Utiliser un GPU sur Managed Kubernetes
Ce tutoriel vous montre comment déployer un pod qui utilise une ressource GPU sur un cluster Managed Kubernetes configuré avec des nœuds "Bare Metal" équipés de GPU NVIDIA.
Prérequis
- Un cluster Managed Kubernetes avec au moins un nœd worker de type "Bare Metal" avec GPU.
Manifeste de Pod d'exemple
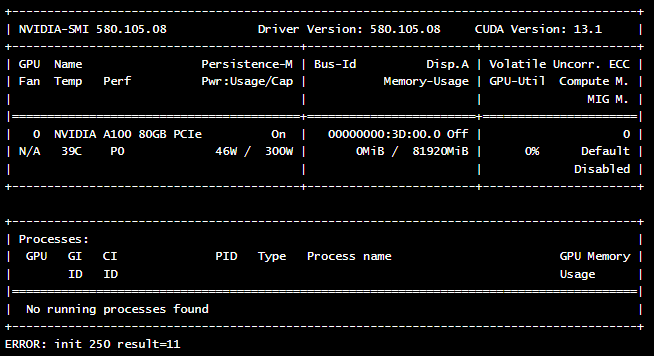
Voici un exemple de manifeste de pod qui exécute la commande nvidia-smi pour vérifier la présence et l'état de la carte GPU.
apiVersion: v1
kind: Pod
metadata:
name: nvidia-cuda-check
spec:
runtimeClassName: nvidia # Clé pour Talos NVIDIA
restartPolicy: Never
containers:
- name: nvidia-version-check
image: "nvidia/cuda:13.1.0-devel-ubuntu24.04"
imagePullPolicy: Always
command: ["nvidia-smi"]
Explication du Manifeste
runtimeClassName: nvidia: C'est la partie la plus importante. Elle indique à Kubernetes d'utiliser le runtime NVIDIA. Le toolkit NVIDIA s'occupe alors d'injecter les drivers NVIDIA directement dans le pod, ce qui permet au conteneur d'accéder au GPU.restartPolicy: Never: Comme ce pod est juste une commande de vérification, nous ne voulons pas qu'il redémarre après son exécution.image: "nvidia/cuda:...": Nous utilisons une image fournie par NVIDIA qui contient les outils nécessaires pour interagir avec le GPU.command: ["nvidia-smi"]: C'est la commande qui sera exécutée à l'intérieur du conteneur.nvidia-smiest un outil en ligne de commande qui fournit des informations sur les GPU NVIDIA.
Pour plus d'informations sur le fonctionnement du toolkit NVIDIA, vous pouvez consulter la documentation officielle sur GitHub.
Déploiement et Vérification
-
Déployez le pod en utilisant la commande
kubectl apply:kubectl apply -f nvidia-smi.yaml -
Vérifiez les logs du pod pour voir la sortie de la commande
nvidia-smi:kubectl logs nvidia-cuda-check
Si tout est configuré correctement, vous devriez voir une sortie similaire à celle-ci, montrant les détails de votre carte GPU :