Concetti
Le nostre offerte Managed Kubernetes
Cloud Temple propone due offerte distinte per soddisfare le vostre esigenze di orchestrazione dei container:
- Managed Core Kubernetes : Un prodotto minimalista che fornisce una base Kubernetes robusta e sicura, basata su componenti open-source all'avanguardia. È ideale per i team esperti che desiderano costruire la propria piattaforma su misura.
- Managed Kubernetes : Una soluzione completa e pronta all'uso che include una stack completa di strumenti per la rete, la sicurezza, lo storage, il deployment continuo, l'osservabilità, il backup e la gestione dei costi.
Tabella comparativa delle offerte
| Componente | Managed Core Kubernetes | Managed Kubernetes |
|---|---|---|
| OS | Talos | Talos |
| CNI | Cilium | Cilium |
| Osservabilità CNI | ❌ | Hubble |
| Load Balancer | MetalLB | MetalLB |
| Ingress | ❌ | Ingress Nginx |
| Storage | Rook-Ceph | Rook-Ceph |
| Deployment Continuo (GitOps) | ❌ | ArgoCD |
| Osservabilità | ❌ | Prometheus, Grafana, Loki |
| Backup e Migrazione | ❌ | Veeam Kasten |
| Gestione dei Costi (FinOps) | ❌ | OpenCost |
| Governance e Sicurezza | ❌ | Kyverno, Capsule |
| Container Registry | ❌ | Harbor |
| Gestione dei Certificati | ❌ | Cert-Manager |
| Autenticazione SSO | ❌ | Integrazione OIDC |
Presentazione del prodotto Managed Kubernetes (completa)
L'offerta Managed Kubernetes (nota anche come "Kub Managé" o "KM") è una soluzione di containerizzazione Kubernetes gestita da Cloud-Temple, distribuita sotto forma di Macchine Virtuali che operano sulle infrastrutture IaaS Cloud-Temple OpenIaaS.
Managed Kubernetes si basa su Talos Linux (https://www.talos.dev/), un sistema operativo dedicato a Kubernetes che è leggero e sicuro. È immutabile, privo di shell o accesso SSH, e configurato esclusivamente in modo dichiarativo tramite API gRPC.
L'installazione standardizzata include un insieme di componenti, prevalentemente OpenSource e validati dal CNCF:
-
CNI Cillium, con interfaccia di osservabilità (Hubble): Cillium è una soluzione di networking per i container Kubernetes (Container Network Interface). Gestisce la sicurezza, il load balancing, il service mesh, l'osservabilità, la crittografia, ecc... È un componente di rete fondamentale presente nella maggior parte delle distribuzioni di Kubernetes (OpenShift, AKS, GKE, EKS,...). Abbiamo incluso l'interfaccia grafica Hubble per la visualizzazione dei flussi Cillium.
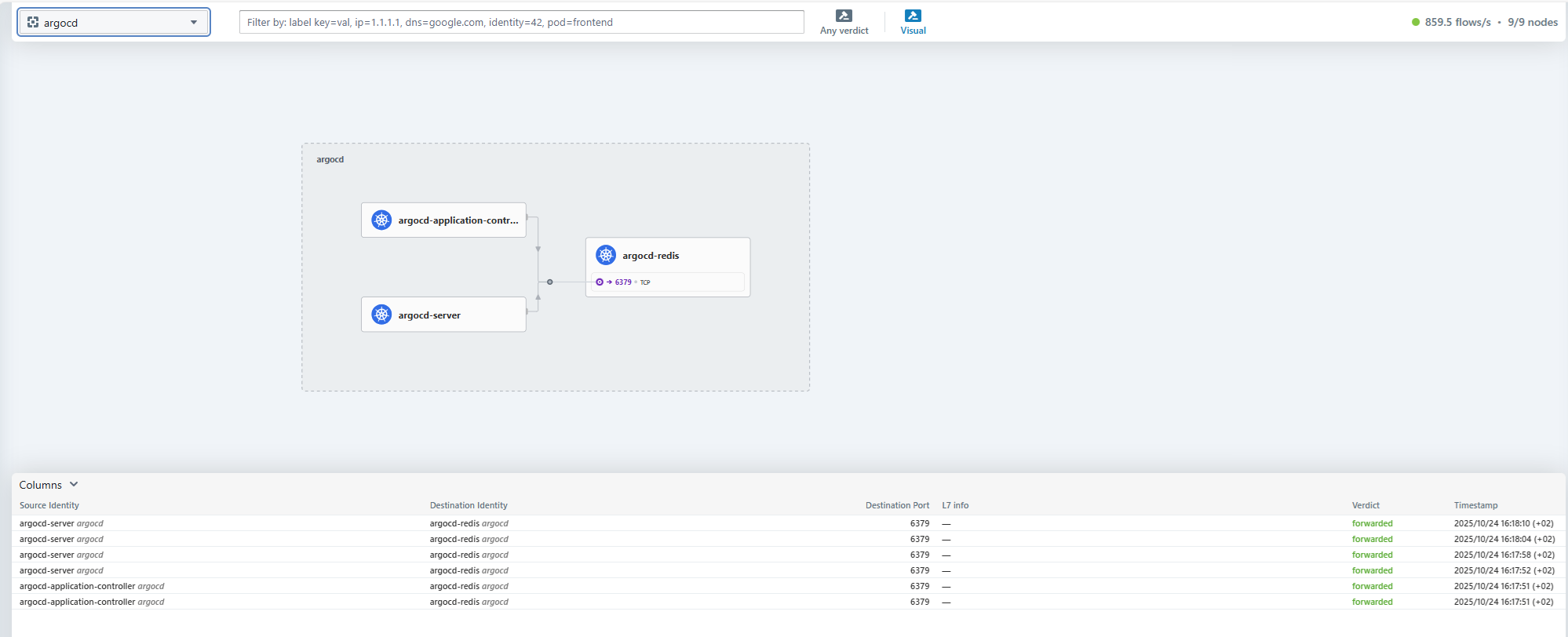
-
MetalLB e nginx: Per l'esposizione delle applicazioni Web, 3 ingress-class nginx sono integrate di base:
-
nginx-external-secured: esposizione su un IP pubblico, filtrato sul firewall per autorizzare solo IP noti (utilizzato per le interfacce grafiche dei vari prodotti e per l'API Kubernetes)
-
nginx-external: esposizione su un secondo IP pubblico non filtrato (o con filtraggio specifico per il cliente)
-
nginx-internal: esposizione su un IP interno esclusivamente
Per i servizi "non web", un load-balancer metalLB consente di esporre servizi in interno o su IP pubblici. (ciò permette di distribuire altri ingress, come ad esempio un WAF)
-
-
Storage distribuito Rook-Ceph: per lo storage dei volumi persistenti (PV), uno storage distribuito Ceph OpenSource è integrato nella piattaforma. Consente di utilizzare le storage-classes ceph-block, ceph-bucket e ceph-filesystem. Viene utilizzato uno storage da 7500 IOPS, garantendo alte prestazioni. Nei deployment di produzione (su 3 AZ), i nodi di storage sono dedicati (1 nodo per AZ); nei deployment non di produzione (1 AZ), lo storage è condiviso con i worker node.
-
Cert-Manager: il gestore di certificati OpenSource Cert-Manager è integrato nativamente nella piattaforma.
-
ArgoCD è a vostra disposizione per i deployment automatizzati tramite una pipeline di CI/CD.
-
Stack Prometheus (Prometheus, Grafana, Loki): i cluster Managed Kubernetes sono forniti di serie con una stack OpenSource completa Prometheus per l'osservabilità, che include:
-
Prometheus
-
Grafana, con numerosi dashboard
-
Loki: i log della piattaforma vengono esportati nello storage S3 Cloud-Temple (e integrati in Grafana).
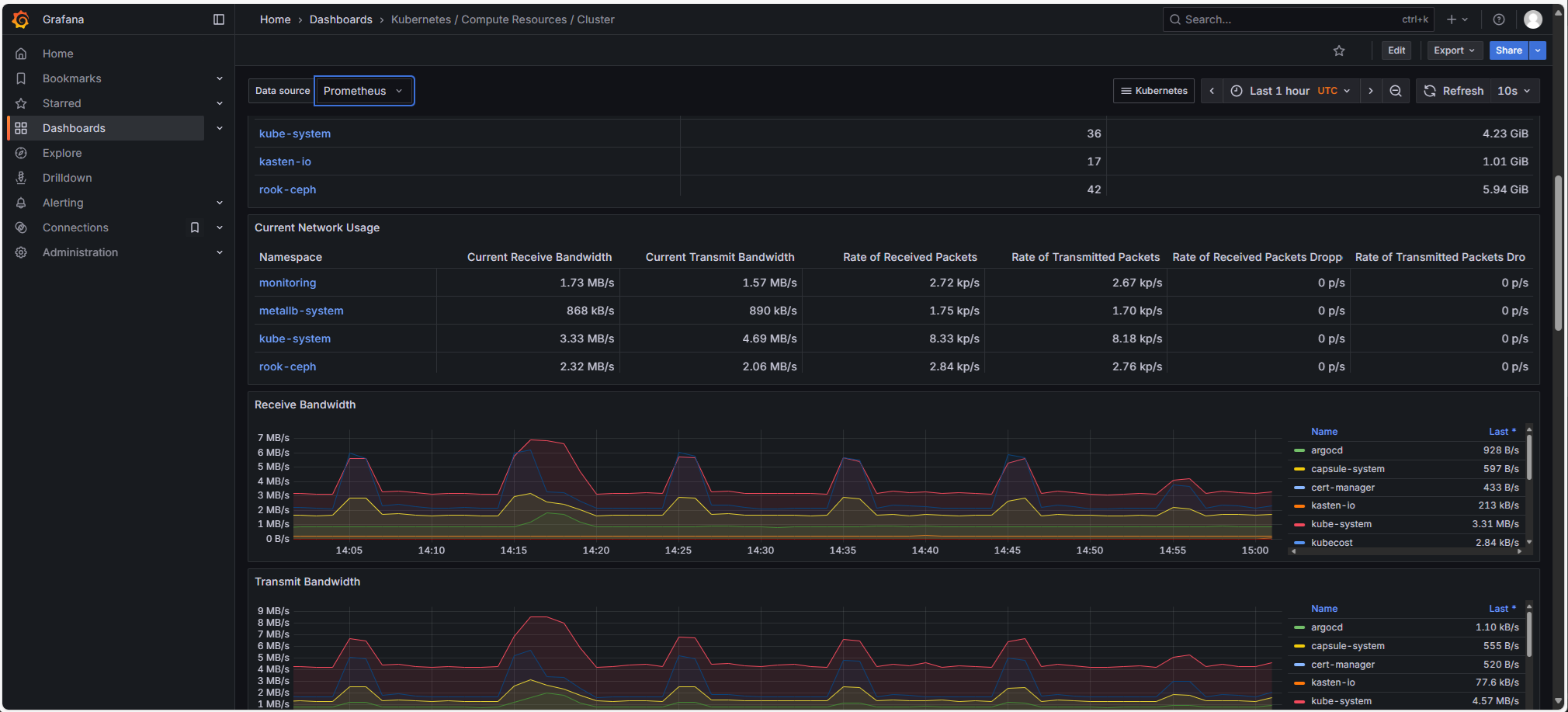
-
-
Harbor è un Container registry che vi permette di memorizzare le immagini dei vostri container o i vostri chart Helm direttamente nel cluster. Esegue scansioni di vulnerabilità sulle vostre immagini e può firmarle digitalmente. Harbor consente anche sincronizzazioni con altri registry. (https://goharbor.io/)
-
OpenCost (https://github.com/opencost/opencost) è uno strumento di gestione dei costi (FinOps) per Kubernetes. Vi permette di monitorare nel dettaglio il consumo delle risorse Kubernetes e di effettuare la rifatturazione per progetto/namespace.
-
Strategie di sicurezza avanzate con Kyverno e Capsule:
- Kyverno (https://kyverno.io/) è un controller di ammissione per Kubernetes che consente di applicare policy. È uno strumento essenziale per la governance e la sicurezza in Kubernetes.
- Capsule (https://projectcapsule.dev/) è uno strumento di gestione delle autorizzazioni che semplifica la gestione dei diritti in Kubernetes. Introduce il concetto di tenant che permette di centralizzare e delegare le autorizzazioni su più namespace. Tramite Capsule, gli utenti della piattaforma Kubernetes Managé dispongono quindi di diritti limitati ai soli propri namespace.
-
Veeam Kasten (aka 'k10') è una soluzione per il backup dei workload Kubernetes.
Consente di eseguire il backup di un deployment completo: manifest, volumi, ecc... verso lo storage oggetto S3 Cloud-Temple. Kasten utilizza Kanister per permettere backup applicativi coerenti, ad esempio per i database (https://docs.kasten.io/latest/usage/blueprints/).
Kasten è uno strumento cross-platform che può funzionare con altri cluster Kubernetes (OpenShift, Hyperscaler,...). Può quindi essere utilizzato per scenari di reversibilità o migrazione (K10 gestisce le eventuali adattamenti tramite transformations, ad esempio un cambio di ingress-class), ma anche per operazioni di "refresh" (esempio: ripristino pianificato di un ambiente di produzione in pre-produzione).
-
Autenticazione SSO con un Identity Provider Esterno OIDC (Microsoft Entra, FranceConnect, Okta, AWS IAM, Google, Salesforce, ...)
SLA & Informazioni sul supporto
- Disponibilità garantita (produzione 3 AZ) : 99.95 %
- Supporto : N1/N2/N3 inclusi per il perimetro base (infrastruttura e operatori standard).
- Impegno sul tempo di ripristino (ETR) : secondo contratto quadro Cloud Temple.
- Manutenzione (MCO) : patching regolare Talos / Kubernetes / operatori standard da parte di MSP, senza interruzione del servizio (rolling upgrade).
I tempi di presa in carico e di ripristino dipendono dalla gravità dell'incidente, conformemente alla griglia di supporto (da P1 a P4).
Politica delle versioni & ciclo di vita
- Kubernetes supportato: N-2 (3 release maggiori all'anno, circa ogni 4 mesi). Ogni release è supportata ufficialmente per 12 mesi, garantendo una finestra di supporto Cloud Temple di ~16 mesi massimo per versione.
- Talos OS: allineato alle versioni stabili di Kubernetes.
- Ogni branch è mantenuto per circa 12 mesi (inclusi i patch di sicurezza).
- Ritmo di upgrade raccomandato: 3 volte all'anno, in coerenza con gli upgrade di Kubernetes.
- I patch critici (CVE, kernel) vengono applicati tramite rolling upgrade, senza interruzione del servizio.
- Operator standard: aggiornati entro 90 giorni dalla release stabile.
- Aggiornamenti:
- Maggiori (Kubernetes N+1, Talos X+1): pianificati 3 volte/anno, tramite rolling update.
- Minori: applicati automaticamente entro 30-60 giorni.
- Deprecazione: versione N-3 → fine del supporto entro 90 giorni dall'uscita di N.
Nodi Kubernetes
Produzione (multi-zonale)
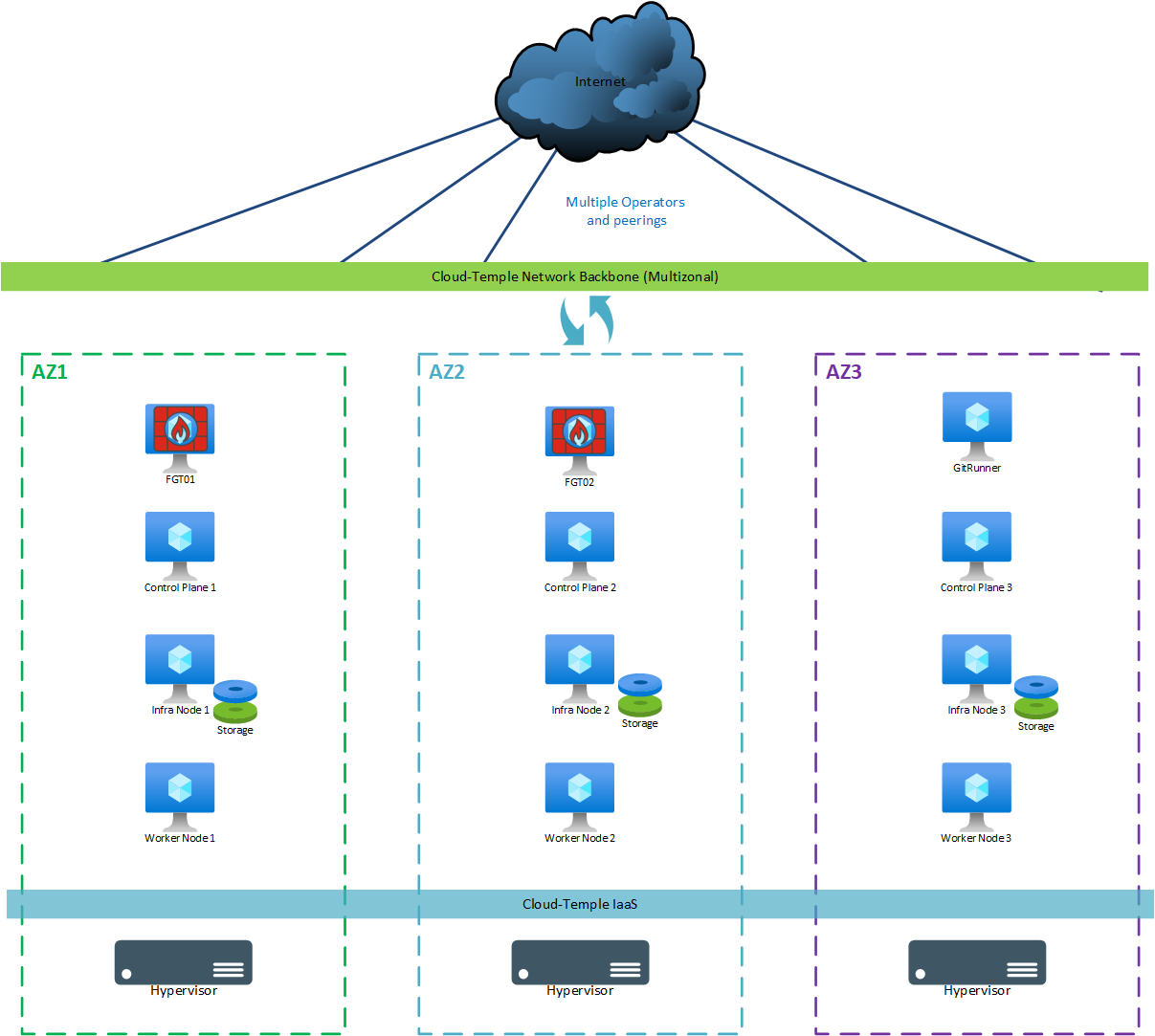
Per un deployment "di produzione" (multi-zonale), vengono utilizzate le seguenti macchine:
| AZ | Macchina | vCores | RAM | Archiviazione locale |
|---|---|---|---|---|
| AZ07 | Git Runner | 4 | 8 GB | OS: 256 GB |
| AZ05 | Control Plane 1 | 8 | 12 GB | OS: 128 GB |
| AZ06 | Control Plane 2 | 8 | 12 GB | OS: 128 GB |
| AZ07 | Control Plane 3 | 8 | 12 GB | OS: 128 GB |
| AZ05 | Storage Node 1 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB minimo (*) |
| AZ06 | Storage Node 2 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB minimo (*) |
| AZ07 | Storage Node 3 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB minimo (*) |
| AZ05 | Worker Node 1 (**) | 12 | 24 GB | OS: 128 GB |
| AZ06 | Worker Node 2 (**) | 12 | 24 GB | OS: 128 GB |
| AZ07 | Worker Node 3 (**) | 12 | 24 GB | OS: 128 GB |
(*) : Ogni nodo di storage viene fornito con un minimo di 500 GB di spazio su disco, per uno storage Ceph distribuito utile di 500 GB (i dati vengono replicati su ogni AZ, quindi x3). Lo spazio libero disponibile per il cliente è di circa 350 GB. Questa dimensione iniziale può essere aumentata al momento della configurazione, o in seguito, in base alle esigenze. Vengono applicati delle quote su Ceph, con una ripartizione Block/File.
(**) : La dimensione e il numero dei Worker Node possono essere adattati in base alle esigenze di capacità di calcolo del cliente. Il numero minimo di Worker Node è di 3 (1 per AZ) e consigliamo di aumentarne il numero a gruppi di 3 per mantenere una distribuzione multi-zonale coerente. La dimensione dei Worker Node può essere adattata, con un minimo di 12 core e 24 GB di RAM; il limite superiore per Worker Node è determinato dalla dimensione degli hypervisor utilizzati (quindi potenzialmente 112 core/1536 GB di RAM con blade Performance 3). La quantità di Worker Node è limitata a 100. Il CNCF consiglia di utilizzare worker node di dimensioni identiche. Il limite del numero di pod per Worker Node è di 110.
Dev/Test
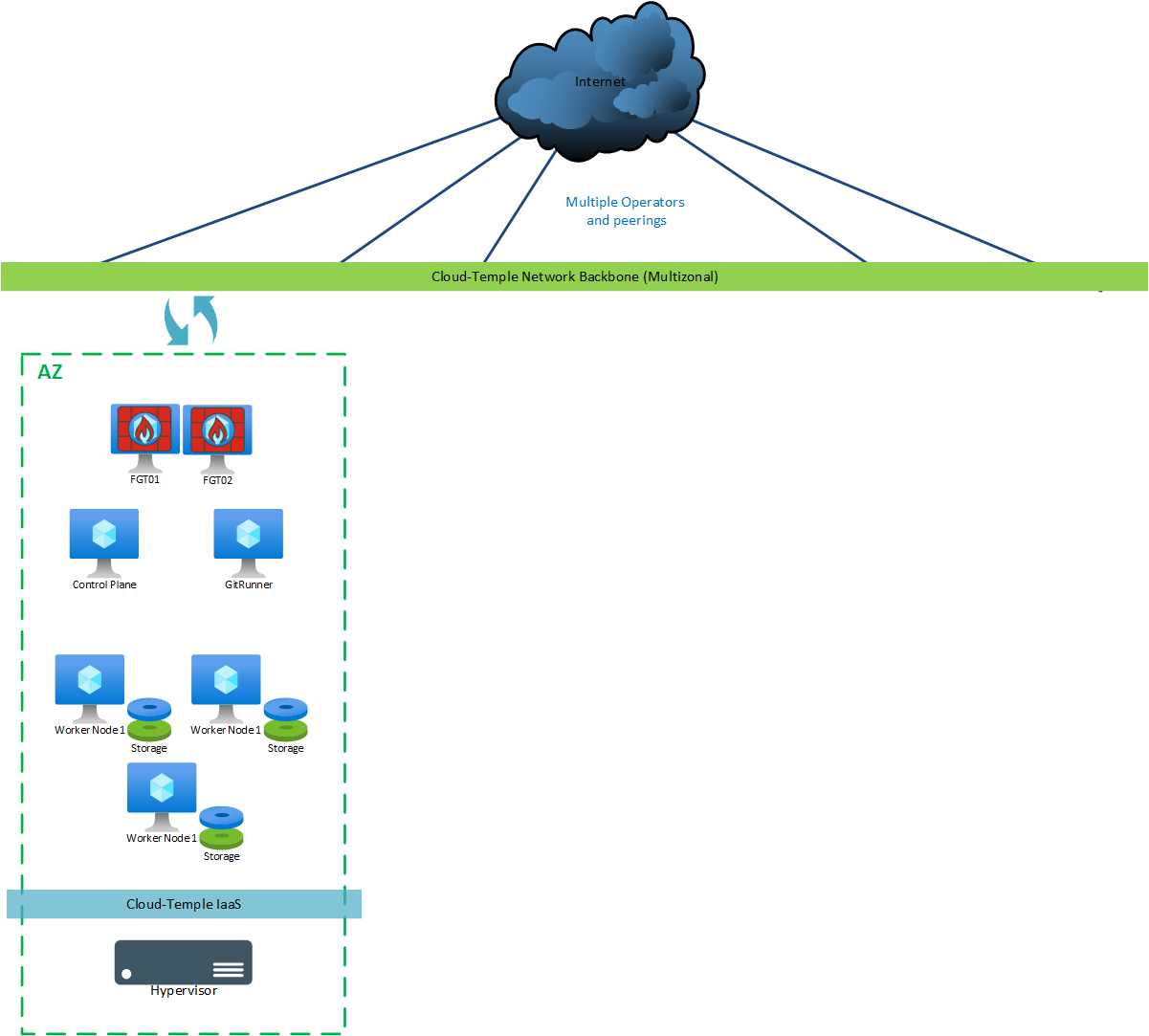
Per una versione "dev/test", vengono distribuite le seguenti macchine:
| AZ | Macchina | vCores | RAM | Storage locale |
|---|---|---|---|---|
| AZ0n | Git Runner | 4 | 8 Go | OS: 30 Go |
| AZ0n | Control Plane | 8 | 12 Go | OS: 128 Go |
| AZ0n | Worker Node 1 (**) | 12 | 24 Go | OS: 128 Go + Ceph 300 Go minimo (*) |
| AZ0n | Worker Node 2 (**) | 12 | 24 Go | OS: 128 Go + Ceph 300 Go minimo (*) |
| AZ0n | Worker Node 3 (**) | 12 | 24 Go | OS: 128 Go + Ceph 300 Go minimo (*) |
(*) : 3 Worker nodes sono utilizzati come Storage nodes e vengono forniti con un minimo di 300 Go di spazio su disco, per un'archiviazione distribuita effettiva di 300 Go (i dati vengono replicati tre volte). Lo spazio libero disponibile per il cliente è di circa 150 Go. Questa dimensione iniziale può essere aumentata al momento del provisioning, o in seguito, in base alle esigenze.
(**) : Le dimensioni e il numero dei Worker Nodes possono essere adattati in base alle esigenze di capacità di calcolo del cliente. Il numero minimo di Worker nodes è 3 (a causa della replicazione dello storage). Le dimensioni dei Worker Node possono essere adattate, con un minimo di 12 core e 24 Go di RAM; il limite superiore per Worker node è determinato dalle dimensioni degli hypervisor utilizzati (quindi potenzialmente 112 core/1536 Go di RAM con blade Performance 3). La quantità di Worker Nodes è limitata a 250. Il CNCF consiglia di utilizzare worker nodes di dimensioni identiche. Il limite del numero di pod per Worker Node è di 110.
RACI
Architettura & Infrastruttura
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Definire l'architettura globale del servizio Kubernetes | C | RA |
| Dimensionare il servizio Kubernetes (numero di nodi, risorse) | C | RA |
| Installare il servizio Kubernetes con una configurazione predefinita | I | RA |
| Configurazione del servizio Kubernetes | C | RA |
| Configurare la rete di base del servizio Kubernetes | I | RA |
| Distribuzione della configurazione iniziale delle identità e degli accessi | C | RA |
| Definire la strategia di scaling e di alta disponibilità | C | RA |
Gestione dei progetti e delle applicazioni aziendali
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Creare e gestire i progetti Kubernetes | RA | I* |
| Distribuire e gestire le applicazioni in Kubernetes | RA | I* |
| Configurare le pipeline CI/CD | RA | I* |
| Gestire le immagini dei container e i registri | RA | I* |
*può passare a "C" in base al contratto di outsourcing IT
Monitoraggio e prestazioni
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Monitorare le prestazioni del servizio Kubernetes | I | RA* |
| Monitorare le prestazioni delle applicazioni | RA | |
| Gestire le alert relative al servizio Kubernetes | I | RA* |
| Gestire le alert relative alle applicazioni | RA |
(*) : Solo per il Cluster di Produzione. In Dev/Test il cliente è completamente autonomo e responsabile.
Manutenzione e aggiornamenti Infrastrutture
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Aggiornare il servizio Kubernetes/OS | C | RA |
| Applicare le patch di sicurezza a Kubernetes | C | RA |
| Aggiornare le applicazioni distribuite (operatori*) | C | RA |
*Pacchetto operatore incluso su Managed Kube - vedere capitoli: Pacchetti Helm gestiti
Sicurezza
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Gestire la sicurezza del servizio Kubernetes | RA | RA* |
| Configurare e gestire le politiche di sicurezza dei pod | RA | I |
| Gestire i certificati SSL/TLS per il servizio Kubernetes | C | RA* |
| Gestire i certificati SSL/TLS per le applicazioni | RA | I |
| Implementare e gestire il controllo degli accessi basato sui ruoli di base (RBAC) | C | R* |
| Implementare e gestire il controllo degli accessi basato sui ruoli del cliente (RBAC) | RA | I |
(*) : Solo per il Cluster di Produzione. In Dev/Test il cliente è completamente autonomo e responsabile.
Backup e disaster recovery
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Definire la strategia di backup per il servizio Kubernetes | I | RA |
| Implementare e gestire i backup del servizio Kubernetes | I | RA |
| Definire la strategia di backup per le applicazioni | RA* | I* |
| Implementare e gestire i backup delle applicazioni | RA* | I* |
| Testare le procedure di disaster recovery per il servizio Kubernetes | CI | RA |
| Testare le procedure di disaster recovery per le applicazioni | RA* | CI* |
*può passare a "CI | RA" in base al contratto di managed service
Support e risoluzione dei problemi
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Fornire supporto di livello 1 per l'infrastruttura | I | RA |
| Fornire supporto di livello 2 e 3 per l'infrastruttura | I | RA |
| Risolvere i problemi relativi al servizio Kubernetes | C | RA |
| Risolvere i problemi relativi alle applicazioni | RA | I |
Gestione delle capacità e evoluzione
Solo per il Cluster di Produzione. In Dev/Test il cliente è completamente autonomo e responsabile.
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Monitorare l'utilizzo delle risorse Kubernetes | C | RA |
| Pianificare l’evoluzione delle capacità del servizio | RA | C |
| Implementare le modifiche di capacità | I | RA |
| Gestire l’evoluzione delle applicazioni e delle relative risorse | RA | I |
Documentazione e conformità
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Mantenere la documentazione del prodotto Kubernetes | I | RA |
| Mantenere la documentazione delle applicazioni | RA | I |
| Garantire la conformità del servizio Kubernetes | I | RA |
| Garantire la conformità delle applicazioni | RA | I |
| Eseguire audit del servizio Kubernetes | I | RA |
| Eseguire audit delle applicazioni | RA | I |
Gestione degli operatori/CRD Kubernetes (incluso nel prodotto)
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Messa a disposizione del catalogo Operatori predefinito | CI | RA |
| Aggiornamento degli Operatori | CI | RA |
| Monitoraggio dello stato degli Operatori | CI | RA |
| Risoluzione dei problemi relativi agli Operatori | CI | RA |
| Gestione delle autorizzazioni degli Operatori | CI | RA |
| Gestione delle risorse degli Operatori (aggiunta/rimozione) | CI | RA |
| Backup dei dati delle risorse degli Operatori | CI | RA |
| Supervisione delle risorse Operatori | CI | RA |
| Ripristino dei dati delle risorse degli Operatori | CI | RA |
| Audit di sicurezza degli Operatori | CI | RA |
| Supporto per gli Operatori | CI | RA |
| Gestione delle licenze per gli operatori | CI | RA |
| Gestione dei piani di supporto specifici per gli operatori | CI | RA |
*Pacchetto operatore incluso su Managed Kube - vedere capitoli: Pacchetti Helm gestiti
Gestione delle applicazioni/operatori/CRD Kubernetes (del cliente)
Solo cluster di Produzione. In Dev/Test il cliente è completamente autonomo e responsabile.
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Distribuzione dei CRD | I* | RA* |
| Aggiornamento degli Operatori | RA | I |
| Monitoraggio dello stato degli Operatori | RA | I |
| Risoluzione dei problemi relativi agli Operatori | RA | I |
| Gestione delle autorizzazioni degli Operatori | RA | I |
| Gestione delle risorse degli Operatori (aggiunta/rimozione) | RA | I |
| Backup dei dati delle risorse degli Operatori | RA | I |
| Supervisione delle risorse Operatori | RA | I |
| Ripristino dei dati delle risorse degli Operatori | RA | I |
| Audit di sicurezza degli Operatori | RA | I |
| Supporto degli Operatori | RA | I |
| Gestione delle licenze per gli operatori | RA | I |
| Gestione dei piani di supporto specifici per gli operatori | RA | I |
Alcuni servizi degli operatori possono essere gestiti in base al contratto di managed service.
*può passare a "A | RC" in base al contratto di managed service
Assistenza applicativa
| Attività | Cliente | Cloud Temple |
|---|---|---|
| Assistenza applicativa (servizio esterno) | RA | I |
Un supporto applicativo può essere fornito tramite un servizio complementare.
RACI (sintetico)
- Cloud Temple : responsabile e attore (RA) della piattaforma Kubernetes, sicurezza del cluster, backup infrastrutturale, monitoraggio, CRD.
- Cliente : responsabile e attore (RA) dei progetti applicativi, operatori di business, pipeline CI/CD, backup applicativi.
- Zona "grigia" : adattamenti ed estensioni (IAM, operatori specifici, rafforzamento della conformità/sicurezza del cluster) - fatturate a progetto.