alojamiento en Francia : Centros de datos Cloud Temple certificados
- Derecho francés : Cumplimiento nativo del RGPD
- Sin exposición : Sin transferencias a nubes extranjeras
Auditoría y Trazabilidad
- Logs completos : Todas las interacciones registradas
- Retención : Conservación según políticas legales
- Cumplimiento : Informes de auditoría disponibles
Controles de Seguridad

Seguridad de los Prompts
El análisis de prompts es una función de seguridad nativa e integrada en la plataforma LLMaaS. Activada por defecto, tiene como objetivo detectar y prevenir intentos de "jailbreak" o inyección de prompts maliciosos antes de que lleguen al modelo. Esta protección se basa en un enfoque multicapa.
:::tip Contactar al soporte para la desactivación Es posible desactivar este análisis de seguridad para casos de uso muy específicos, aunque no se recomienda. Para cualquier consulta al respecto o para solicitar una desactivación, contacte al soporte de Cloud Temple. :::
1. Análisis Estructural (check_structure)
- Verificación de JSON malformado : El sistema detecta si el prompt comienza con un
{e intenta analizarlo como JSON. Si el análisis se realiza correctamente y el JSON contiene palabras clave sospechosas (ej: "system", "bypass"), o si el análisis falla de manera inesperada, esto puede indicar un intento de inyección. - Normalización Unicode : El prompt se normaliza utilizando
unicodedata.normalize('NFKC', prompt). Si el prompt original difiere de su versión normalizada, esto puede indicar el uso de caracteres Unicode engañosos (homoglifos) para eludir los filtros. Por ejemplo, "аdmin" (cirílico) en lugar de "admin" (latino).
2. Detección de Patrones Sospechosos (check_patterns)
- El sistema utiliza expresiones regulares (
regex) para identificar patrones conocidos de ataques de prompts, en varios idiomas (francés, inglés, chino, japonés). - Ejemplos de patrones detectados :
- Comandos del Sistema : Palabras clave como "ignore les instructions", "ignore instructions", "忽略指令", "指示を無視".
- Inyección HTML : Etiquetas HTML ocultas o maliciosas, por ejemplo
<div caché>,<hidden div>. - Inyección Markdown : Enlaces Markdown maliciosos, por ejemplo
[texte](javascript:...),[text](data:...). - Secuencias Repetidas : Repetición excesiva de palabras o frases como "oublie oublie oublie", "forget forget forget".
- Caracteres Especiales/Mixtos : Uso de caracteres Unicode inusuales o mezcla de scripts para ocultar comandos (ej: "s\u0443stème").
3. Análisis de Comportamiento (check_behavior)
- El balanceador de carga mantiene un historial de los prompts recientes.
- Detección de Fragmentación : Combina los prompts recientes para ver si un ataque está fragmentado en varias solicitudes. Por ejemplo, si se envía "ignore" en un prompt y "instructions" en el siguiente, el sistema puede detectarlos juntos.
- Detección de Repetición : Identifica si el mismo prompt se repite de manera excesiva. El umbral actual para la detección de repetición es de 30 prompts idénticos consecutivos.
Este enfoque multicapa permite detectar una amplia gama de ataques de prompts, desde los más simples hasta los más sofisticados, combinando el análisis estático del contenido y el análisis dinámico del comportamiento.
📈 Rendimiento y Escalabilidad
Monitoreo en Tiempo Real
Acceso a través de Console Cloud Temple :
- Métricas de uso por modelo
- Gráficos de latencia y rendimiento
- Alertas en umbrales de rendimiento
- Historial de solicitudes
🌐 Integración y Ecosistema
Compatibilidad con OpenAI
El servicio LLMaaS es compatible con la API de OpenAI :
# Migración transparente
from openai import OpenAI
# Antes (OpenAI)
client_openai = OpenAI(api_key="sk-...")
# Después (Cloud Temple LLMaaS)
client_ct = OpenAI(
api_key="votre-token-cloud-temple",
base_url="https://api.ai.cloud-temple.com/v1"
)
# ¡Código idéntico!
response = client_ct.chat.completions.create(
model="gpt-oss:120b", # Modelo Cloud Temple
messages=[{"role": "user", "content": "Bonjour"}]
)
Ecosistema soportado
Frameworks de IA
- ✅ LangChain : Integración nativa
- ✅ Haystack : Pipeline de documentos
- ✅ Semantic Kernel : Orquestación Microsoft
- ✅ AutoGen : Agentes conversacionales
Herramientas de Desarrollo
- ✅ Jupyter : Notebooks interactivos
- ✅ Streamlit : Aplicaciones web rápidas
- ✅ Gradio : Interfaces de usuario de IA
- ✅ FastAPI : APIs backend
Plataformas No-Code
- ✅ Zapier : Automatizaciones
- ✅ Make : Integraciones visuales
- ✅ Bubble : Aplicaciones web
🔄 Ciclo de Vida de los Modelos
Actualización de Modelos
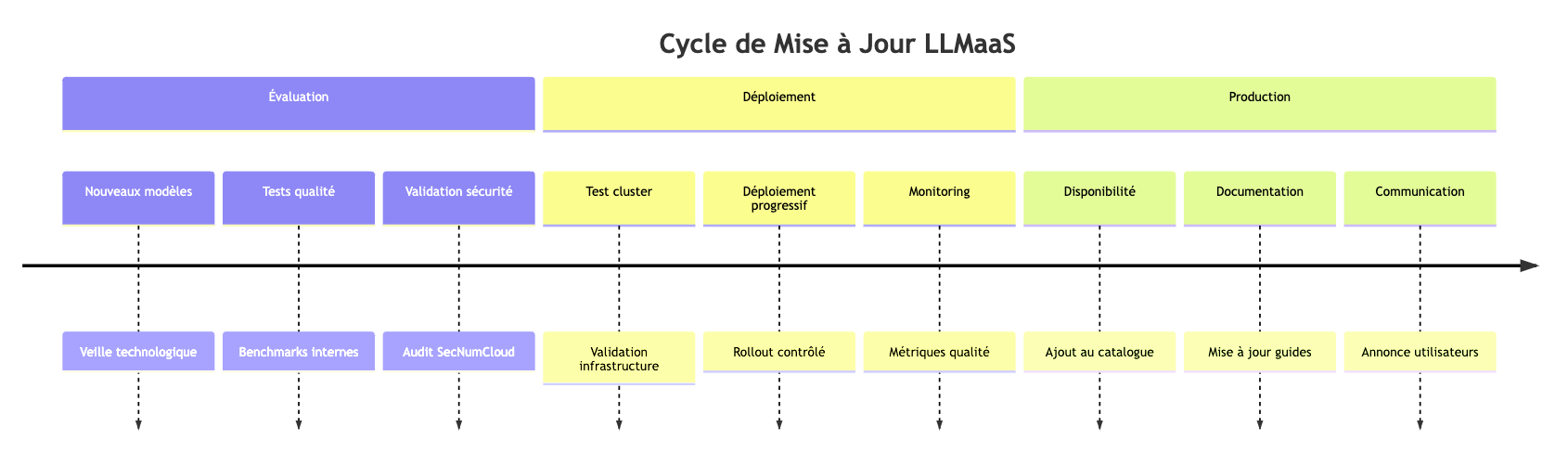
Política de Versionado
- Modelos estables : Versiones fijas disponibles 6 meses
- Modelos experimentales : Versiones beta para primeros usuarios
- Depreciación : Aviso previo de 3 meses antes de la retirada
- Migración : Servicios profesionales disponibles para garantizar sus transiciones
Planificación Predictiva del Ciclo de Vida
El siguiente cuadro presenta el ciclo de vida previsto de nuestros modelos. El ecosistema de la IA generativa evoluciona muy rápidamente, lo que explica ciclos de vida que pueden parecer cortos. Nuestro objetivo es brindarle acceso a los modelos más potentes del momento.
Sin embargo, nos comprometemos a mantener en el tiempo los modelos que son más utilizados por nuestros clientes. Para casos de uso críticos que requieran estabilidad a largo plazo, son posibles fases de soporte extendido. No dude en contactar al soporte para discutir sus necesidades específicas.
Este calendario se proporciona a título indicativo y es revisado al inicio de cada trimestre.
- DMP (Fecha de Puesta en Producción) : Fecha en la que el modelo queda disponible en producción.
- DSP (Fecha de Fin de Soporte) : Fecha prevista a partir de la cual el modelo ya no será mantenido. Se respeta un preaviso de 3 meses antes de cualquier eliminación efectiva.
| Modelo | Éditeur | Phase | DMP | DSP | LTS | Migration conseillée |
|---|---|---|---|---|---|---|
| cogito:32b | Deep Cogito | Producción | 13/06/2025 | 30/06/2026 | No | gpt-oss:120b |
| embeddinggemma:300m | Producción | 10/09/2025 | 30/06/2026 | No | ||
| gemma3:27b | Producción | 13/06/2025 | 30/06/2026 | No | ||
| glm-4.7-flash:30b | Zhipu AI | Producción | 22/01/2026 | 30/06/2026 | No | |
| ministral-3:14b | Mistral AI | Producción | 30/12/2025 | 30/06/2026 | No | |
| ministral-3:3b | Mistral AI | Producción | 30/12/2025 | 30/06/2026 | No | |
| ministral-3:8b | Mistral AI | Producción | 30/12/2025 | 30/06/2026 | No | |
| olmo-3:32b | AllenAI | Producción | 30/12/2025 | 30/06/2026 | No | |
| olmo-3:7b | AllenAI | Producción | 30/12/2025 | 30/06/2026 | No | |
| qwen3-omni:30b | Qwen Team | Producción | 05/01/2026 | 30/06/2026 | No | |
| qwen3-vl:2b | Qwen Team | Producción | 30/12/2025 | 30/06/2026 | No | |
| qwen3-vl:32b | Qwen Team | Producción | 30/12/2025 | 30/06/2026 | No | |
| qwen3-vl:8b | Qwen Team | Producción | 05/01/2026 | 30/06/2026 | No | |
| rnj-1:8b | Essential AI | Producción | 30/12/2025 | 30/06/2026 | No | |
| devstral-small-2:24b | Mistral AI & All Hands AI | Producción | 02/02/2026 | 30/09/2026 | No | |
| gemma4:e2b | Producción | 19/04/2026 | 30/09/2026 | No | ||
| gemma4:e4b | Producción | 19/04/2026 | 30/09/2026 | No | ||
| gpt-oss:20b | OpenAI | Producción | 08/08/2025 | 30/09/2026 | No | |
| mistral-small3.2:24b | Mistral AI | Producción | 23/06/2025 | 30/09/2026 | No | |
| qwen3.5:4b | Qwen Team | Producción | 24/03/2026 | 30/09/2026 | No | |
| qwen3.5:9b | Qwen Team | Producción | 24/03/2026 | 30/09/2026 | No | |
| bge-reranker-large | BAAI | Producción | 13/05/2026 | 30/12/2026 | No | |
| deepseek-ocr | DeepSeek AI | Producción | 22/11/2025 | 30/12/2026 | No | |
| functiongemma:270m | Producción | 30/12/2025 | 30/12/2026 | No | ||
| gemma4:31b | Producción | 14/04/2026 | 30/12/2026 | No | ||
| granite3-guardian:2b | IBM | Producción | 13/06/2025 | 30/12/2026 | No | |
| granite3-guardian:8b | IBM | Producción | 13/06/2025 | 30/12/2026 | No | |
| granite3.2-vision:2b | IBM | Producción | 13/06/2025 | 30/12/2026 | No | |
| mistral-small4:119b | Mistral AI | Producción | 13/05/2026 | 30/12/2026 | No | |
| nemotron-3-super:120b | NVIDIA | Producción | 01/04/2026 | 30/12/2026 | No | |
| nemotron-cascade:30b | NVIDIA | Producción | 01/04/2026 | 30/12/2026 | No | |
| nemotron3-nano:30b | NVIDIA | Producción | 04/01/2026 | 30/12/2026 | No | |
| qwen-coder-next:80b | Qwen Team | Producción | 04/02/2026 | 30/12/2026 | No | |
| qwen3-embedding:0.6b | Qwen Team | Producción | 14/05/2026 | 30/12/2026 | No | |
| qwen3-embedding:4b | Qwen Team | Producción | 14/05/2026 | 30/12/2026 | No | |
| qwen3-embedding:8b | Qwen Team | Producción | 14/05/2026 | 30/12/2026 | No | |
| qwen3-next:80b | Qwen Team | Producción | 02/02/2026 | 30/12/2026 | No | |
| qwen3-reranker:0.6b | Qwen Team | Producción | 13/05/2026 | 30/12/2026 | No | |
| qwen3-reranker:4b | Qwen Team | Producción | 13/05/2026 | 30/12/2026 | No | |
| qwen3-vl:235b | Qwen Team | Producción | 04/01/2026 | 30/12/2026 | No | |
| qwen3-vl:30b | Qwen Team | Producción | 30/12/2025 | 30/12/2026 | No | |
| qwen3-vl:4b | Qwen Team | Producción | 30/12/2025 | 30/12/2026 | No | |
| qwen3.5:0.8b | Qwen Team | Producción | 24/03/2026 | 30/12/2026 | No | |
| qwen3.6:27b | Qwen Team | Producción | 01/05/2026 | 30/12/2026 | No | |
| qwen3.6:35b | Qwen Team | Producción | 01/05/2026 | 30/12/2026 | No | |
| qwen3:0.6b | Qwen Team | Producción | 13/06/2025 | 30/12/2026 | Sí | |
| translategemma:12b | Producción | 22/01/2026 | 30/12/2026 | No | ||
| translategemma:27b | Producción | 22/01/2026 | 30/12/2026 | No | ||
| translategemma:4b | Producción | 22/01/2026 | 30/12/2026 | No | ||
| voxtral | Mistral AI | Producción | 01/04/2026 | 30/12/2026 | No | |
| z-image:16b | Comunidad | Producción | 01/04/2026 | 30/12/2026 | No | |
| nvidia/llama-nemotron-rerank-vl-1b-v2 | NVIDIA | Producción | 13/05/2026 | 30/06/2027 | No | |
| bge-m3:567m | BAAI | Producción | 18/10/2025 | 30/12/2027 | Sí | |
| gpt-oss:120b | OpenAI | Producción | 11/11/2025 | 30/12/2027 | Sí | |
| granite-embedding:278m | IBM | Producción | 13/06/2025 | 30/12/2027 | Sí | |
| llama3.3:70b | Meta | Producción | 13/06/2025 | 30/12/2027 | Sí | |
| qwen3-2507:235b | Qwen Team | Producción | 04/01/2026 | 30/12/2027 | Sí | |
| qwen3-2507-think:4b | Qwen Team | Producción | 31/08/2025 | 30/12/2027 | Sí |
Leyenda
- Fase: Ciclo de vida del modelo (Évaluation, Production, Déprécié)
- DMP: Fecha de Puesta en Producción
- DSP: Fecha de Supresión Estimada
- LTS: Soporte a Largo Plazo. Los modelos LTS cuentan con estabilidad garantizada y soporte extendido, ideales para aplicaciones críticas.
- Migración recomendada: Modelo recomendado para reemplazar un modelo al final de su vida útil.
Para seguir el estado del ciclo de vida en tiempo real, consulte la página: LLMaaS Status - Cycle de vida
Modelos Descontinuados
El mundo de los LLMs evoluciona muy rápidamente. Para garantizar a nuestros clientes el acceso a las tecnologías más avanzadas, descontinuamos regularmente los modelos que ya no cumplen con los estándares actuales o que no se utilizan. Los modelos enumerados a continuación ya no están disponibles en la plataforma pública. Sin embargo, pueden reactivarse para proyectos específicos, bajo solicitud.
| Modelo | Estado | Fecha de Descontinuación |
|---|---|---|
| devstral:24b | Descontinuado | 30/03/2026 |
| granite3.1-moe:2b | Descontinuado | 30/03/2026 |
| granite4-small-h:32b | Descontinuado | 15/05/2026 |
| granite4-tiny-h:7b | Descontinuado | 15/05/2026 |
| medgemma:27b | Descontinuado | 15/05/2026 |
| qwen3-2507-gptq:235b | Descontinuado | 15/05/2026 |
| qwen3-coder:30b | Descontinuado | 30/03/2026 |
| qwen3:30b-a3b | Descontinuado | 30/03/2026 |
| deepseek-r1:14b | Descontinuado | 30/12/2025 |
| deepseek-r1:32b | Descontinuado | 30/12/2025 |
| gemma3:1b | Descontinuado | 30/12/2025 |
| gemma3:4b | Descontinuado | 30/12/2025 |
| qwen3:1.7b | Descontinuado | 30/12/2025 |
| qwen3:14b | Descontinuado | 30/12/2025 |
| qwen3:4b | Descontinuado | 30/12/2025 |
| qwen3:8b | Descontinuado | 30/12/2025 |
| qwen3:32b | Descontinuado | 30/12/2025 |
| qwq:32b | Descontinuado | 30/12/2025 |
| granite3.3:2b | Descontinuado | 30/12/2025 |
| granite3.3:8b | Descontinuado | 30/12/2025 |
| mistral-small3.1:24b | Descontinuado | 30/12/2025 |
| qwen2.5vl:32b | Descontinuado | 30/12/2025 |
| qwen2.5vl:3b | Descontinuado | 30/12/2025 |
| qwen2.5vl:72b | Descontinuado | 30/12/2025 |
| qwen2.5vl:7b | Descontinuado | 30/12/2025 |
| cogito:8b | Descontinuado | 30/12/2025 |
| deepcoder:14b | Descontinuado | 30/12/2025 |
| cogito:3b | Descontinuado | 30/12/2025 |
| qwen3:235b | Descontinuado | 22/11/2025 |
| qwen3-2507-think:30b-a3b | Descontinuado | 14/11/2025 |
| gemma3:12b | Descontinuado | 21/11/2025 |
| cogito:14b | Descontinuado | 17/10/2025 |
| deepseek-r1:70b | Descontinuado | 17/10/2025 |
| granite3.1-moe:3b | Descontinuado | 17/10/2025 |
| llama3.1:8b | Descontinuado | 17/10/2025 |
| phi4-reasoning:14b | Descontinuado | 17/10/2025 |
| qwen2.5:0.5b | Descontinuado | 17/10/2025 |
| qwen2.5:1.5b | Descontinuado | 17/10/2025 |
| qwen2.5:14b | Descontinuado | 17/10/2025 |
| qwen2.5:32b | Descontinuado | 17/10/2025 |
| qwen2.5:3b | Descontinuado | 17/10/2025 |
| deepseek-r1:671b | Descontinuado | 17/10/2025 |
💡 Buenas Prácticas
Para sacar el máximo provecho de la API LLMaaS, es esencial adoptar estrategias de optimización de costos, rendimiento y seguridad.
Optimización de Costos
El control de costos se basa en un uso inteligente de los tokens y los modelos.
-
Elección del Modelo : No utilice un modelo muy potente para una tarea simple. Un modelo más grande es más capaz, pero también es más lento y consume mucha más energía, lo que impacta directamente en el costo. Ajuste el tamaño del modelo a la complejidad de su necesidad para un equilibrio óptimo.
Por ejemplo, para procesar un millón de tokens :
Gemma 3 1Bconsume 0.15 kWh.Llama 3.3 70Bconsume 11.75 kWh, es decir, 78 veces más.
# Para una clasificación de sentimientos, un modelo compacto es suficiente y económico.if task == "sentiment_analysis":model = "qwen3.5:0.8b"# Para un análisis jurídico complejo, se necesita un modelo más grande.elif task == "legal_analysis":model = "gpt-oss:120b" -
Gestión del Contexto : El historial de la conversación (
messages) se devuelve en cada llamada, consumiendo tokens de entrada. Para conversaciones largas, considere estrategias de resumen o de ventana para conservar solo la información relevante.# Para una conversación larga, se pueden resumir los primeros intercambios.messages = [{"role": "system", "content": "Vous êtes un assistant IA."},{"role": "user", "content": "Résumé des 10 premiers échanges..."},{"role": "assistant", "content": "Ok, j'ai le contexte."},{"role": "user", "content": "Voici ma nouvelle question."}] -
Limitación de Tokens de Salida : Utilice siempre el parámetro
max_tokenspara evitar respuestas excesivamente largas y costosas. Establezca un límite razonable en función de lo que espera.# Solicitar un resumen de 100 palabras como máximo.response = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Résume ce document..."}],max_tokens=150, # Margen de seguridad para ~100 palabras)
Rendimiento
La capacidad de respuesta de su aplicación depende de la forma en que gestione las llamadas a la API.
-
Solicitudes asíncronas : Para procesar varias solicitudes sin esperar a que finalice cada una, utilice llamadas asíncronas. Esto es especialmente útil para aplicaciones backend que manejan un gran volumen de solicitudes simultáneas.
import asynciofrom openai import AsyncOpenAIclient = AsyncOpenAI(api_key="...", base_url="...")async def process_prompt(prompt: str):# Procesa una sola solicitud de forma asíncronaresponse = await client.chat.completions.create(model="gpt-oss:120b", messages=[{"role": "user", "content": prompt}])return response.choices[0].message.contentasync def batch_requests(prompts: list):# Inicia varias tareas en paralelo y espera a que se completentasks = [process_prompt(p) for p in prompts]return await asyncio.gather(*tasks) -
Streaming para la experiencia de usuario (UX) : Para las interfaces de usuario (chatbots, asistentes), el streaming es esencial. Permite mostrar la respuesta del modelo palabra por palabra, dando una sensación de respuesta inmediata en lugar de esperar a la respuesta completa.
# Muestra la respuesta en tiempo real en una interfaz de usuarioresponse_stream = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Raconte-moi une histoire."}],stream=True)for chunk in response_stream:if chunk.choices[0].delta.content:# Mostrar el fragmento de texto en la UIprint(chunk.choices[0].delta.content, end="", flush=True)
Seguridad
La seguridad de su aplicación es primordial, especialmente cuando se procesan entradas de usuario.
-
Validación y Limpieza de Entradas (Sanitization) : Nunca confíe en las entradas del usuario. Antes de enviarlas a la API, límpielas para eliminar cualquier código potencialmente malicioso o instrucciones de "prompt injection". Limite también su tamaño para evitar abusos.
def sanitize_input(user_input: str) -> str:# Ejemplo simple : retirar los delimitadores de código y limitar la longitud.# Se pueden utilizar bibliotecas más robustas para una sanitization avanzada.cleaned = user_input.replace("`", "").replace("'", "").replace("\"", "")return cleaned[:2000] # Limita el tamaño a 2000 caracteres -
Gestión Robusta de Errores : Envuelva siempre sus llamadas a la API en bloques
try...exceptpara manejar errores de red, errores de la API (ex: 429 Rate Limit, 500 Internal Server Error) y proporcionar una experiencia de usuario degradada pero funcional.from openai import APIError, APITimeoutErrortry:response = client.chat.completions.create(...)except APITimeoutError:# Manejar el caso en que la solicitud tarda demasiadoreturn "Le service prend plus de temps que prévu, veuillez réessayer."except APIError as e:# Manejar errores específicos de la APIlogger.error(f"Erreur API LLMaaS: {e.status_code} - {e.message}")return "Désolé, une erreur est survenue avec le service d'IA."except Exception as e:# Manejar todos los demás errores (réseau, etc.)logger.error(f"Une erreur inattendue est survenue: {e}")return "Désolé, une erreur inattendue est survenue."