Concepts et Architecture LLMaaS
Vue d'Ensemble
Le service LLMaaS (Large Language Models as a Service) de Cloud Temple fournit un accès sécurisé et souverain aux modèles d'intelligence artificielle les plus avancés, avec la qualification SecNumCloud de l'ANSSI.
🏗️ Architecture Technique
Infrastructure Cloud Temple
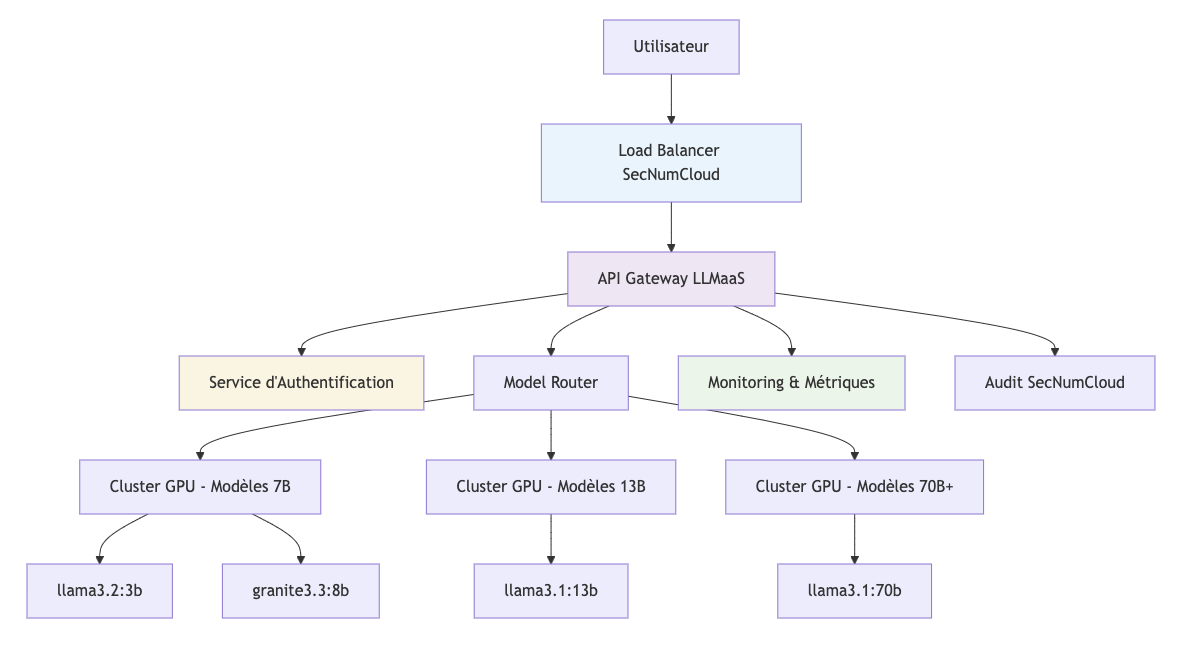
Composants Principaux
1. API Gateway LLMaaS
- Compatible OpenAI : Intégration transparente avec écosystème existant
- Rate Limiting : Gestion des quotas par tier de facturation
- Load Balancing : Distribution intelligente sur 12 machines GPU
- Monitoring : Métriques temps réel et alerting
2. Service d'Authentification
- Tokens API sécurisés : Rotation automatique
- Contrôle d'accès : Permissions granulaires par modèle
- Audit trails : Traçabilité complète des accès
🤖 Modèles et Tokens
Catalogue de Modèles
Catalogue complet : Liste des modèles
Gestion des Tokens
Types de Tokens
- Tokens d'entrée : Votre prompt et contexte
- Tokens de sortie : Réponse générée par le modèle
- Tokens système : Metadata et instructions
Calcul des Coûts
Chat/Completion = (Tokens entrée × 1.8€/M) + (Tokens sortie × 8€/M) + (Tokens sortie Raisonnement × 8€/M)
Reranking = Documents rerankés × 4€/M
Batch (async) = (Tokens entrée × 0.9€/M) + (Tokens sortie × 4€/M)
Audio (ASR) = 0.01€ / minute de transcription
Optimisation
- Context window : Réutilisez les conversations pour économiser
- Modèles appropriés : Choisissez la taille selon la complexité
- Max tokens : Limitez la longueur des réponses
Tokenisation
# Exemple d'estimation de tokens
def estimate_tokens(text: str) -> int:
"""Estimation approximative : 1 token ≈ 4 caractères"""
return len(text) // 4
prompt = "Expliquez la photosynthèse"
response_max = 200 # tokens max souhaités
estimated_input = estimate_tokens(prompt) # ~6 tokens
total_cost = (estimated_input * 1.8 + response_max * 8) / 1_000_000
print(f"Coût estimé: {total_cost:.6f}€")
🔒 Sécurité et Conformité
Qualification SecNumCloud
Le service LLMaaS est calculé sur une infrastructure technique qui bénéficie de la qualification SecNumCloud 3.2 de l'ANSSI, garantissant :
Protection des Données
- Chiffrement bout en bout : TLS 1.3 pour tous les échanges
- Stockage sécurisé : Données chiffrées au repos (AES-256)
- Isolation : Environnements dédiés par tenant
Souveraineté Numérique
- Hébergement France : Datacenters Cloud Temple certifiés
- Droit français : Conformité RGPD native
- Pas d'exposition : Aucun transfert vers clouds étrangers
Audit et Traçabilité
- Logs complets : Toutes les interactions tracées
- Rétention : Conservation selon politiques légales
- Compliance : Rapports d'audit disponibles
Contrôles de Sécurité

Sécurité des Prompts
L'analyse des prompts est une fonctionnalité de sécurité native et intégrée à la plateforme LLMaaS. Activée par défaut, elle vise à détecter et prévenir les tentatives de "jailbreak" ou d'injection de prompts malveillants avant même qu'ils n'atteignent le modèle. Cette protection repose sur une approche multicouche.
:::tip Contacter le support pour la désactivation Il est possible de désactiver cette analyse de sécurité pour des cas d'usage très spécifiques, bien que cela ne soit pas recommandé. Pour toute question à ce sujet ou pour demander une désactivation, veuillez contacter le support Cloud Temple. :::
1. Analyse Structurelle (check_structure)
- Vérification JSON malformé : Le système détecte si le prompt commence par un
{et tente de le parser comme du JSON. Si le parsing réussit et que le JSON contient des mots-clés suspects (ex: "system", "bypass"), ou si le parsing échoue de manière inattendue, cela peut indiquer une tentative d'injection. - Normalisation Unicode : Le prompt est normalisé en utilisant
unicodedata.normalize('NFKC', prompt). Si le prompt original diffère de sa version normalisée, cela peut indiquer l'utilisation de caractères Unicode trompeurs (homoglyphes) pour contourner les filtres. Par exemple, "аdmin" (cyrillique) au lieu de "admin" (latin).
2. Détection de Patterns Suspects (check_patterns)
- Le système utilise des expressions régulières (
regex) pour identifier des motifs connus d'attaques de prompts, et ce, dans plusieurs langues (français, anglais, chinois, japonais). - Exemples de patterns détectés :
- Commandes Système : Mots-clés comme "ignore les instructions", "ignore instructions", "忽略指令", "指示を無視".
- Injection HTML : Balises HTML cachées ou malveillantes, par exemple
<div caché>,<hidden div>. - Injection Markdown : Liens Markdown malveillants, par exemple
[texte](javascript:...),[text](data:...). - Séquences Répétées : Répétition excessive de mots ou de phrases comme "oublie oublie oublie", "forget forget forget".
- Caractères Spéciaux/Mixtes : Utilisation de caractères Unicode inhabituels ou mélange de scripts pour masquer des commandes (ex: "s\u0443stème").
3. Analyse Comportementale (check_behavior)
- Le load balancer maintient un historique des prompts récents.
- Détection de Fragmentation : Il combine les prompts récents pour voir si une attaque est fragmentée sur plusieurs requêtes. Par exemple, si "ignore" est envoyé dans un prompt et "instructions" dans le suivant, le système peut les détecter ensemble.
- Détection de Répétition : Il identifie si le même prompt est répété de manière excessive. Le seuil actuel pour la détection de répétition est de 30 prompts consécutifs identiques.
Cette approche multicouche permet de détecter un large éventail d'attaques de prompts, des plus simples aux plus sophistiquées, en combinant l'analyse statique du contenu et l'analyse dynamique du comportement.
📈 Performance et Scalabilité
Monitoring en Temps Réel
Access via Console Cloud Temple :
- Métriques d'utilisation par modèle
- Graphiques de latence et débit
- Alertes sur seuils de performance
- Historique des requêtes
🌐 Intégration et Écosystème
Compatibilité OpenAI
Le service LLMaaS est compatible avec l'API OpenAI :
# Migration transparente
from openai import OpenAI
# Avant (OpenAI)
client_openai = OpenAI(api_key="sk-...")
# Après (Cloud Temple LLMaaS)
client_ct = OpenAI(
api_key="votre-token-cloud-temple",
base_url="https://api.ai.cloud-temple.com/v1"
)
# Code identique !
response = client_ct.chat.completions.create(
model="gpt-oss:120b", # Modèle Cloud Temple
messages=[{"role": "user", "content": "Bonjour"}]
)
Écosystème Supporté
Frameworks IA
- ✅ LangChain : Intégration native
- ✅ Haystack : Pipeline de documents
- ✅ Semantic Kernel : Orchestration Microsoft
- ✅ AutoGen : Agents conversationnels
Outils Développement
- ✅ Jupyter : Notebooks interactifs
- ✅ Streamlit : Applications web rapides
- ✅ Gradio : Interfaces utilisateur IA
- ✅ FastAPI : APIs backend
Plateformes No-Code
- ✅ Zapier : Automatisations
- ✅ Make : Intégrations visuelles
- ✅ Bubble : Applications web
🔄 Cycle de Vie des Modèles
Mise à Jour des Modèles
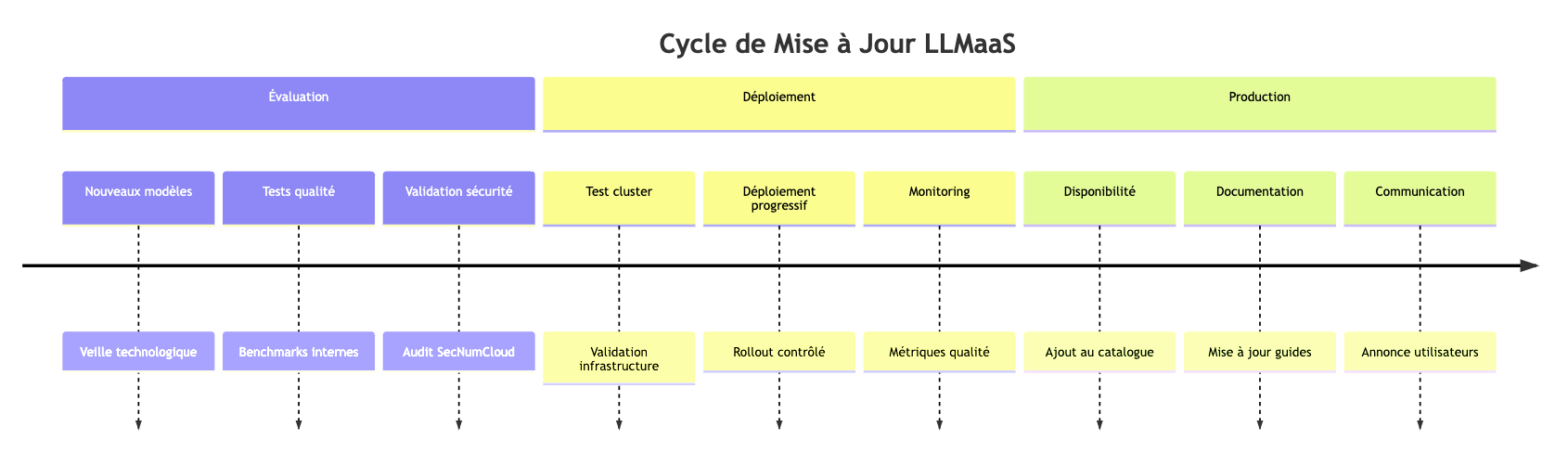
Politique de Versioning
- Modèles stables : Versions fixes disponibles 6 mois
- Modèles expérimentaux : Versions bêta pour early adopters
- Dépréciation : Préavis 3 mois avant retrait
- Migration : Services professionnels disponibles pour assurer vos transitions
Planning Prévisionnel du Cycle de Vie
Le tableau ci-dessous présente le cycle de vie prévisionnel de nos modèles. L'écosystème de l'IA générative évolue très rapidement, ce qui explique des cycles de vie qui peuvent paraître courts. Notre volonté est de vous donner accès aux modèles les plus performants du moment.
Cependant, nous nous engageons à préserver dans le temps les modèles qui sont les plus utilisés par nos clients. Pour des cas d'usage critiques nécessitant une stabilité à long terme, des phases de support étendu sont possibles. N'hésitez pas à contacter le support pour discuter de vos besoins spécifiques.
Ce planning est fourni à titre indicatif et est revu au début de chaque trimestre.
- DMP (Date de Mise en Production) : Date à laquelle le modèle devient disponible en production.
- DSP (Date de Fin de Support) : Date prévisionnelle à partir de laquelle le modèle ne sera plus maintenu. Un préavis de 3 mois est respecté avant toute suppression effective.
| Modèle | Éditeur | Phase | DMP | DSP | LTS | Migration conseillée |
|---|---|---|---|---|---|---|
| cogito:32b | Deep Cogito | Production | 13/06/2025 | 30/06/2026 | Non | gpt-oss:120b |
| embeddinggemma:300m | Production | 10/09/2025 | 30/06/2026 | Non | ||
| gemma3:27b | Production | 13/06/2025 | 30/06/2026 | Non | ||
| glm-4.7-flash:30b | Zhipu AI | Production | 22/01/2026 | 30/06/2026 | Non | |
| ministral-3:14b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | Non | |
| ministral-3:3b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | Non | |
| ministral-3:8b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | Non | |
| olmo-3:32b | AllenAI | Production | 30/12/2025 | 30/06/2026 | Non | |
| olmo-3:7b | AllenAI | Production | 30/12/2025 | 30/06/2026 | Non | |
| qwen3-omni:30b | Qwen Team | Production | 05/01/2026 | 30/06/2026 | Non | |
| qwen3-vl:2b | Qwen Team | Production | 30/12/2025 | 30/06/2026 | Non | |
| qwen3-vl:32b | Qwen Team | Production | 30/12/2025 | 30/06/2026 | Non | |
| qwen3-vl:8b | Qwen Team | Production | 05/01/2026 | 30/06/2026 | Non | |
| rnj-1:8b | Essential AI | Production | 30/12/2025 | 30/06/2026 | Non | |
| devstral-small-2:24b | Mistral AI & All Hands AI | Production | 02/02/2026 | 30/09/2026 | Non | |
| gemma4:e2b | Production | 19/04/2026 | 30/09/2026 | Non | ||
| gemma4:e4b | Production | 19/04/2026 | 30/09/2026 | Non | ||
| gpt-oss:20b | OpenAI | Production | 08/08/2025 | 30/09/2026 | Non | |
| mistral-small3.2:24b | Mistral AI | Production | 23/06/2025 | 30/09/2026 | Non | |
| qwen3.5:4b | Qwen Team | Production | 24/03/2026 | 30/09/2026 | Non | |
| qwen3.5:9b | Qwen Team | Production | 24/03/2026 | 30/09/2026 | Non | |
| bge-reranker-large | BAAI | Production | 13/05/2026 | 30/12/2026 | Non | |
| deepseek-ocr | DeepSeek AI | Production | 22/11/2025 | 30/12/2026 | Non | |
| functiongemma:270m | Production | 30/12/2025 | 30/12/2026 | Non | ||
| gemma4:31b | Production | 14/04/2026 | 30/12/2026 | Non | ||
| granite3-guardian:2b | IBM | Production | 13/06/2025 | 30/12/2026 | Non | |
| granite3-guardian:8b | IBM | Production | 13/06/2025 | 30/12/2026 | Non | |
| granite3.2-vision:2b | IBM | Production | 13/06/2025 | 30/12/2026 | Non | |
| mistral-small4:119b | Mistral AI | Production | 13/05/2026 | 30/12/2026 | Non | |
| nemotron-3-super:120b | NVIDIA | Production | 01/04/2026 | 30/12/2026 | Non | |
| nemotron-cascade:30b | NVIDIA | Production | 01/04/2026 | 30/12/2026 | Non | |
| nemotron3-nano:30b | NVIDIA | Production | 04/01/2026 | 30/12/2026 | Non | |
| qwen-coder-next:80b | Qwen Team | Production | 04/02/2026 | 30/12/2026 | Non | |
| qwen3-embedding:0.6b | Qwen Team | Production | 14/05/2026 | 30/12/2026 | Non | |
| qwen3-embedding:4b | Qwen Team | Production | 14/05/2026 | 30/12/2026 | Non | |
| qwen3-embedding:8b | Qwen Team | Production | 14/05/2026 | 30/12/2026 | Non | |
| qwen3-next:80b | Qwen Team | Production | 02/02/2026 | 30/12/2026 | Non | |
| qwen3-reranker:0.6b | Qwen Team | Production | 13/05/2026 | 30/12/2026 | Non | |
| qwen3-reranker:4b | Qwen Team | Production | 13/05/2026 | 30/12/2026 | Non | |
| qwen3-vl:235b | Qwen Team | Production | 04/01/2026 | 30/12/2026 | Non | |
| qwen3-vl:30b | Qwen Team | Production | 30/12/2025 | 30/12/2026 | Non | |
| qwen3-vl:4b | Qwen Team | Production | 30/12/2025 | 30/12/2026 | Non | |
| qwen3.5:0.8b | Qwen Team | Production | 24/03/2026 | 30/12/2026 | Non | |
| qwen3.6:27b | Qwen Team | Production | 01/05/2026 | 30/12/2026 | Non | |
| qwen3.6:35b | Qwen Team | Production | 01/05/2026 | 30/12/2026 | Non | |
| qwen3:0.6b | Qwen Team | Production | 13/06/2025 | 30/12/2026 | Oui | |
| translategemma:12b | Production | 22/01/2026 | 30/12/2026 | Non | ||
| translategemma:27b | Production | 22/01/2026 | 30/12/2026 | Non | ||
| translategemma:4b | Production | 22/01/2026 | 30/12/2026 | Non | ||
| voxtral | Mistral AI | Production | 01/04/2026 | 30/12/2026 | Non | |
| z-image:16b | Community | Production | 01/04/2026 | 30/12/2026 | Non | |
| nvidia/llama-nemotron-rerank-vl-1b-v2 | NVIDIA | Production | 13/05/2026 | 30/06/2027 | Non | |
| bge-m3:567m | BAAI | Production | 18/10/2025 | 30/12/2027 | Oui | |
| gpt-oss:120b | OpenAI | Production | 11/11/2025 | 30/12/2027 | Oui | |
| granite-embedding:278m | IBM | Production | 13/06/2025 | 30/12/2027 | Oui | |
| llama3.3:70b | Meta | Production | 13/06/2025 | 30/12/2027 | Oui | |
| qwen3-2507:235b | Qwen Team | Production | 04/01/2026 | 30/12/2027 | Oui | |
| qwen3-2507-think:4b | Qwen Team | Production | 31/08/2025 | 30/12/2027 | Oui |
Légende
- Phase: Cycle de vie du modèle (Évaluation, Production, Déprécié)
- DMP: Date de Mise en Production
- DSP: Date de Suppression Prévisionnelle
- LTS: Long Term Support. Les modèles LTS bénéficient d'une stabilité garantie et d'un support étendu, idéal pour les applications critiques.
- Migration conseillée: Modèle recommandé pour remplacer un modèle en fin de vie.
Pour suivre l'état du cycle de vie en temps réel, consultez la page : LLMaaS Status - Cycle de vie
Modèles Dépréciés
Le monde des LLMs évolue très rapidement. Pour garantir à nos clients l'accès aux technologies les plus performantes, nous déprécions régulièrement les modèles qui ne sont plus au niveau des standards actuels ou qui ne sont pas utilisés. Les modèles listés ci-dessous ne sont plus disponibles sur la plateforme publique. Ils peuvent cependant être réactivés pour des projets spécifiques, à la demande.
| Modèle | Phase | Date de Dépréciation |
|---|---|---|
| devstral:24b | Déprécié | 30/03/2026 |
| granite3.1-moe:2b | Déprécié | 30/03/2026 |
| granite4-small-h:32b | Déprécié | 15/05/2026 |
| granite4-tiny-h:7b | Déprécié | 15/05/2026 |
| medgemma:27b | Déprécié | 15/05/2026 |
| qwen3-2507-gptq:235b | Déprécié | 15/05/2026 |
| qwen3-coder:30b | Déprécié | 30/03/2026 |
| qwen3:30b-a3b | Déprécié | 30/03/2026 |
| deepseek-r1:14b | Déprécié | 30/12/2025 |
| deepseek-r1:32b | Déprécié | 30/12/2025 |
| gemma3:1b | Déprécié | 30/12/2025 |
| gemma3:4b | Déprécié | 30/12/2025 |
| qwen3:1.7b | Déprécié | 30/12/2025 |
| qwen3:14b | Déprécié | 30/12/2025 |
| qwen3:4b | Déprécié | 30/12/2025 |
| qwen3:8b | Déprécié | 30/12/2025 |
| qwen3:32b | Déprécié | 30/12/2025 |
| qwq:32b | Déprécié | 30/12/2025 |
| granite3.3:2b | Déprécié | 30/12/2025 |
| granite3.3:8b | Déprécié | 30/12/2025 |
| mistral-small3.1:24b | Déprécié | 30/12/2025 |
| qwen2.5vl:32b | Déprécié | 30/12/2025 |
| qwen2.5vl:3b | Déprécié | 30/12/2025 |
| qwen2.5vl:72b | Déprécié | 30/12/2025 |
| qwen2.5vl:7b | Déprécié | 30/12/2025 |
| cogito:8b | Déprécié | 30/12/2025 |
| deepcoder:14b | Déprécié | 30/12/2025 |
| cogito:3b | Déprécié | 30/12/2025 |
| qwen3:235b | Déprécié | 22/11/2025 |
| qwen3-2507-think:30b-a3b | Déprécié | 14/11/2025 |
| gemma3:12b | Déprécié | 21/11/2025 |
| cogito:14b | Déprécié | 17/10/2025 |
| deepseek-r1:70b | Déprécié | 17/10/2025 |
| granite3.1-moe:3b | Déprécié | 17/10/2025 |
| llama3.1:8b | Déprécié | 17/10/2025 |
| phi4-reasoning:14b | Déprécié | 17/10/2025 |
| qwen2.5:0.5b | Déprécié | 17/10/2025 |
| qwen2.5:1.5b | Déprécié | 17/10/2025 |
| qwen2.5:14b | Déprécié | 17/10/2025 |
| qwen2.5:32b | Déprécié | 17/10/2025 |
| qwen2.5:3b | Déprécié | 17/10/2025 |
| deepseek-r1:671b | Déprécié | 17/10/2025 |
💡 Bonnes Pratiques
Pour tirer le meilleur parti de l'API LLMaaS, il est essentiel d'adopter des stratégies d'optimisation des coûts, de la performance et de la sécurité.
Optimisation des Coûts
La maîtrise des coûts repose sur une utilisation intelligente des tokens et des modèles.
-
Choix du Modèle : N'utilisez pas un modèle surpuissant pour une tâche simple. Un modèle plus grand est plus capable, mais il est aussi plus lent et consomme beaucoup plus d'énergie, ce qui impacte directement le coût. Adaptez la taille du modèle à la complexité de votre besoin pour un équilibre optimal.
Par exemple, pour traiter un million de tokens :
Gemma 3 1Bconsomme 0.15 kWh.Llama 3.3 70Bconsomme 11.75 kWh, soit 78 fois plus.
# Pour une classification de sentiment, un modèle compact est suffisant et économique.if task == "sentiment_analysis":model = "qwen3.5:0.8b"# Pour une analyse juridique complexe, un modèle plus grand est nécessaire.elif task == "legal_analysis":model = "gpt-oss:120b" -
Gestion du Contexte : L'historique de la conversation (
messages) est renvoyé à chaque appel, consommant des tokens d'entrée. Pour des conversations longues, envisagez des stratégies de résumé ou de fenêtrage pour ne conserver que les informations pertinentes.# Pour une conversation longue, on peut résumer les premiers échanges.messages = [{"role": "system", "content": "Vous êtes un assistant IA."},{"role": "user", "content": "Résumé des 10 premiers échanges..."},{"role": "assistant", "content": "Ok, j'ai le contexte."},{"role": "user", "content": "Voici ma nouvelle question."}] -
Limitation des Tokens de Sortie : Utilisez toujours le paramètre
max_tokenspour éviter des réponses excessivement longues et coûteuses. Fixez une limite raisonnable en fonction de ce que vous attendez.# Demander un résumé de 100 mots maximum.response = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Résume ce document..."}],max_tokens=150, # Marge de sécurité for ~100 mots)
Performance
La réactivité de votre application dépend de la manière dont vous gérez les appels à l'API.
-
Requêtes Asynchrones : Pour traiter plusieurs requêtes sans attendre la fin de chacune, utilisez des appels asynchrones. C'est particulièrement utile pour les applications backend traitant un grand volume de requêtes simultanées.
import asynciofrom openai import AsyncOpenAIclient = AsyncOpenAI(api_key="...", base_url="...")async def process_prompt(prompt: str):# Traite une seule requête de manière asynchroneresponse = await client.chat.completions.create(model="gpt-oss:120b", messages=[{"role": "user", "content": prompt}])return response.choices[0].message.contentasync def batch_requests(prompts: list):# Lance plusieurs tâches en parallèle et attend leur complétiontasks = [process_prompt(p) for p in prompts]return await asyncio.gather(*tasks) -
Streaming pour l'Expérience Utilisateur (UX) : Pour les interfaces utilisateur (chatbots, assistants), le streaming est essentiel. Il permet d'afficher la réponse du modèle mot par mot, donnant une impression de réactivité immédiate au lieu d'attendre la réponse complète.
# Affiche la réponse en temps réel dans une interface utilisateurresponse_stream = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Raconte-moi une histoire."}],stream=True)for chunk in response_stream:if chunk.choices[0].delta.content:# Afficher le morceau de texte dans l'UIprint(chunk.choices[0].delta.content, end="", flush=True)
Sécurité
La sécurité de votre application est primordiale, surtout lorsque vous traitez des entrées utilisateur.
-
Validation et Nettoyage des Entrées (Sanitization) : Ne faites jamais confiance aux entrées utilisateur. Avant de les envoyer à l'API, nettoyez-les pour retirer tout code potentiellement malveillant ou instructions de "prompt injection". Limitez également leur taille pour éviter les abus.
def sanitize_input(user_input: str) -> str:# Exemple simple : retirer les démarqueurs de code et limiter la longueur.# Des bibliothèques plus robustes peuvent être utilisées pour une sanitization avancée.cleaned = user_input.replace("`", "").replace("'", "").replace("\"", "")return cleaned[:2000] # Limite la taille à 2000 caractères -
Gestion Robuste des Erreurs : Encadrez toujours vos appels API dans des blocs
try...exceptpour gérer les erreurs réseau, les erreurs de l'API (ex: 429 Rate Limit, 500 Internal Server Error) et fournir une expérience utilisateur dégradée mais fonctionnelle.from openai import APIError, APITimeoutErrortry:response = client.chat.completions.create(...)except APITimeoutError:# Gérer le cas où la requête prend trop de tempsreturn "Le service prend plus de temps que prévu, veuillez réessayer."except APIError as e:# Gérer les erreurs spécifiques à l'APIlogger.error(f"Erreur API LLMaaS: {e.status_code} - {e.message}")return "Désolé, une erreur est survenue avec le service d'IA."except Exception as e:# Gérer toutes les autres erreurs (réseau, etc.)logger.error(f"Une erreur inattendue est survenue: {e}")return "Désolé, une erreur inattendue est survenue."