Tutorial LLMaaS
Panoramica
Questi tutorial avanzati coprono l'integrazione, l'ottimizzazione e le migliori pratiche per sfruttare appieno LLMaaS Cloud Temple in produzione. Ogni tutorial include codice testato e metriche di performance reali.
🚀 Integrazioni LangChain e Framework
1. Integrazione di base con LangChain
Questo primo esempio mostra come integrare la nostra API LLMaaS con il popolare framework LangChain creando un "wrapper" personalizzato. Un wrapper è una classe che "avvolge" la nostra API per renderla compatibile con i meccanismi interni di LangChain.
Codice Spiegato
Il codice seguente definisce una classe CloudTempleLLM che eredita dalla classe base LLM di LangChain. Questo ci permette di definire un comportamento su misura rimanendo compatibili con l'ecosistema LangChain (catene, agenti, ecc.).
CloudTempleLLM(LLM): La nostra classe eredita daLLM, il che ci obbliga a implementare certi metodi, in particolare_call._call(self, prompt: str, ...): Questo è il cuore del nostro wrapper. Ogni volta che LangChain avrà bisogno di fare appello al nostro modello di linguaggio, invocherà questo metodo. All'interno, formattiamo una richiesta HTTP POST standard con i corretti header (Authorization) e ilpayloadatteso dalla nostra API/v1/chat/completions.esempio_langchain_basic(): Questa funzione di dimostrazione mostra come utilizzare il nostro wrapper. Lo istanziamo, creiamo unPromptTemplateper strutturare la nostra richiesta e li combiniamo in unaLLMChain. Quando eseguiamo la catena (chain.run(...)), LangChain chiama dietro le quinte il metodo_callche abbiamo definito.
Questo approccio è utile se desiderate un controllo totale su come LangChain interagisce con l'API, ma è più verboso rispetto all'uso del client ChatOpenAI (vedere Riferimento API).
# Installazione delle dipendenze
# pip install langchain requests pydantic
from langchain.llms.base import LLM
from langchain.schema import LLMResult, Generation
from typing import Optional, List, Any
from pydantic import Field
import requests
import json
import os
# --- Configurazione ---
# Si consiglia di memorizzare la chiave API in una variabile d'ambiente
API_KEY = os.getenv("LLMAAS_API_KEY", "vostra-chiave-api-qui")
BASE_URL = "https://api.ai.cloud-temple.com/v1"
class CloudTempleLLM(LLM):
"""
Wrapper LangChain personalizzato per l'API LLMaaS di Cloud Temple.
Questa classe permette di utilizzare la nostra API come un LLM standard in LangChain.
"""
api_key: str = Field(default="")
model_name: str = Field(default="granite3.3:8b")
temperature: float = Field(default=0.7)
max_tokens: int = Field(default=1000)
@property
def _llm_type(self) -> str:
"""Identificatore univoco per il nostro tipo di LLM."""
return "cloud_temple_llmaas"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
"""
Il metodo principale che effettua la chiamata all'API LLMaaS.
LangChain utilizza questo metodo per ogni richiesta al modello.
"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": self.model_name,
"messages": [{"role": "user", "content": prompt}],
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
if stop:
payload["stop"] = stop
# Esecuzione della richiesta POST verso l'API
response = requests.post(
f"{BASE_URL}/chat/completions",
headers=headers,
json=payload,
timeout=60
)
response.raise_for_status() # Solleva un'eccezione in caso di errore HTTP
result = response.json()
# Restituisce il contenuto del messaggio dell'assistente
return result['choices'][0]['message']['content']
# --- Esempio d'uso ---
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
def esempio_langchain_wrapper():
"""Dimostra l'uso del wrapper LLM con una catena LangChain."""
# 1. Inizializzazione del nostro LLM personalizzato
llm = CloudTempleLLM(
api_key=API_KEY,
model_name="granite3.3:8b"
)
# 2. Creazione di un template di prompt per strutturare le richieste
template = """
Sei un esperto in {dominio}.
Rispondi a questa domanda in modo dettagliato e professionale:
Domanda: {question}
Risposta:
"""
prompt = PromptTemplate(
input_variables=["dominio", "question"],
template=template
)
# 3. Creazione di una catena che combina il prompt e il LLM
chain = LLMChain(llm=llm, prompt=prompt)
# 4. Esecuzione della catena con variabili specifiche
result = chain.run(
dominio="cybersicurezza",
question="Quali sono le migliori pratiche per proteggere un'API REST?"
)
return result
# --- Avvio del test ---
if __name__ == "__main__":
if API_KEY == "vostra-chiave-api-qui":
print("Si prega di configurare LLMAAS_API_KEY nelle variabili d'ambiente.")
else:
risposta = esempio_langchain_wrapper()
print("Risposta dell'esperto in cybersicurezza :\n")
print(risposta)
2. RAG (Retrieval-Augmented Generation) con l'API LLMaaS
Il RAG è una tecnica potente che permette a un LLM di rispondere a domande basandosi su una base di conoscenza esterna. Questo tutorial vi guida attraverso la creazione di una pipeline RAG semplice utilizzando la nostra API per gli embedding e la generazione, e FAISS, una libreria di similarità vettoriale, per creare un indice in memoria.
Codice Spiegato
La pipeline si scompone in diverse fasi logiche:
- Configurazione: Importiamo le librerie necessarie e carichiamo la nostra chiave API dalle variabili d'ambiente. Definiamo i modelli da utilizzare:
granite-embedding:278mper la vettorializzazione egranite3.3:8bper la generazione. LLMaaSEmbeddings: Come nell'esempio precedente, abbiamo bisogno di un wrapper per interagire con la nostra API di embedding. Questa classe si occupa di trasformare i frammenti di testo (chunks) in vettori numerici (embeddings).setup_rag_pipeline: Questa funzione orchestra la creazione della pipeline.- Caricamento dei documenti:
DirectoryLoadercarica i file di testo della nostra base di conoscenza. - Suddivisione in chunks:
RecursiveCharacterTextSplittertaglia i documenti in frammenti più piccoli. È essenziale affinché il modello di embedding possa elaborare efficacemente il testo e affinché la ricerca di similarità sia precisa. - Vettorializzazione e Indicizzazione:
FAISS.from_documentsè una fase chiave. Prende i chunks di testo, utilizza la nostra classeLLMaaSEmbeddingsper chiamare l'API e ottenere i vettori corrispondenti, quindi memorizza questi vettori in un indice FAISS in memoria. - Configurazione del LLM: Utilizziamo
ChatOpenAIche è nativamente compatibile con la nostra API per la parte di generazione della risposta. - Creazione della catena
RetrievalQA: È la catena LangChain che lega tutti gli elementi. Quando le si pone una domanda: a. Utilizza ilretriever(basato sul nostro indice FAISS) per trovare i chunks di testo più pertinenti. b. Inserisce ("Stuff") questi chunks in un prompt con la domanda. c. Invia questo prompt arricchito al LLM per generare una risposta contestuale.
- Caricamento dei documenti:
- Esecuzione: La funzione
mainsimula un utilizzo reale creando file di conoscenza temporanei, costruendo la pipeline e ponendo una domanda.
import os
import tempfile
import shutil
from pathlib import Path
from dotenv import load_dotenv
from typing import List
# --- Import LangChain ---
from langchain_core.embeddings import Embeddings
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
# --- Configurazione ---
# Carica le variabili d'ambiente (es: LLMAAS_API_KEY)
load_dotenv()
API_KEY = os.getenv("LLMAAS_API_KEY")
BASE_URL = os.getenv("API_URL", "https://api.ai.cloud-temple.com/v1")
EMBEDDING_MODEL = "granite-embedding:278m"
LLM_MODEL = "granite3.3:8b"
# --- Classe di Embedding Personalizzata ---
class LLMaaSEmbeddings(Embeddings):
"""Classe di embedding personalizzata per l'API LLMaaS di Cloud Temple."""
def __init__(self, api_key: str, model_name: str):
if not api_key:
raise ValueError("La chiave API LLMaaS non può essere vuota.")
self.api_key = api_key
self.model_name = model_name
self.base_url = BASE_URL
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
def _embed(self, texts: List[str]) -> List[List[float]]:
import httpx
payload = {"input": texts, "model": self.model_name}
try:
with httpx.Client(timeout=60.0) as client:
response = client.post(f"{self.base_url}/embeddings", headers=self.headers, json=payload)
response.raise_for_status()
data = response.json()['data']
data.sort(key=lambda e: e['index'])
return [item['embedding'] for item in data]
except httpx.HTTPStatusError as e:
print(f"Errore HTTP durante la generazione degli embedding: {e.response.text}")
raise
except Exception as e:
print(f"Si è verificato un errore imprevisto durante la generazione degli embedding: {e}")
raise
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return self._embed(texts)
def embed_query(self, text: str) -> List[float]:
# Il metodo _embed attende una lista, quindi incapsuliamo il testo singolo.
return self._embed([text])[0]
# --- Pipeline RAG ---
def setup_rag_pipeline(documents_path: str):
"""Configurazione completa della pipeline RAG con gli strumenti LLMaaS."""
print("1. Caricamento e suddivisione dei documenti...")
loader = DirectoryLoader(documents_path, glob="*.txt", loader_cls=TextLoader, loader_kwargs={'encoding': 'utf-8'})
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(documents)
print(f" -> {len(documents)} documento(i) caricato(i) e suddiviso(i) in {len(splits)} chunks.")
print(f"2. Creazione degli embedding tramite LLMaaS (modello: {EMBEDDING_MODEL})...")
embeddings = LLMaaSEmbeddings(api_key=API_KEY, model_name=EMBEDDING_MODEL)
print("3. Creazione dell'indice vettoriale in memoria (FAISS)...")
vectorstore = FAISS.from_documents(splits, embeddings)
print(" -> Indice FAISS creato con successo.")
print(f"4. Configurazione del LLM (modello: {LLM_MODEL})...")
# Correzione per la compatibilità Pydantic/LangChain
from langchain_core.caches import BaseCache
from langchain_core.callbacks.base import Callbacks
ChatOpenAI.model_rebuild()
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=LLM_MODEL,
temperature=0.3,
model_kwargs={"max_tokens": 300}
)
print("5. Creazione della catena di Domanda/Risposta (RAG)...")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
print(" -> Pipeline RAG pronta.")
return qa_chain
# --- Esecuzione ---
def main():
"""Funzione principale per eseguire la pipeline RAG da cima a fondo."""
if not API_KEY:
print("Errore: La variabile d'ambiente LLMAAS_API_KEY non è definita.")
return
# Creare documenti di test temporanei
temp_dir = tempfile.mkdtemp()
print(f"\nCreazione di documenti di test in: {temp_dir}")
try:
documents_content = {
"overview.txt": "Cloud Temple è un fornitore di cloud sovrano francese qualificato SecNumCloud.",
"pricing.txt": "Le tariffe dell'API LLMaaS sono di 1,9€/milione di token in ingresso e 8€/milione in uscita."
}
for filename, content in documents_content.items():
with open(Path(temp_dir) / filename, 'w', encoding='utf-8') as f:
f.write(content)
# Configurare ed eseguire la pipeline
rag_chain = setup_rag_pipeline(temp_dir)
print("\n--- Interrogazione della Pipeline RAG ---")
question = "Qual è la tariffa dei token in uscita sull'API LLMaaS di Cloud Temple?"
result = rag_chain({"query": question})
print(f"\nDomanda: {question}")
print(f"Risposta: {result['result']}")
print("\nFonti utilizzate per la risposta:")
for source in result["source_documents"]:
print(f"- File: {os.path.basename(source.metadata['source'])}")
print(f" Contenuto: \"{source.page_content}\"")
finally:
# Pulire la directory temporanea
print(f"\nPulizia della directory temporanea: {temp_dir}")
shutil.rmtree(temp_dir)
if __name__ == "__main__":
main()
3. Integrazione con un database vettoriale (Qdrant)
Per applicazioni RAG in produzione, si raccomanda l'uso di un database vettoriale dedicato come Qdrant. A differenza di FAISS che funziona in memoria, Qdrant offre la persistenza dei dati, capacità di ricerca avanzata e una migliore scalabilità.
Codice Spiegato
Questo tutorial adatta la pipeline RAG precedente per utilizzare Qdrant.
- Prerequisiti: La prima fase è avviare un'istanza di Qdrant. Il modo più semplice è utilizzare Docker.
setup_qdrant_rag_pipeline:- Embedding e Documenti: La creazione degli embedding e dei documenti rimane identica all'esempio precedente.
- Connessione a Qdrant: Invece di creare un indice FAISS, utilizziamo
Qdrant.from_documents. Questo metodo LangChain gestisce diverse fasi: a. Si connette alla vostra istanza Qdrant tramite l'URL fornito. b. Crea una nuova "collection" (l'equivalente di una tabella in un database SQL) se non esiste. c. Chiama la nostra classeLLMaaSEmbeddingsper vettorializzare i documenti. d. Inserisce i documenti e i loro vettori nella collection Qdrant. force_recreate=True: Per questo tutorial, utilizziamo questo parametro per assicurarci che la collection sia vuota a ogni esecuzione. In produzione, lo impostereste suFalseper conservare i vostri dati.
- Il resto della pipeline (configurazione del LLM, creazione della catena
RetrievalQA) è identico, il che dimostra la flessibilità di LangChain: basta cambiare la sorgente delretriever(il ricercatore di informazioni) per passare da FAISS a Qdrant.
Per questo tutorial, avrete bisogno di un'istanza Qdrant. Potete avviarla facilmente con Docker:
# 1. Scaricare l'ultima immagine di Qdrant
docker pull qdrant/qdrant
# 2. Avviare il container Qdrant
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
Il codice seguente mostra come adattare la pipeline RAG per utilizzare Qdrant come database vettoriale.
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Qdrant
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from typing import List
from langchain_core.embeddings import Embeddings
# (La classe LLMaaSEmbeddings è la stessa dell'esempio precedente,
# la riutilizziamo qui. Assicuratevi che sia definita nel vostro script.)
# --- Configurazione ---
load_dotenv()
API_KEY = os.getenv("LLMAAS_API_KEY")
BASE_URL = os.getenv("API_URL", "https://api.ai.cloud-temple.com/v1")
EMBEDDING_MODEL = "granite-embedding:278m"
LLM_MODEL = "granite3.3:8b"
QDRANT_URL = os.getenv("QDRANT_URL", "http://localhost:6333")
QDRANT_COLLECTION_NAME = "tutorial_collection"
# --- Classe di Embedding (riutilizzata dall'esempio precedente) ---
class LLMaaSEmbeddings(Embeddings):
def __init__(self, api_key: str, model_name: str):
if not api_key: raise ValueError("La chiave API è richiesta.")
self.api_key, self.model_name, self.base_url = api_key, model_name, BASE_URL
self.headers = {"Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json"}
def _embed(self, texts: List[str]) -> List[List[float]]:
import httpx
payload = {"input": texts, "model": self.model_name}
with httpx.Client(timeout=60.0) as client:
r = client.post(f"{self.base_url}/embeddings", headers=self.headers, json=payload)
r.raise_for_status()
data = r.json()['data']
data.sort(key=lambda e: e['index'])
return [item['embedding'] for item in data]
def embed_documents(self, texts: List[str]) -> List[List[float]]: return self._embed(texts)
def embed_query(self, text: str) -> List[float]: return self._embed([text])[0]
def setup_qdrant_rag_pipeline():
"""Configura e restituisce una pipeline RAG che utilizza Qdrant."""
print("1. Inizializzazione del client di embedding LLMaaS...")
embeddings = LLMaaSEmbeddings(api_key=API_KEY, model_name=EMBEDDING_MODEL)
print("2. Preparazione dei documenti...")
documents_content = [
"Cloud Temple è un fornitore di cloud sovrano francese con la qualifica SecNumCloud.",
"Le tariffe LLMaaS sono di 1,9€ per l'input e 8€ per l'output per milione di token."
]
documents = [Document(page_content=d) for d in documents_content]
print(f"3. Connessione a Qdrant e popolamento della collection '{QDRANT_COLLECTION_NAME}'...")
vectorstore = Qdrant.from_documents(
documents,
embeddings,
url=QDRANT_URL,
collection_name=QDRANT_COLLECTION_NAME,
force_recreate=True, # Assicura una collection pulita per il tutorial
)
print(" -> Collection creata e popolata con successo.")
print(f"4. Configurazione del LLM ({LLM_MODEL})...")
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=LLM_MODEL,
temperature=0.3
)
print("5. Creazione della catena RAG...")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
print(" -> Pipeline RAG con Qdrant pronta.")
return qa_chain
# --- Esecuzione ---
def main_qdrant():
"""Funzione principale per eseguire la pipeline RAG con Qdrant."""
if not API_KEY:
print("Errore: La variabile d'ambiente LLMAAS_API_KEY non è definita.")
return
try:
rag_chain = setup_qdrant_rag_pipeline()
question = "Quali sono le tariffe dell'API LLMaaS di Cloud Temple?"
print(f"\n--- Interrogazione della pipeline ---")
result = rag_chain({"query": question})
print(f"\nDomanda: {question}")
print(f"Risposta: {result['result']}")
print("\nFonti utilizzate per la risposta:")
for source in result["source_documents"]:
print(f"- Contenuto: \"{source.page_content}\"")
except Exception as e:
print(f"\nSi è verificato un errore: {e}")
print("Assicuratevi che il container Qdrant sia correttamente in esecuzione.")
if __name__ == "__main__":
main_qdrant()
4. Agenti LangChain con Strumenti
Un agente è un LLM che non si limita a rispondere a una domanda, ma può utilizzare un insieme di strumenti (funzioni, API, ecc.) per costruire una risposta più complessa. Può ragionare, scomporre un problema, scegliere uno strumento, eseguirlo, osservare il risultato e ripetere questo ciclo fino a ottenere una risposta finale.
Codice Spiegato
Questo esempio costruisce un agente semplice capace di utilizzare due strumenti: uno per interrogare un'API (simulata) di Cloud Temple e un altro per fare calcoli.
- Definizione degli Strumenti: Le classi
CloudTempleAPITooleCalculatorToolereditano daBaseTool. Ogni strumento ha:- Un
name: un nome semplice e descrittivo. - Una
description: cruciale, è ciò che il LLM legge per decidere quale strumento utilizzare. Deve essere molto chiara su cosa fa lo strumento e quando usarlo. - Un metodo
_run: il codice che viene effettivamente eseguito quando l'agente sceglie questo strumento.
- Un
create_agent_with_tools:- Inizializzazione del LLM: Utilizziamo il nostro wrapper
CloudTempleLLMdefinito nel primo tutorial. - Elenco degli strumenti: Forniamo all'agente l'elenco degli strumenti che ha il diritto di utilizzare.
- Prompt dell'agente: Il prompt è molto specifico. Si tratta di un "prompt di ragionamento" che istruisce il LLM su come pensare (
Thought), scegliere un'azione (Action), fornire un input a questa azione (Action Input) e osservare il risultato (Observation). È il meccanismo centrale del framework ReAct (Reasoning and Acting) utilizzato qui. - Creazione dell'agente:
create_react_agentassembla il LLM, gli strumenti e il prompt per creare l'agente. AgentExecutor: È il motore che fa girare l'agente in loop fino a quando non produce unaFinal Answer. Il parametroverbose=Trueè molto utile per vedere il "dialogo interiore" dell'agente (i suoi pensieri, le sue azioni, ecc.).
- Inizializzazione del LLM: Utilizziamo il nostro wrapper
from langchain.agents import Tool, AgentExecutor, create_react_agent
from langchain.tools import BaseTool
from langchain.prompts import PromptTemplate
import requests
import json
import os
# (La classe CloudTempleLLM è la stessa del primo esempio)
# --- Definizione degli Strumenti ---
class CloudTempleAPITool(BaseTool):
"""Uno strumento che simula una chiamata a un'API interna per ottenere informazioni sui servizi."""
name = "cloud_temple_api_checker"
description = "Utile per ottenere informazioni su servizi, prodotti e offerte di Cloud Temple."
def _run(self, query: str) -> str:
# In un caso reale, questo chiamerebbe una vera API.
print(f"--- Strumento CloudTempleAPITool chiamato con la query: '{query}' ---")
if "servizio" in query.lower():
return "Cloud Temple offre i seguenti servizi: IaaS, PaaS, LLMaaS, Sicurezza Gestita."
return "Informazione non trovata."
async def _arun(self, query: str) -> str:
# Implementazione asincrona non necessaria per questo esempio.
raise NotImplementedError("Lo strumento API non supporta l'esecuzione asincrona.")
class SimpleCalculatorTool(BaseTool):
"""Uno strumento semplice per effettuare calcoli matematici."""
name = "simple_calculator"
description = "Utile per effettuare calcoli matematici semplici. Accetta un'espressione valida in Python."
def _run(self, expression: str) -> str:
print(f"--- Strumento SimpleCalculatorTool chiamato con l'espressione: '{expression}' ---")
try:
# ATTENZIONE: eval() è pericoloso in produzione. È solo per la demo.
return str(eval(expression))
except Exception as e:
return f"Errore di calcolo: {e}"
async def _arun(self, expression: str) -> str:
raise NotImplementedError("Lo strumento Calcolatrice non supporta l'esecuzione asincrona.")
# --- Creazione dell'Agente ---
def create_agent():
"""Configura e restituisce un agente LangChain con gli strumenti definiti."""
print("1. Inizializzazione del LLM per l'agente...")
llm = CloudTempleLLM(api_key=os.getenv("LLMAAS_API_KEY", "vostra-chiave-api-qui"))
tools = [CloudTempleAPITool(), SimpleCalculatorTool()]
# Il template di prompt è cruciale: guida il LLM nel suo ragionamento.
template = """
Rispondi alle seguenti domande nel modo migliore possibile. Hai accesso ai seguenti strumenti:
{tools}
Utilizza il seguente formato:
Question: la domanda a cui devi rispondere
Thought: devi sempre riflettere su ciò che farai
Action: l'azione da intraprendere, deve essere una di [{tool_names}]
Action Input: l'input dell'azione
Observation: il risultato dell'azione
... (questa sequenza Thought/Action/Action Input/Observation può ripetersi)
Thought: Ora conosco la risposta finale.
Final Answer: la risposta finale alla domanda originale
Inizia !
Question: {input}
Thought:{agent_scratchpad}
"""
prompt = PromptTemplate.from_template(template)
print("2. Creazione dell'agente con il framework ReAct...")
agent = create_react_agent(llm, tools, prompt)
# L'AgentExecutor è responsabile dell'esecuzione dei cicli dell'agente.
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
print(" -> Agente pronto.")
return agent_executor
# --- Esecuzione ---
def run_agent():
"""Esegue l'agente con diverse domande per testare le sue capacità."""
if os.getenv("LLMAAS_API_KEY") is None:
print("Si prega di configurare LLMAAS_API_KEY.")
return
agent_executor = create_agent()
print("\n--- Test 1 : Domanda che richiede uno strumento d'informazione ---")
question1 = "Quali sono i servizi offerti da Cloud Temple ?"
response1 = agent_executor.invoke({"input": question1})
print(f"\nRisposta finale dell'agente: {response1['output']}")
print("\n--- Test 2 : Domanda che richiede un calcolo ---")
question2 = "Qual è il risultato di 125 * 8 + 50 ?"
response2 = agent_executor.invoke({"input": question2})
print(f"\nRisposta finale dell'agente: {response2['output']}")
if __name__ == "__main__":
run_agent()
5. Integrazione OpenAI SDK
Migrazione trasparente da OpenAI
from openai import OpenAI
# Configurazione per Cloud Temple LLMaaS
def setup_cloud_temple_client():
"""Configurazione client OpenAI per Cloud Temple"""
client = OpenAI(
api_key="your-cloud-temple-api-key",
base_url="https://api.ai.cloud-temple.com/v1"
)
return client
def test_openai_compatibility():
"""Test di compatibilità con SDK OpenAI"""
client = setup_cloud_temple_client()
# Chat completion standard
response = client.chat.completions.create(
model="granite3.3:8b",
messages=[
{"role": "system", "content": "Sei un assistente IA professionale."},
{"role": "user", "content": "Spiegami l'architettura cloud native."}
],
max_tokens=300,
temperature=0.7
)
print(f"Risposta: {response.choices[0].message.content}")
# Streaming
stream = client.chat.completions.create(
model="granite3.3:8b",
messages=[
{"role": "user", "content": "Scrivi una poesia sull'IA."}
],
stream=True,
max_tokens=200
)
print("Stream:")
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
print()
# Test di compatibilità
test_openai_compatibility()
5. Integrazione Semantic Kernel (Microsoft)
Semantic Kernel è un SDK open-source di Microsoft che permette d'integrare dei LLM in applicazioni .NET, Python, e Java. Sebbene sia ottimizzato per i servizi Azure OpenAI, la sua flessibilità permette di utilizzarlo con qualsiasi API compatibile OpenAI, compresa la nostra.
Codice Spiegato
Questo esempio non richiede l'SDK Semantic Kernel completo. Dimostra come il concetto di "funzione semantica" possa essere implementato con una semplice chiamata alla nostra API. Una funzione semantica è essenzialmente un prompt strutturato inviato a un LLM per compiere un compito specifico.
semantic_kernel_simple(): Questa funzione simula una "funzione di riassunto".- Prompt Strutturato: Utilizziamo un messaggio
systemper dare un ruolo al LLM ("Sei un esperto in riassunti.") e un messaggiousercontenente il testo da riassumere. È il cuore del concetto di funzione semantica. - Chiamata API Diretta: Una semplice chiamata
requests.postal nostro endpoint/v1/chat/completionsè sufficiente per eseguire la funzione.
Questo esempio illustra che non è sempre necessario utilizzare un framework pesante. Per compiti semplici e ben definiti, una chiamata diretta all'API LLMaaS è spesso la soluzione più efficace e performante.
import requests
import os
from dotenv import load_dotenv
def semantic_kernel_simulation():
"""
Simula una "funzione semantica" di riassunto chiamando direttamente l'API LLMaaS.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Si prega di definire la variabile d'ambiente LLMAAS_API_KEY.")
return
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
text_to_summarize = """
L'intelligenza artificiale (IA) sta trasformando numerosi settori industriali automatizzando i compiti,
ottimizzando i processi e permettendo analisi predittive avanzate.
Cloud Temple, con la sua offerta LLMaaS sovrana e certificata SecNumCloud, permette alle aziende
di integrare queste capacità di IA garantendo al contempo la sicurezza e la riservatezza dei loro dati.
"""
# Il prompt combina un'istruzione (ruolo sistema) e dei dati (ruolo utente)
payload = {
"model": "granite3.3:8b",
"messages": [
{"role": "system", "content": "Sei un assistente esperto in sintesi di documenti tecnici."},
{"role": "user", "content": f"Riassumi il seguente testo in una sola frase concisa: {text_to_summarize}"}
],
"max_tokens": 100,
"temperature": 0.5
}
try:
response = requests.post(
"https://api.ai.cloud-temple.com/v1/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
summary = result['choices'][0]['message']['content']
print("Testo originale:\n", text_to_summarize)
print("\nRiassunto generato:\n", summary)
return summary
except requests.exceptions.RequestException as e:
print(f"Si è verificato un errore API: {e}")
if __name__ == "__main__":
semantic_kernel_simulation()
6. Framework Haystack
Haystack è un altro framework open-source potente per costruire applicazioni di ricerca sementica, di RAG e di agenti. Come per Semantic Kernel, la nostra API può essere integrata direttamente.
Codice Spiegato
Questo esempio simula una "pipeline" Haystack di base per la ricerca di risposte in un contesto dato (Question Answering).
process_with_context: Questa funzione rappresenta il cuore di una pipeline di QA. Prende uncontesto(ad esempio, un paragrafo di un documento) e unadomanda.- Prompt Contestuale: Il prompt è accuratamente strutturato per includere sia il contesto che la domanda. È una tecnica fondamentale nel RAG: forniamo al LLM le informazioni pertinenti affinché possa formulare una risposta fattuale.
- Chiamata API: Ancora una volta, una semplice chiamata
requests.postalla nostra API è sufficiente. Il LLM riceve il contesto e la domanda, e il suo compito è di sintetizzare una risposta basata esclusivamente sulle informazioni fornite.
Questo esempio illustra la flessibilità dell'API LLMaaS, che può servire da mattone di base per la generazione di testo in qualsiasi framework, anche quelli per cui non esiste un'integrazione ufficiale.
import requests
import os
from dotenv import load_dotenv
def haystack_simulation():
"""
Simula una pipeline di Question-Answering di tipo Haystack
utilizzando una chiamata diretta all'API LLMaaS.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Si prega di definire la variabile d'ambiente LLMAAS_API_KEY.")
return
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Il contesto è l'informazione che il LLM è autorizzato a utilizzare.
context = """
Un cloud sovrano è un'infrastruttura di cloud computing che è interamente contenuta
entro i confini di un paese specifico e soggetta alle sue leggi.
I principali vantaggi sono la garanzia della residenza dei dati, la conformità con
le normative locali (come il GDPR in Europa), e una protezione accresciuta contro
l'accesso da parte di entità straniere in virtù di leggi extraterritoriali come il CLOUD Act americano.
"""
question = "Quali sono i vantaggi di un cloud sovrano ?"
# Il prompt guida il LLM affinché basi la sua risposta sul contesto fornito.
prompt = f"""
Basandoti esclusivamente sul contesto seguente, rispondi alla domanda.
Contesto:
---
{context}
---
Domanda: {question}
"""
payload = {
"model": "granite3.3:8b",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 200,
"temperature": 0.2 # Temperatura bassa per una risposta fattuale
}
try:
response = requests.post(
"https://api.ai.cloud-temple.com/v1/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
answer = result['choices'][0]['message']['content']
print(f"Domanda: {question}")
print("\nRisposta generata:\n", answer)
return answer
except requests.exceptions.RequestException as e:
print(f"Si è verificato un errore API: {e}")
if __name__ == "__main__":
haystack_simulation()
7. Integrazione LlamaIndex
LlamaIndex è un framework specializzato nella costruzione di applicazioni RAG. Offre componenti di alto livello per l'ingestione di dati, l'indicizzazione e l'interrogazione. La nostra API, essendo compatibile con l'interfaccia OpenAI, s'integra molto facilmente.
Codice Spiegato
Questo esempio mostra come configurare LlamaIndex per utilizzare l'API LLMaaS per la generazione di testo, utilizzando al contempo un modello di embedding locale per la vettorializzazione.
setup_and_run_llamaindex: Questa funzione unica orchestra l'intero processo.- Configurazione del LLM: LlamaIndex fornisce una classe
OpenAILikeche permette di connettersi a qualsiasi API che rispetti il formato OpenAI. Basta fornirle il nostroapi_basee unaapi_key. È il metodo più semplice per rendere il nostro LLM compatibile. - Configurazione degli Embedding: Per questo esempio, utilizziamo un modello di embedding locale (
HuggingFaceEmbedding). Questo mostra la flessibilità di LlamaIndex, che permette di mescolare i componenti. Potreste benissimo utilizzare la classeLLMaaSEmbeddingsdegli esempi precedenti per utilizzare la nostra API di embedding. Settings: L'oggettoSettingsdi LlamaIndex è un modo pratico per configurare i componenti predefiniti (LLM, modello di embedding, dimensione dei chunks, ecc.) che saranno utilizzati dagli altri oggetti LlamaIndex.- Ingestione dei dati:
SimpleDirectoryReadercarica i documenti di una cartella. - Creazione dell'indice:
VectorStoreIndex.from_documentsè il metodo di alto livello di LlamaIndex. Gestisce automaticamente la suddivisione in chunks, la vettorializzazione dei chunks (utilizzando l'embed_modelconfigurato inSettings), e la creazione dell'indice in memoria. - Motore di query:
.as_query_engine()crea un'interfaccia semplice per porre domande al nostro indice. Quando chiamate.query(), il motore vettorializza la vostra domanda, trova i documenti più pertinenti nell'indice, e li invia al LLM (configurato inSettings) con la domanda per generare una risposta.
- Configurazione del LLM: LlamaIndex fornisce una classe
# Dipendenze:
# pip install llama-index llama-index-llms-openai-like llama-index-embeddings-huggingface
import os
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai_like import OpenAILike
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import shutil
def setup_and_run_llamaindex():
"""
Configura ed esegue una pipeline RAG semplice con LlamaIndex e l'API LLMaaS.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Si prega di definire la variabile d'ambiente LLMAAS_API_KEY.")
return
# 1. Configurazione del LLM per utilizzare l'API LLMaaS tramite l'interfaccia OpenAILike
print("1. Configurazione del LLM per puntare all'API LLMaaS...")
llm = OpenAILike(
api_key=api_key,
api_base="https://api.ai.cloud-temple.com/v1",
model="granite3.3:8b",
is_chat_model=True,
# A volte è necessario aggiungere dei parametri di contesto per certi modelli
# context_window=3900,
)
# 2. Configurazione del modello di embedding (locale in questo esempio per semplicità)
print("2. Configurazione del modello di embedding locale...")
embed_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 3. Applicazione delle configurazioni globali tramite l'oggetto Settings di LlamaIndex
Settings.llm = llm
Settings.embed_model = embed_model
print(" -> LLM e modello di embedding configurati.")
# 4. Creazione di una base di conoscenza semplice in una directory temporanea
print("4. Creazione e caricamento di una base di conoscenza temporanea...")
temp_dir = "temp_llama_data"
os.makedirs(temp_dir, exist_ok=True)
knowledge_file = os.path.join(temp_dir, "knowledge.txt")
with open(knowledge_file, "w", encoding="utf-8") as f:
f.write("L'offerta LLMaaS di Cloud Temple è una soluzione di IA generativa sovrana, "
"interamente operata in Francia e qualificata SecNumCloud dall'ANSSI.")
documents = SimpleDirectoryReader(temp_dir).load_data()
print(f" -> {len(documents)} documento(i) caricato(i).")
# 5. Creazione dell'indice vettoriale. LlamaIndex gestisce il chunking e l'embedding.
print("5. Creazione dell'indice vettoriale...")
index = VectorStoreIndex.from_documents(documents)
print(" -> Indice creato.")
# 6. Creazione del motore di query e interrogazione della base di conoscenza
print("6. Creazione del motore di query e interrogazione...")
query_engine = index.as_query_engine()
question = "Quali sono le garanzie di sovranità dell'offerta LLMaaS ?"
response = query_engine.query(question)
print(f"\nDomanda: {question}")
print(f"Risposta: {response}")
# Pulizia della directory temporanea
shutil.rmtree(temp_dir)
print(f"\nDirectory temporanea '{temp_dir}' eliminata.")
if __name__ == "__main__":
setup_and_run_llamaindex()
8. Configurazione dell'estensione CLINE per VSCode
Questo tutorial vi guida nella configurazione dell'estensione CLINE in Visual Studio Code per utilizzare i modelli di linguaggio di Cloud Temple direttamente dal vostro editor.
Fasi di Configurazione
-
Aprire le impostazioni di CLINE: In VSCode, aprite le impostazioni dell'estensione CLINE.
-
Creare un nuovo modello: Aggiungete una nuova configurazione di modello.
-
Compilare i campi: Configurate i campi come segue, basandovi sull'immagine qui sotto.
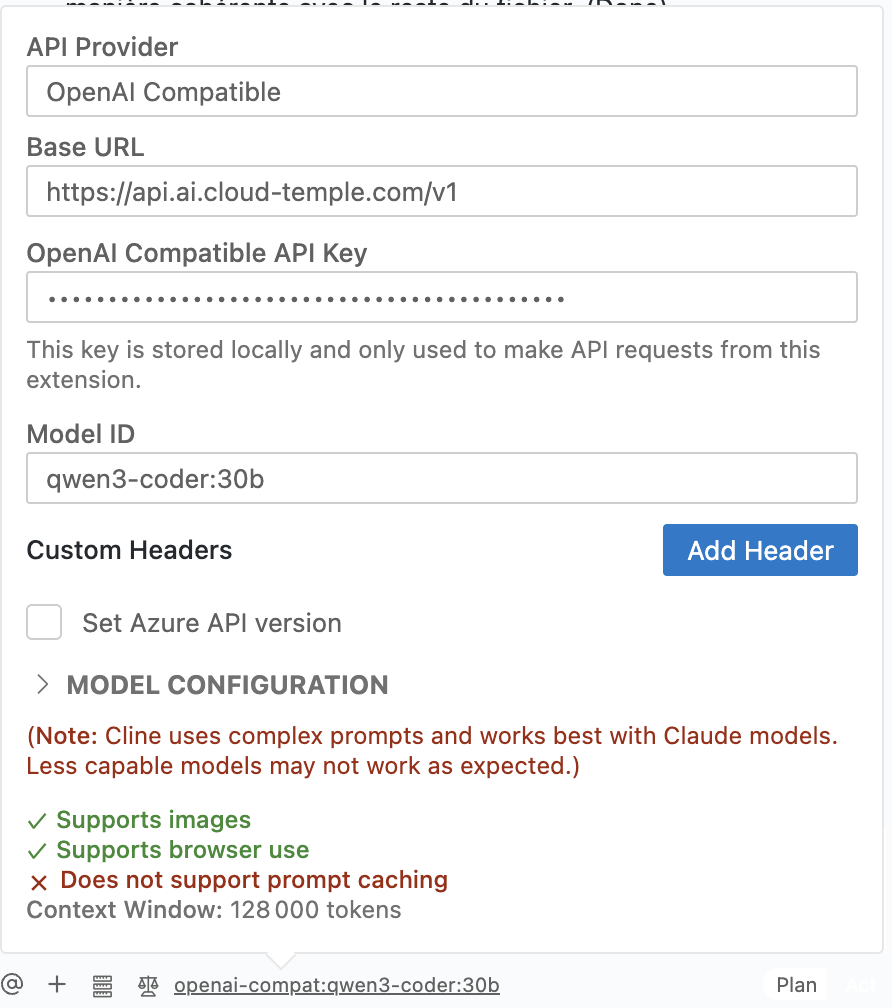
- API Provider: Selezionate
OpenAI Compatible. - Base URL: Inserite l'endpoint dell'API LLMaaS di Cloud Temple:
https://api.ai.cloud-temple.com/v1. - OpenAI Compatible API Key: Incollate la chiave API che avete generato dalla console Cloud Temple.
:::tip Generazione della chiave API Per generare la vostra chiave API, andate nella console Cloud Temple, sezione LLMaaS > Chiavi API, quindi cliccate su "Crea una chiave API".
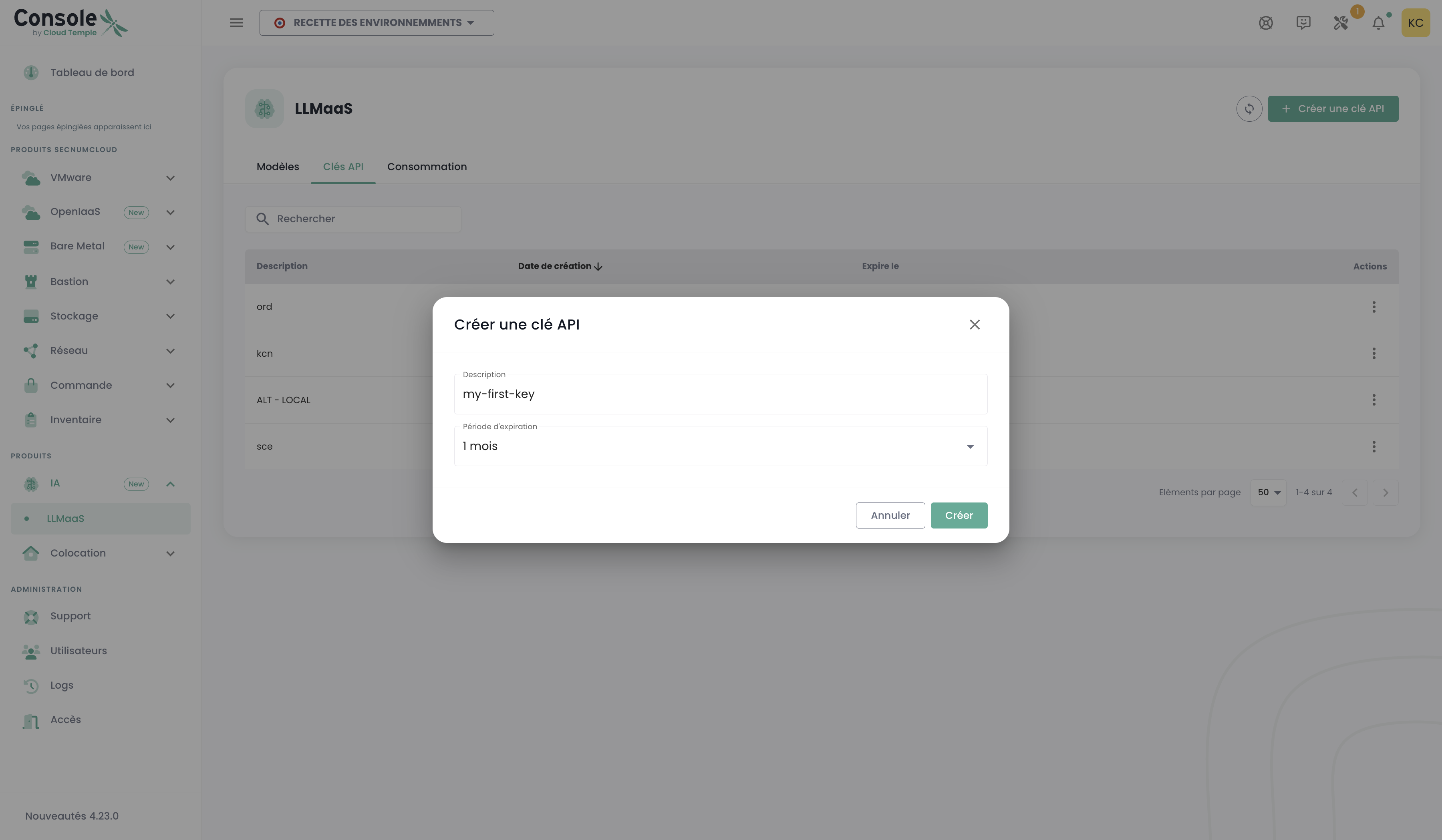 :::
:::- Model ID: Specificate il modello che desiderate utilizzare, ad esempio
qwen3-coder:30b. Potete trovare l'elenco dei modelli disponibili nella sezione Modelli. - Model Configuration:
- Supports Images: Spuntate questa casella se il modello supporta le immagini.
- Supports browser use: Spuntate questa casella.
- Context Window Size: Indicate la dimensione della finestra di contesto del modello (es:
128000). - Max Output Tokens: Lasciate a
-1per un'uscita non limitata per impostazione predefinita. - Temperature: Regolate la temperatura secondo le vostre necessità (es:
0).
- API Provider: Selezionate
Ora potete selezionare un modello in CLINE e utilizzarlo per generare codice, rispondere a domande, ecc.
💡 Esempi Avanzati
Troverete nella directory GitHub qui sotto una collezione di esempi di codice e di script che dimostrano le diverse funzionalità e i casi d'uso dell'offerta LLM as a Service (LLMaaS) di Cloud Temple :
Cloud-Temple/product-llmaas-how-to
Vi troverete guide pratiche per :
-
Estrazione di Informazioni e Analisi di Testo : Capacità di analizzare documenti per estrarne dati strutturati come entità, eventi, relazioni e attributi, basandosi su ontologie specifiche per settori (es: legale, RU, IT).
-
Interazione Conversazionale e Chatbot : Sviluppo di agenti conversazionali capaci di dialogare, di mantenere una cronologia degli scambi, di utilizzare istruzioni di sistema (prompt di sistema) e di invocare strumenti esterni.
-
Trascrizione Audio (Speech-to-Text) : Conversione di contenuti audio in testo, inclusi file voluminosi, grazie a tecniche di suddivisione, normalizzazione e elaborazione in lotti.
-
Traduzione di Testo : Traduzione di documenti da una lingua all'altra, gestendo il contesto su più segmenti per migliorare la coerenza.
-
Gestione e Valutazione dei Modelli : Elenco dei modelli di linguaggio disponibili tramite l'API, consultazione delle loro specifiche ed esecuzione di test per confrontare le loro prestazioni.
-
Streaming di Risposte in Tempo Reale : Dimostrazione della capacità di ricevere e visualizzare le risposte dei modelli in modo progressivo (token per token), essenziale per le applicazioni interattive.
-
Pipeline RAG con Base di Conoscenza in Memoria : Dimostratore RAG pedagogico per illustrare il funzionamento del Retrieval-Augmented Generation. Utilizza l'API LLMaaS per l'embedding e la generazione, con memorizzazione dei vettori in memoria (FAISS) per una comprensione chiara del processo.
-
Pipeline RAG con Database Vettoriale (Qdrant) : Dimostratore RAG completo e containerizzato che utilizza Qdrant come database vettoriale. L'API LLMaaS è utilizzata per l'embedding dei documenti e la generazione di risposte aumentate.
-
OCR & Analisi di Documenti (DeepSeek-OCR) : Guida completa e strumento di dimostrazione per convertire immagini e PDF in Markdown strutturato, estrarre tabelle e trascrivere formule matematiche. Vedere la documentazione dedicata.