Utilizzare una GPU su Managed Kubernetes
Questo tutorial mostra come distribuire un pod che utilizza una risorsa GPU su un cluster Managed Kubernetes configurato con nodi "Bare Metal" dotati di GPU NVIDIA.
Prerequisiti
- Un cluster Kubernetes gestito con almeno un nodo worker di tipo "Bare Metal" con GPU.
Manifest di Pod di esempio
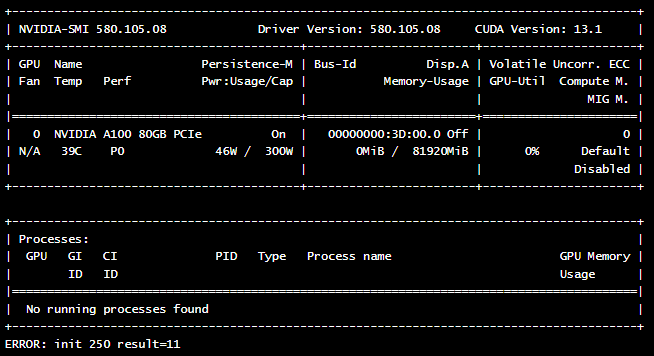
Ecco un esempio di manifest di pod che esegue il comando nvidia-smi per verificare la presenza e lo stato della scheda GPU.
apiVersion: v1
kind: Pod
metadata:
name: nvidia-cuda-check
spec:
runtimeClassName: nvidia # Clé pour Talos NVIDIA
restartPolicy: Never
containers:
- name: nvidia-version-check
image: "nvidia/cuda:13.1.0-devel-ubuntu24.04"
imagePullPolicy: Always
command: ["nvidia-smi"]
Spiegazione del Manifest
runtimeClassName: nvidia: Questa è la parte più importante. Indica a Kubernetes di utilizzare il runtime NVIDIA. Il toolkit NVIDIA si occupa quindi di iniettare i driver NVIDIA direttamente nel pod, consentendo al container di accedere alla GPU.restartPolicy: Never: Poiché questo pod è solo un comando di verifica, non vogliamo che si riavvii dopo l'esecuzione.image: "nvidia/cuda:...": Utilizziamo un'immagine fornita da NVIDIA che contiene gli strumenti necessari per interagire con la GPU.command: ["nvidia-smi"]: Questo è il comando che verrà eseguito all'interno del container.nvidia-smiè uno strumento da riga di comando che fornisce informazioni sulle GPU NVIDIA.
Per ulteriori informazioni sul funzionamento del toolkit NVIDIA, è possibile consultare la documentazione ufficiale su GitHub.
Distribuzione e Verifica
-
Distribuisci il pod utilizzando il comando
kubectl apply:kubectl apply -f nvidia-smi.yaml -
Verifica i log del pod per visualizzare l'output del comando
nvidia-smi:kubectl logs nvidia-cuda-check
Se tutto è configurato correttamente, dovresti vedere un output simile al seguente, che mostra i dettagli della tua scheda GPU :