Guide : Maîtriser l'OCR avec DeepSeek
Ce guide détaille l'utilisation du modèle DeepSeek-OCR, une solution de pointe pour la compression optique de contexte et l'analyse de documents.
Architecture et fonctionnement
Contrairement aux OCR traditionnels, DeepSeek-OCR est un modèle Vision-Langage de bout en bout conçu pour "lire" et "comprendre" visuellement les documents.
Architecture technique
Il combine deux composants innovants :
- DeepEncoder (380M) : Un encodeur visuel hybride qui combine SAM-base (pour la perception locale) et CLIP-large (pour la connaissance globale), reliés par un compresseur convolutif 16x. Cela permet de traiter des images haute résolution avec très peu de tokens visuels.
- Décodeur MoE (3B) : Basé sur DeepSeek3B-MoE (570M paramètres actifs), il génère le texte structuré à partir des tokens visuels compressés.
Modes de résolution et consommation
Le modèle adapte sa consommation de tokens à la résolution de l'image. Plus l'image est grande, plus elle consomme de tokens, mais meilleure est la précision.
| Mode | Résolution (px) | Vision Tokens | Usage Recommandé |
|---|---|---|---|
| Tiny | 512 x 512 | 64 | Slides, texte très gros |
| Small | 640 x 640 | 100 | Documents simples, tickets |
| Base | 1024 x 1024 | 256 | Pages A4 standards |
| Large | 1280 x 1280 | 400 | Documents denses, petits caractères |
| Gundam | Dynamique | ~800 | Journaux, plans, scans complexes |
:::tip Optimisation Pour optimiser vos coûts et la latence, redimensionnez vos images à la résolution minimale nécessaire pour que le texte reste lisible. :::
Support multilingue
Le modèle a été entraîné sur un vaste corpus de documents multilingues et supporte la reconnaissance de près de 100 langues (dont le français, l'anglais, le chinois, l'arabe, etc.), avec ou sans préservation de la mise en page.
Guide des prompts (Prompt engineering)
La qualité du résultat dépend directement du prompt utilisé. DeepSeek-OCR réagit à des instructions spécifiques pour activer ses différentes capacités.
1. OCR standard (Markdown)
Pour extraire le texte avec sa structure (titres, paragraphes, tableaux).
Prompt :
Convert the document to markdown.
Résultat : Texte structuré, tableaux formatés, mise en page préservée.
2. "Deep parsing" (Figures, graphiques, formules)
Pour analyser le contenu sémantique de graphiques, de formules chimiques ou géométriques.
Prompt :
Parse the figure.
Capacités :
- Graphiques (Bar/Line/Pie) : Convertit en table HTML ou Markdown.
- Formules Chimiques : Convertit en format SMILES.
- Géométrie : Décrit les éléments géométriques.
3. Grounding (localisation)
Pour trouver les coordonnées d'un élément spécifique dans l'image.
Prompt :
Locate <|ref|>élément à trouver<|/ref|> in the image.
Exemple : Locate <|ref|>Total<|/ref|> in the image.
Résultat : Retourne les coordonnées de la boîte englobante (bounding box) de l'élément.
4. Détection d'objets
Pour lister et localiser tous les objets visibles.
Prompt :
Identify all objects in the image and output them in bounding boxes.
Tutoriel d'implémentation (Python)
Voici un exemple complet montrant comment structurer votre appel API pour utiliser ces capacités.
Prérequis : format de l'image et dépendances
- Format : JPEG ou PNG.
- Mode : RGB (pas de transparence Alpha).
- PDF : Doivent être convertis en images au préalable (150-300 DPI).
- Taille : Il est recommandé de redimensionner les images très haute résolution pour éviter les erreurs de limite de taille (413 Payload Too Large).
Installez les librairies nécessaires :
pip install requests Pillow
Code : analyse de document (OCR)
Prenons l'exemple de ce ticket de caisse suisse :

Voici un script robuste qui gère le redimensionnement et l'encodage optimal de l'image :
import base64
import io
import requests
from PIL import Image
# Configuration
API_KEY = "VOTRE_TOKEN_API"
API_URL = "https://api.ai.cloud-temple.com/v1/chat/completions"
IMAGE_PATH = "ReceiptSwiss.jpg" # Assurez-vous que l'image est dans le dossier courant
def encode_image_optimized(path):
"""
Optimise l'image (redimensionnement + compression JPEG) pour l'API.
"""
with Image.open(path) as img:
# 1. Conversion RGB (pour éviter problèmes PNG/Alpha)
if img.mode != 'RGB':
img = img.convert('RGB')
# 2. Redimensionnement intelligent si trop grand (> 2048px)
# Cela évite l'erreur 413 (Payload Too Large) et accélère le traitement
max_size = 2048
if max(img.size) > max_size:
img.thumbnail((max_size, max_size))
# 3. Compression JPEG en mémoire
buffer = io.BytesIO()
img.save(buffer, format="JPEG", quality=85)
return base64.b64encode(buffer.getvalue()).decode('utf-8')
# 1. Construction du message multimodal
encoded_image = encode_image_optimized(IMAGE_PATH)
payload = {
"model": "deepseek-ai/DeepSeek-OCR",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Convert the document to markdown." # Prompt OCR Standard
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
}
}
]
}
],
"temperature": 0.0, # CRUCIAL : 0.0 pour la fidélité
"max_tokens": 4096
}
# 2. Envoi
print("Envoi de la requête...")
response = requests.post(
API_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json=payload
)
# 3. Résultat
if response.status_code == 200:
print("\n--- Résultat OCR ---\n")
print(response.json()['choices'][0]['message']['content'])
else:
print(f"Erreur {response.status_code}: {response.text}")
Exemple de sortie :
# Berghotel
**Grosse Scheidegg**
3818 Grindelwald
Familie R. Müller
Rech. Nr. 4572
Bar Tisch 7/01
2xLatte Macchiato à 4.50 CHF 9.00
1xGloki à 5.00 CHF 5.00
...
**Total :** CHF **54.50**
**Incl. 7.6% MwSt** 54.50 CHF: 3.85
Code : analyse de graphique (deep parsing)
Pour analyser un graphique financier dans un rapport, changez simplement le texte du prompt dans le payload ci-dessus :
# ... dans le payload ...
"text": "Parse the figure."
# ...
Le modèle retournera une représentation textuelle ou tabulaire des données du graphique.
Cas d'usage avancés
Extraction de tableaux complexes
DeepSeek-OCR excelle dans la conversion de tableaux, même sans lignes de démarcation claires.
Image Entrée :
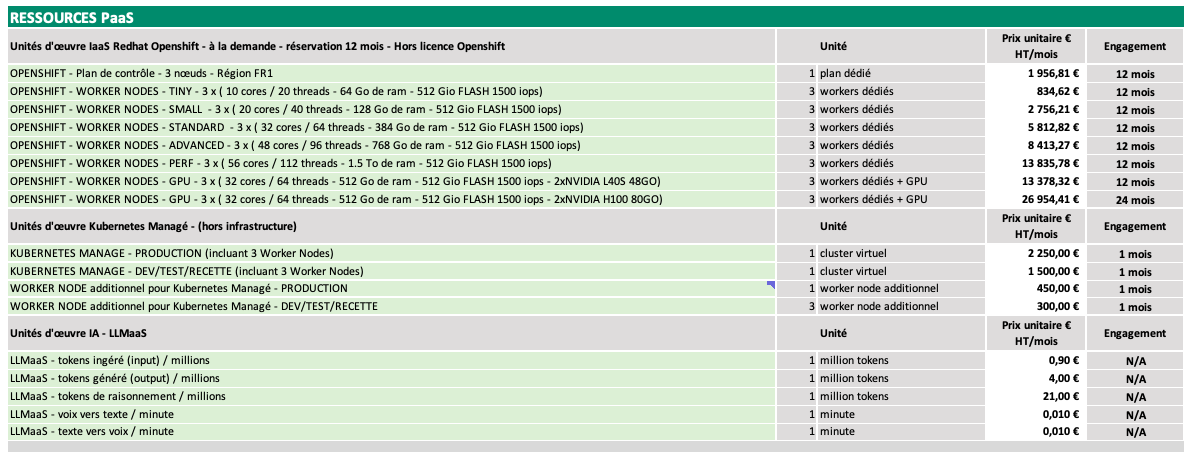
Sortie Modèle (Prompt: "Convert the document to markdown table.") :
# RESSOURCES PaaS
## Unités d'œuvre laaS Redhat Openshift - à la demande - réservation 12 mois - Hors licence Openshift
| | Unité | Prix unitaire € HT/mois | Engagement |
|---|---|---|---|
| OPENSHIFT - Plan de contrôle - 3 nœuds - Région FR1 | 1 plan dédié | 1 956,81 € | 12 mois |
| OPENSHIFT - WORKER NODES - TINY - 3 x (10 cores / 20 threads - 64 Go de ram - 512 Gio FLASH 1500 ips) | 3 workers dédiés | 834,62 € | 12 mois |
| OPENSHIFT - WORKER NODES - SMALL - 3 x (20 cores / 40 threads - 128 Go de ram - 512 Gio FLASH 1500 ips) | 3 workers dédiés | 2 756,21 € | 12 mois |
| OPENSHIFT - WORKER NODES - STANDARD - 3 x (32 cores / 64 threads - 384 Go de ram - 512 Gio FLASH 1500 ips) | 3 workers dédiés | 5 812,82 € | 12 mois |
| OPENSHIFT - WORKER NODES - ADVANCED - 3 x (48 cores / 96 threads - 768 Go de ram - 512 Gio FLASH 1500 ips) | 3 workers dédiés | 8 413,27 € | 12 mois |
| OPENSHIFT - WORKER NODES - PERF - 3 x (56 cores / 112 threads - 1.5 To de ram - 512 Gio FLASH 1500 ips) | 3 workers dédiés | 13 835,78 € | 12 mois |
| OPENSHIFT - WORKER NODES - GPU - 3 x (32 cores / 64 threads - 512 Go de ram - 512 Gio FLASH 1500 ips - 2xNVIDIA L40S 48GO) | 3 workers dédiés + GPU | 13 378,32 € | 12 mois |
| OPENSHIFT - WORKER NODES - GPU - 3 x (32 cores / 64 threads - 512 Go de ram - 512 Gio FLASH 1500 ips - 2xNVIDIA H100 80GO) | 3 workers dédiés + GPU | 26 954,41 € | 24 mois |
---
## Unités d'œuvre Kubernetes Manage - (hors infrastructure)
| | Unité | Prix unitaire € HT/mois | Engagement |
|---|---|---|---|
| KUBERNETES MANAGE - PRODUCTION (incluant 3 Worker Nodes) | 1 cluster virtuel | 2 250,00 € | 1 mois |
| KUBERNETES MANAGE - DEV/TEST/RECETTE (incluant 3 Worker Nodes) | 1 cluster virtuel | 1 500,00 € | 1 mois |
| WORKER NODE additionnel pour Kubernetes Manage - PRODUCTION | 1 worker node additionnel | 450,00 € | 1 mois |
| WORKER NODE additionnel pour Kubernetes Manage - DEV/TEST/RECETTE | 3 worker node additionnel | 300,00 € | 1 mois |
---
## Unités d'œuvre IA - LLMaas
| | Unité | Prix unitaire € HT/mois | Engagement |
|---|---|---|---|
| LLMaas - tokens ingéré (input) / millions | 1 million tokens | 0,90 € | N/A |
| LLMaas - tokens généré (output) / millions | 1 million tokens | 4,00 € | N/A |
| LLMaas - tokens de raisonnement / millions | 1 million tokens | 21,00 € | N/A |
| LLMaas - voix vers texte / minute | 1 minute | 0,010 € | N/A |
| LLMaas - texte vers voix / minute | 1 minute | 0,010 € | N/A |
Formules mathématiques (LaTeX)
Idéal pour les documents académiques. Le modèle reconnaît les équations et les sort en syntaxe LaTeX standard.
Image Entrée :

Sortie Modèle (Prompt: "Convert to latex.") :
Voici le rendu mathématique du résultat OCR :
Mean square error:
Condition for minimum of in:
(2n+1) equations:
Limitations connues
- Orientation : Le modèle ne gère pas la rotation automatique. Assurez-vous que vos images sont bien orientées (texte horizontal).
- Texte manuscrit : Bien que performant, le taux d'erreur est plus élevé sur l'écriture manuscrite cursive complexe que sur le texte imprimé.
- Très haute résolution : Les images dépassant les dimensions du mode "Gundam" (~2000x2000) sont redimensionnées, ce qui peut rendre illisible le texte microscopique. Découpez les très grands plans en plusieurs images.