Concepts
Nos offres Managed Kubernetes
Cloud Temple propose deux offres distinctes pour répondre à vos besoins en matière d'orchestration de conteneurs :
- Managed Core Kubernetes : Un produit minimaliste qui vous fournit un socle Kubernetes robuste et sécurisé, basé sur des composants open-source de pointe. Elle est idéale pour les équipes expertes qui souhaitent construire leur propre plateforme sur-mesure.
- Managed Kubernetes : Une solution complète et prête à l'emploi qui inclut une stack complète d'outils pour le réseau, la sécurité, le stockage, le déploiement continu, l'observabilité, la sauvegarde et la gestion des coûts.
Tableau comparatif des offres
| Composant | Managed Core Kubernetes | Managed Kubernetes |
|---|---|---|
| OS | Talos | Talos |
| CNI | Cilium | Cilium |
| Observabilité CNI | ❌ | Hubble |
| Load Balancer | MetalLB | MetalLB |
| Ingress | ❌ | Ingress Nginx |
| Stockage | Rook-Ceph | Rook-Ceph |
| Déploiement Continu (GitOps) | ❌ | ArgoCD |
| Observabilité | ❌ | Prometheus, Grafana, Loki |
| Sauvegarde et Migration | ❌ | Veeam Kasten |
| Gestion des Coûts (FinOps) | ❌ | OpenCost |
| Gouvernance et Sécurité | ❌ | Kyverno, Capsule |
| Container Registry | ❌ | Harbor |
| Gestion des certificats | ❌ | Cert-Manager |
| Authentification SSO | ❌ | Intégration OIDC |
Présentation de le produit Managed Kubernetes (complète)
L'offre Managed Kubernetes (aussi appelée "Kub Managé", ou "KM") est une solution de containeurisation Kubernetes managée par Cloud-Temple déployée sous forme de Machines Virtuelles fonctionnant sur les infrastructures IaaS Cloud-Temple OpenIaaS.
Managed Kubernetes est basé sur Talos Linux (https://www.talos.dev/), un système d'exploitation dédié à Kubernetes qui est léger et sécurisé. Il est immuable, sans aucun shell ni accès ssh, et configuré uniquement de manière déclarative via API gRPC.
L'installation standardisée inclus un ensemble de composants, majoritairement OpenSource et validés par le CNCF:
-
CNI Cillium, avec interface d'observabilité (Hubble) : Cillium est une solution de mise en réseau pour les containers Kubernetes (Container Network Interface). Il gère la sécurité, le load balancing, le service mesh, l'observabilité, le chiffrement, etc... C'est un composant réseau fondamental que l'on retrouve dans la plupart des déclinaisons de Kubernetes (OpenShift, AKS, GKE, EKS,...). Nous avons inclus l'interface graphique Hubble pour une visualisation des flux Cillium.
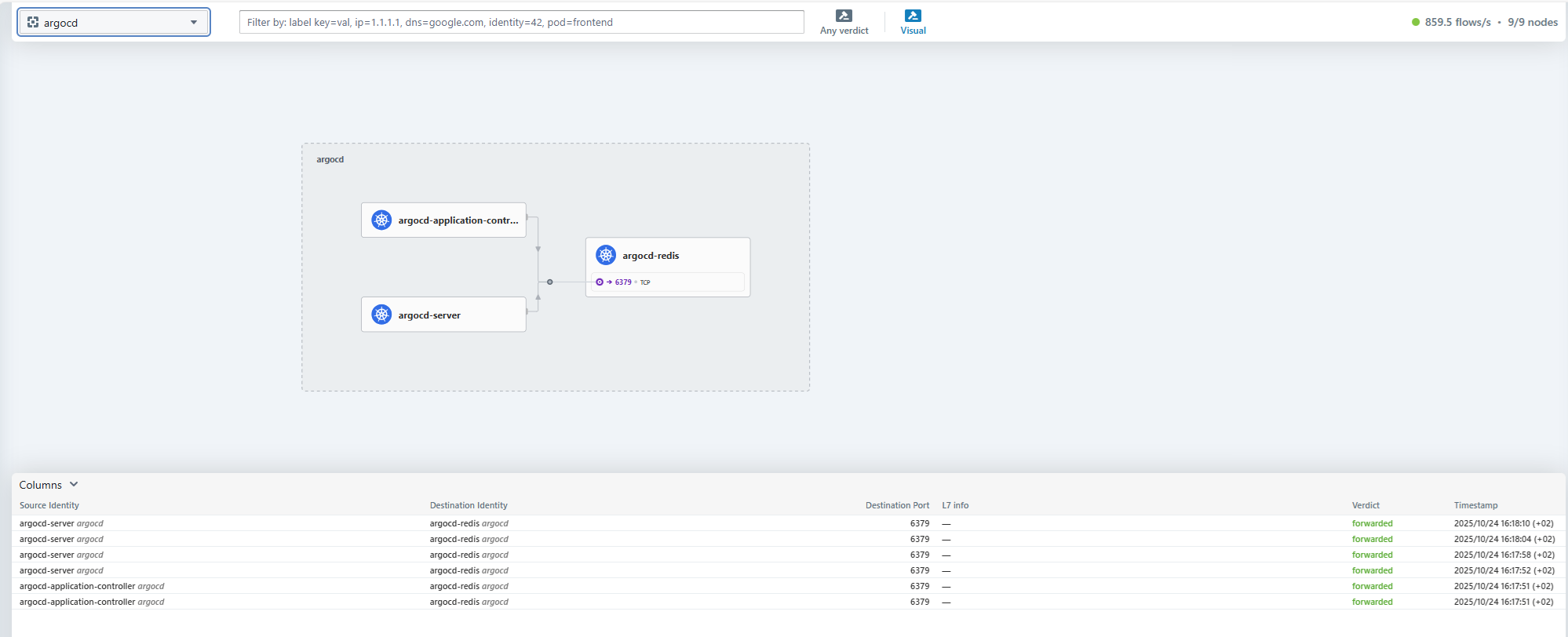
-
MetalLB et nginx : Pour l'exposition des applications Web, 3 ingress-class nginx sont intégrées de base:
-
nginx-external-secured : exposition sur une IP publique, filtrée sur le firewall pour n'autoriser que des IP connues (utilisé pour les interfaces graphiques des différents produits, et l'API Kubernetes)
-
nginx-external : exposition sur une seconde IP publique non filtrée (ou filtrage spécifique au client)
-
nginx-internal : exposition sur une IP interne uniquement
Pour les services "non web", un load-balancer metalLB permet d'exposer des services en interne ou sur des IP publiques. (ce qui permet de déployer des autres ingresses, comme par exemple un WAF)
-
-
Stockage distribué Rook-Ceph : pour le stockage des volumes persistents (PV), un stockage distribué Ceph OpenSource est intégré à la plateforme. Il permet d'utiliser les storage-classes ceph-block, ceph-bucket, et ceph-filesystem. Un stockage a 7500 IOPS est utilisé, permettant des performances élevées. Dans les déploiements de production (sur 3 AZ), les noeuds de stockage sont dédiés (1 noeud par AZ) ; dans les déploiements hors-production (1 AZ), le stockage est mutualisé avec les workers nodes.
-
Cert-Manager: le gestionnaire de certificats OpenSource Cert-Manager est intégré nativement dans la plateforme.
-
ArgoCD est à votre disposition pour vos déploiements automatisés via une chaine de CI/CD.
-
Stack Prometheus (Prometheus, Grafana, Loki): les clusters Managed kubernetes sont livrés en standard avec une stack OpenSource complète Prometheus pour l'observabilité, incluant:
-
Prometheus
-
Grafana, avec de nombreux dashboards
-
Loki : les journaux de la plateforme sont exportés vers le stockage S3 Cloud-Temple (et intégrés dans Grafana).
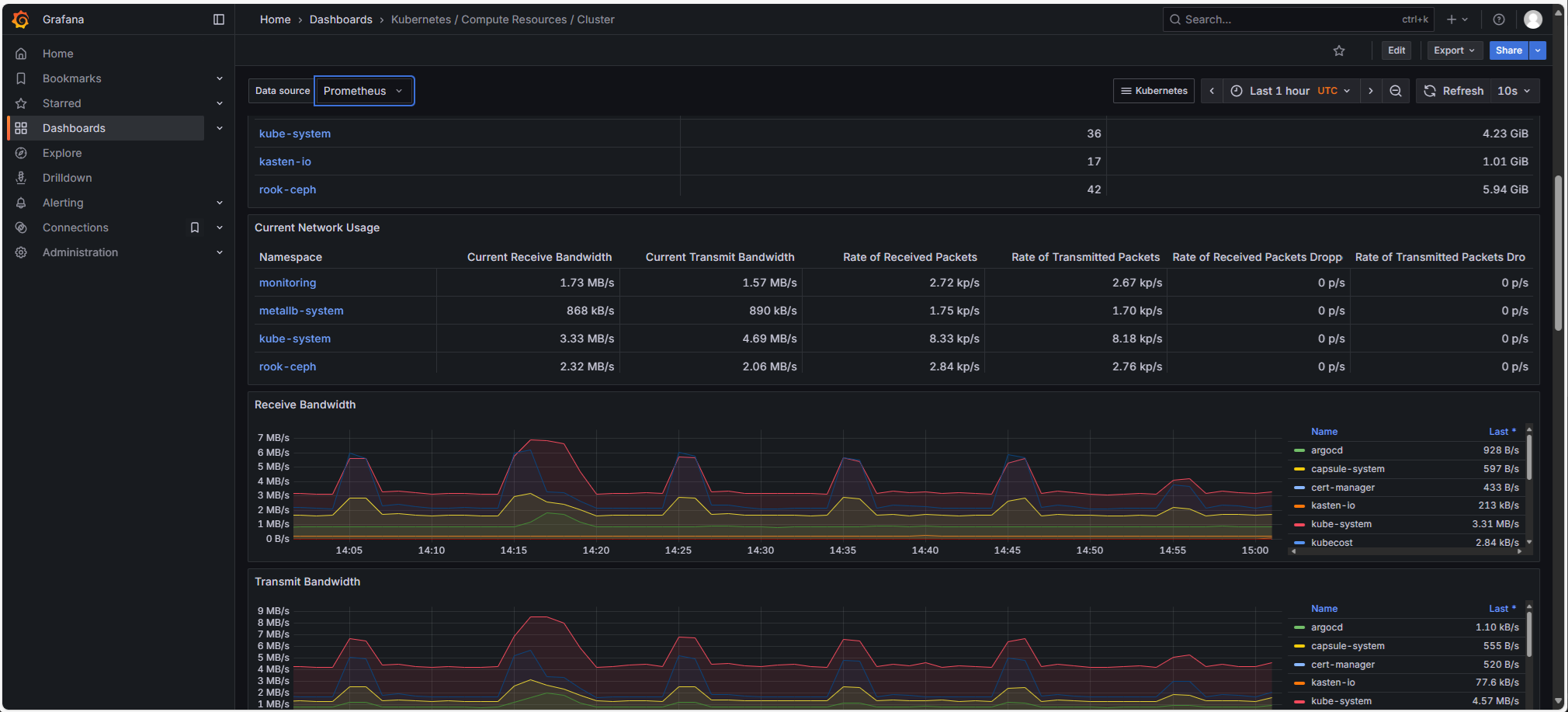
-
-
Harbor est une Container registry qui vous permet de stocker les images de vos containers ou vos charts helm directement dans le cluster. Elle effectue des scan de vulnérabilité sur vos images et peut les signer numériquement. Harbor permet aussi des synchronisations avec d'autres registries. (https://goharbor.io/)
-
OpenCost (https://github.com/opencost/opencost) est un outil de gestion des couts (Finops) pour kubernetes. Il vous permet de suivre finement la consommations des ressources kubernetes et de faire de la sous-facturation par projet/namespace.
-
Stratégies de sécurité avancée avec Kyverno et Capsule:
- Kyverno (https://kyverno.io/) est un controleur d'admission pour Kubernetes qui permet d'appliquer des stratégies. C'est un outil essentiel pour la gouvernance et la sécurité dans kubernetes.
- Capsule (https://projectcapsule.dev/) est un outil de gestion des permissions qui facilite la gestion des droits dans Kubernetes. Il introduit la notion de tenant qui permet de centraliser et déléguer des permissions sur plusieurs namespaces. Via Capsule, les utilisateurs de la plateforme Kubernetes Managé disposent donc de droits restreints à leurs seuls namespaces.
-
Veeam Kasten (aka 'k10') est une solution pour la sauvegarde des workloads Kubernetes.
Il permet de sauvegarder un déploiement complet : manifestes, volumes, etc... vers le stockage objet S3 Cloud-Temple. Kasten utilise Kanister pour permettre des sauvegardes applicatives cohérentes, par exemple pour les bases de données (https://docs.kasten.io/latest/usage/blueprints/).
Kasten est un outil cross-platform qui peut fonctionner avec d'autres clusters Kubernetes (OpenShift, Hyperscaler,...). Il peut donc être utilisé pour des scénarii de réversibilité ou de migration (K10 gère les adaptations éventuelles via des transformations, par exemple un changement d'ingress-class), mais aussi de "refresh" (exemple : restauration planifiée d'un environnement de production en pré-production).
-
Authentification SSO avec un Identity Provider Externe OIDC (Microsoft Entra, FranceConnect, Okta, AWS IAM, Google, Salesforce, ...)
SLA & Information sur le support
- Disponibilité garantie (production 3 AZ) : 99.95 %
- Support : N1/N2/N3 inclus pour le périmètre socle (infrastructure et opérateurs standards).
- Engagement de temps de rétablissement (ETR) : selon contrat cadre Cloud Temple.
- Maintenance (MCO) : patching régulier Talos / Kubernetes / opérateurs standards par MSP, sans interruption de service (rolling upgrade).
Les délais de prise en charge et de rétablissement dépendent de la sévérité de l’incident, conformément à la grille de support (P1 à P4).
Politique de versions & cycle de vie
- Kubernetes supporté : N-2 (3 releases majeures par an, environ tous les 4 mois). Chaque release est supportée officiellement 12 mois, ce qui assure une fenêtre de support Cloud Temple de ~16 mois maximum par version.
- Talos OS : aligné sur les versions stables de Kubernetes.
- Chaque branche est maintenue environ 12 mois (patchs sécurité inclus).
- Rythme d’upgrade recommandé : 3 fois par an, en cohérence avec les upgrades Kubernetes.
- Les patchs critiques (CVE, kernel) sont appliqués en rolling upgrade, sans interruption de service.
- Opérateurs standards : mis à jour dans les 90 jours suivant release stable.
- Mises à jour :
- Majeures (Kubernetes N+1, Talos X+1) : planifiées 3 fois/an, en rolling update.
- Mineures : appliquées automatiquement dans un délai de 30 à 60 jours.
- Dépréciation : version N-3 → fin de support sous 90 jours après sortie de N.
Noeuds Kubernetes
Production (multi-zonal)
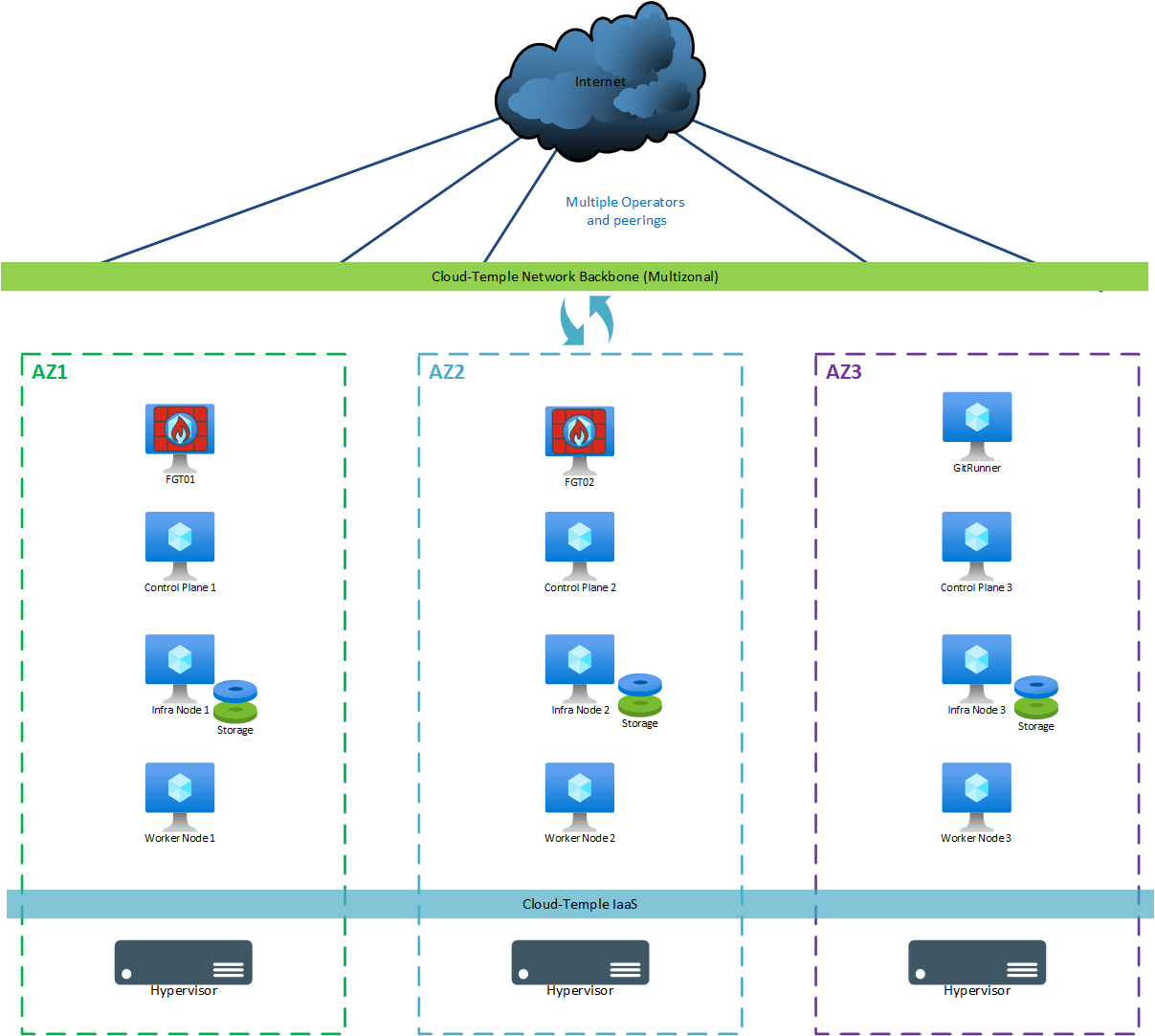
Pour un déploiement "de production" (multi-zonal), les machines suivantes sont utilisées:
| AZ | Machine | vCores | RAM | Stockage local |
|---|---|---|---|---|
| AZ07 | Git Runner | 4 | 8 Go | OS: 256 Go |
| AZ05 | Control Plane 1 | 8 | 12 Go | OS: 128 Go |
| AZ06 | Control Plane 2 | 8 | 12 Go | OS: 128 Go |
| AZ07 | Control Plane 3 | 8 | 12 Go | OS: 128 Go |
| AZ05 | Storage Node 1 | 12 | 24 Go | OS: 128 Go + Ceph 500 Go minimum (*) |
| AZ06 | Storage Node 2 | 12 | 24 Go | OS: 128 Go + Ceph 500 Go minimum (*) |
| AZ07 | Storage Node 3 | 12 | 24 Go | OS: 128 Go + Ceph 500 Go minimum (*) |
| AZ05 | Worker Node 1 (**) | 12 | 24 Go | OS: 128 Go |
| AZ06 | Worker Node 2 (**) | 12 | 24 Go | OS: 128 Go |
| AZ07 | Worker Node 3 (**) | 12 | 24 Go | OS: 128 Go |
(*) : Chaque noeud de stockage est livré avec un minimum de 500 Go d'espace disque, pour un stockage utile Ceph distribué de 500 Go (les données sont répliquées sur chaque AZ, donc x3). L'espace libre disponible pour le client est d'environ 350 Go. Cette taille initiale peut être augmentée au moment de la construction, ou plus tard, en fonction des besoins. Des quotas sont appliqués sur Ceph, avec une répartition Block/File.
(**) : La taille et le nombre des Worker Nodes peut être adaptée en fonction du besoin en capacité de calcul du client. Le nombre minimal de Worker nodes est de 3 (1 par AZ), et nous conseillons d'augmenter leur nombre par lot de 3 pour conserver une distribution multi zonale cohérente. La taille des Worker Node peut être adaptée, avec un minimum de 12 cores et 24 Go de RAM ; la limite supérieure par Worker node est fixée par la taille des hyperviseurs utilisés (donc potentiellement 112 cores/1536 Go de RAM avec des lames Performance 3). La quantité de Worker Nodes est limitée à 100. Le CNCF conseille d'avoir des worker nodes de taille identique. La limite du nombre de pods par Worker Node est de 110.
Dev/Test
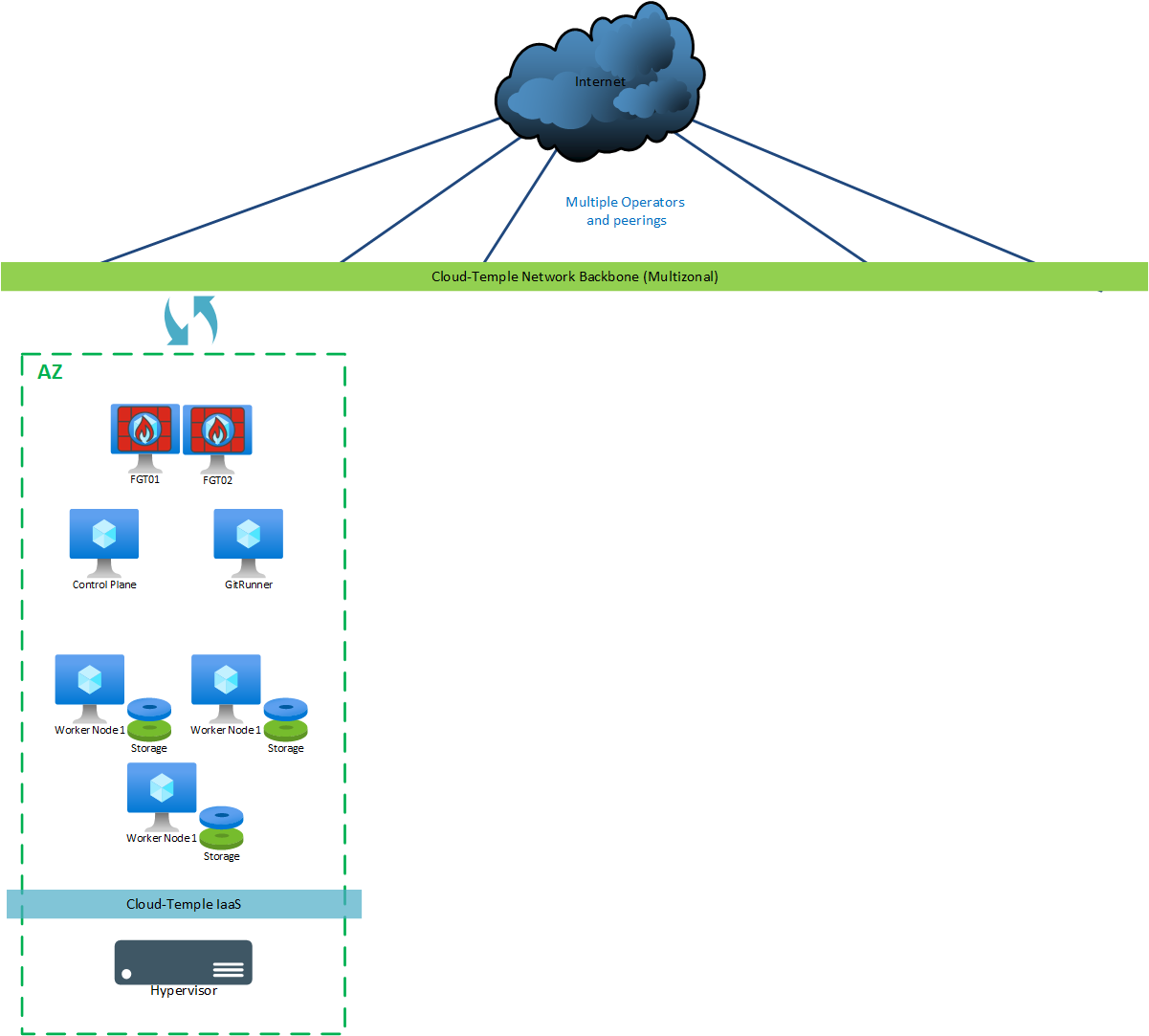
Pour une version "dev/test", les machines suivantes sont déployées:
| AZ | Machine | vCores | RAM | Stockage local |
|---|---|---|---|---|
| AZ0n | Git Runner | 4 | 8 Go | OS: 30 Go |
| AZ0n | Control Plane | 8 | 12 Go | OS: 128 Go |
| AZ0n | Worker Node 1 (**) | 12 | 24 Go | OS: 128 Go + Ceph 300 Go minimum (*) |
| AZ0n | Worker Node 2 (**) | 12 | 24 Go | OS: 128 Go + Ceph 300 Go minimum (*) |
| AZ0n | Worker Node 3 (**) | 12 | 24 Go | OS: 128 Go + Ceph 300 Go minimum (*) |
(*) : 3 Worker nodes sont utilisés comme Storage nodes et sont livrés avec un minimum de 300 Go d'espace disque, pour un stockage utile distribué de 300 Go (les données sont répliquées trois fois). L'espace libre disponible pour le client est d'environ 150 Go. Cette taille initiale peut être augmentée au moment de la construction, ou plus tard, en fonction des besoins.
(**) : La taille et le nombre des Worker Nodes peut être adaptée en fonction du besoin en capacité de calcul du client. Le nombre minimal de Worker nodes est de 3 (du fait de la réplication du stockage). La taille des Worker Node peut être adaptée, avec un minimum de 12 cores et 24 Go de RAM ; la limite supérieure par Worker node est fixée par la taille des hyperviseurs utilisés (donc potentiellement 112 cores/1536 Go de RAM avec des lames Performance 3). La quantité de Worker Nodes est limitée à 250. Le CNCF conseille d'avoir des worker nodes de taille identique. La limite du nombre de pods par Worker Node est de 110.
RACI
Architecture & Infrastructure
| Activité | Client | Cloud Temple |
|---|---|---|
| Définir l'architecture globale du service Kubernetes | C | RA |
| Dimensionner le service Kubernetes (nombre de noeuds, ressources) | C | RA |
| Installer le service Kubernetes avec une configuration par défaut | I | RA |
| Configuration du service Kubernetes | C | RA |
| Configurer le réseau de base du service Kubernetes | I | RA |
| Déploiement de la configuration initiale des identités et des accès | C | RA |
| Définir la stratégie de mise à l’échelle et de haute disponibilité | C | RA |
Gestion des projets et applications métiers
| Activité | Client | Cloud Temple |
|---|---|---|
| Créer et gérer les projets Kubernetes | RA | I* |
| Déployer et gérer les applications dans Kubernetes | RA | I* |
| Configurer les pipelines CI/CD | RA | I* |
| Gérer les images de conteneurs et les registres | RA | I* |
*peut passer à "C" en fonction du contrat d'infogérance
Surveillance et performance
| Activité | Client | Cloud Temple |
|---|---|---|
| Surveiller la performance du service Kubernetes | I | RA* |
| Surveiller la performance des applications | RA | |
| Gérer les alertes liées au service Kubernetes | I | RA* |
| Gérer les alertes liées aux applications | RA |
(*) : Cluster de Production seulement. En Dev/Test le client est entièrement en autonomie et en responsabilité.
Maintenance et mises à jour Infrastructures
| Activité | Client | Cloud Temple |
|---|---|---|
| Mettre à jour le service Kubernetes/OS | C | RA |
| Appliquer les correctifs de sécurité à Kubernetes | C | RA |
| Mettre à jour les applications déployées (opérateurs*) | C | RA |
*Package opérateur inclus sur Managed Kube - voir chapitres : Packages Helm managés
Sécurité
| Activité | Client | Cloud Temple |
|---|---|---|
| Gérer la sécurité du service Kubernetes | RA | RA* |
| Configurer et gérer les politiques de sécurité des pods | RA | I |
| Gérer les certificats SSL/TLS pour le service Kubernetes | C | RA* |
| Gérer les certificats SSL/TLS pour les applications | RA | I |
| Implémenter et gérer le contrôle d'accès basé sur les rôles de base (RBAC) | C | R* |
| Implémenter et gérer le contrôle d'accès basé sur les rôles client (RBAC) | RA | I |
(*) : Cluster de Production seulement. En Dev/Test le client est entièrement en autonomie et en responsabilité.
Sauvegarde et reprise après sinistre
| Activité | Client | Cloud Temple |
|---|---|---|
| Définir la stratégie de sauvegarde pour le service Kubernetes | I | RA |
| Mettre en oeuvre et gérer les sauvegardes du service Kubernetes | I | RA |
| Définir la stratégie de sauvegarde pour les applications | RA* | I* |
| Mettre en oeuvre et gérer les sauvegardes des applications | RA* | I* |
| Tester les procédures de reprise après sinistre pour le service Kubernetes | CI | RA |
| Tester les procédures de reprise après sinistre pour les applications | RA* | CI* |
*peut passer à "CI | RA" en fonction du contrat d'infogérance
Support et résolution des problèmes
| Activité | Client | Cloud Temple |
|---|---|---|
| Fournir un support de niveau 1 pour l'infrastructure | I | RA |
| Fournir un support de niveau 2 et 3 pour l'infrastructure | I | RA |
| Résoudre les problèmes liés au service Kubernetes | C | RA |
| Résoudre les problèmes liés aux applications | RA | I |
Gestion des capacités et évolution
Cluster de Production seulement. En Dev/Test le client est entièrement en autonomie et en responsabilité.
| Activité | Client | Cloud Temple |
|---|---|---|
| Surveiller l'utilisation des ressources Kubernetes | C | RA |
| Planifier l’évolution des capacités du service | RA | C |
| Implémenter les changements de capacité | I | RA |
| Gérer l’évolution des applications et leurs ressources | RA | I |
Documentation et conformité
| Activité | Client | Cloud Temple |
|---|---|---|
| Maintenir la documentation du produit Kubernetes | I | RA |
| Maintenir la documentation des applications | RA | I |
| Assurer la conformité du service Kubernetes | I | RA |
| Assurer la conformité des applications | RA | I |
| Réaliser des audits du service Kubernetes | I | RA |
| Réaliser des audits des applications | RA | I |
Gestion des opérateurs/CRD Kubernetes (inclus dans le produit)
| Activité | Client | Cloud Temple |
|---|---|---|
| Mise à disposition du catalogue d'Opérateurs par défaut | CI | RA |
| Mise à jour des Opérateurs | CI | RA |
| Surveillance de l’état des Opérateurs | CI | RA |
| Résolution des problèmes liés aux Opérateurs | CI | RA |
| Gestion des autorisations des Opérateurs | CI | RA |
| Gestion des ressources des Opérateurs (ajout/suppression) | CI | RA |
| Sauvegarde des données des ressources des Opérateurs | CI | RA |
| Supervision des ressources Opérateurs | CI | RA |
| Restauration des données des ressources des Opérateurs | CI | RA |
| Audit de sécurité des Opérateurs | CI | RA |
| Support des Opérateurs | CI | RA |
| Gestion des licences sur les opérateurs | CI | RA |
| Gestion des plans de support spécifiques sur les opérateurs | CI | RA |
*Package opérateur inclus sur Managed Kube - voir chapitres : Packages Helm managés
Gestion des applications/opérateurs/CRD Kubernetes (du client)
Cluster de Production seulement. En Dev/Test le client est entièrement en autonomie et en responsabilité.
| Activité | Client | Cloud Temple |
|---|---|---|
| Déploiement des CRDs | I* | RA* |
| Mise à jour des Opérateurs | RA | I |
| Surveillance de l’état des Opérateurs | RA | I |
| Résolution des problèmes liés aux Opérateurs | RA | I |
| Gestion des autorisations des Opérateurs | RA | I |
| Gestion des ressources des Opérateurs (ajout/suppression) | RA | I |
| Sauvegarde des données des ressources des Opérateurs | RA | I |
| Supervision des ressources Opérateurs | RA | I |
| Restauration des données des ressources des Opérateurs | RA | I |
| Audit de sécurité des Opérateurs | RA | I |
| Support des Opérateurs | RA | I |
| Gestion des licences sur les opérateurs | RA | I |
| Gestion des plans de support spécifiques sur les opérateurs | RA | I |
Certains services opérateurs peuvent être pris en charge en fonction du contrat d'infogérance.
*peut passer à "A | RC" en fonction du contrat d'infogérance
Assistance applicative
| Activité | Client | Cloud Temple |
|---|---|---|
| Assistance applicative (prestation externe) | RA | I |
Un support applicatif peut être fourni via une prestation complémentaire.
RACI (synthétique)
- Cloud Temple : responsable et acteur (RA) du socle Kubernetes, sécurité cluster, sauvegarde infra, supervision, CRD.
- Client : responsable et acteur (RA) des projets applicatifs, opérateurs métiers, pipelines CI/CD, sauvegardes applicatives.
- Zone "grise" : adaptations et extensions (IAM, opérateurs spécifiques, durcissement de conformité/sécurité du cluster) - facturées en mode projet.