Guida: Dominare l'OCR con DeepSeek
Questa guida dettaglia l'uso del modello DeepSeek-OCR, una soluzione di vanguardia per la compressione ottica di contesto e l'analisi di documenti.
Architettura e funzionamento
A differenza degli OCR tradizionali, DeepSeek-OCR è un modello di visione-linguaggio di estremo a estremo progettato per "leggere" e "comprendere" visivamente i documenti.
Architettura tecnica
Combina due componenti innovativi:
- DeepEncoder (380M): Un codificatore visuale ibrido che combina SAM-base (per la percezione locale) e CLIP-large (per la conoscenza globale), collegati mediante un compressore convoluzionale di 16x. Questo consente di processare immagini ad alta risoluzione con pochissimi token visuali.
- Decodificatore MoE (3B): Basato su DeepSeek3B-MoE (570M parametri attivi), genera testo strutturato a partire dai token visuali compressi.
Modos de resolución y consumo
Il modello adatta il suo consumo di token in base alla risoluzione dell'immagine. Maggiore è l'immagine, maggiore è il consumo di token, ma maggiore è anche la precisione.
| Modo | Risoluzione (px) | Token di visione | Uso raccomandato |
|---|---|---|---|
| Tiny | 512 x 512 | 64 | Diapositive, testo molto grande |
| Small | 640 x 640 | 100 | Documenti semplici, biglietti |
| Base | 1024 x 1024 | 256 | Pagine A4 standard |
| Large | 1280 x 1280 | 400 | Documenti densi, caratteri piccoli |
| Gundam | Dinamico | ~800 | Giornali, progetti, scansioni complesse |
Per ottimizzare i costi e la latenza, ridimensionate le immagini alla risoluzione minima necessaria affinché il testo rimanga leggibile.
Supporto multilingue
Il modello è stato addestrato su un vasto corpus di documenti multilingue e supporta il riconoscimento di quasi 100 lingue (tra cui francese, inglese, cinese, arabo, ecc.), con o senza conservazione del layout.
Guida ai prompt (Prompt engineering)
La qualità del risultato dipende direttamente dal prompt utilizzato. DeepSeek-OCR risponde a istruzioni specifiche per attivare le sue diverse capacità.
1. OCR standard (Markdown)
Per estrarre il testo con la sua struttura (titoli, paragrafi, tabelle).
Prompt:
Converti il documento in markdown.
Risultato: Testo strutturato, tabelle formattate, layout conservato.
2. "Analisi profonda" (Figure, grafici, formule)
Per analizzare il contenuto semantico di grafici, formule chimiche o geometriche.
Prompt:
Analizza la figura.
Capacità:
- Grafici (a barre/a linee/a torta) : Converte in tabella HTML o Markdown.
- Formule chimiche : Converte in formato SMILES.
- Geometria : Descrive gli elementi geometrici.
3. Grounding (localizzazione)
Per trovare le coordinate di un elemento specifico nell'immagine.
Prompt:
Localizza <|ref|>elemento da trovare<|/ref|> nell'immagine.
Esempio: Localizza <|ref|>Totale<|/ref|> nell'immagine.
Risultato: Restituisce le coordinate del riquadro di delimitazione (bounding box) dell'elemento.
4. Rilevamento di oggetti
Per elencare e localizzare tutti gli oggetti visibili.
Prompt:
Identifica tutti gli oggetti nell'immagine e visualizzali in riquadri di delimitazione.
Tutorial di implementazione (Python)
Ecco un esempio completo che mostra come strutturare la chiamata API per utilizzare queste funzionalità.
Prerequisiti: formato immagine e dipendenze
- Formato: JPEG o PNG.
- Modalità: RGB (nessuna trasparenza Alpha).
- PDF: Devono essere convertiti in immagini in anticipo (150-300 DPI).
- Dimensione: Si consiglia di ridimensionare le immagini ad altissima risoluzione per evitare errori di limite di dimensione (413 Payload Too Large).
Installare le librerie richieste:
pip install requests Pillow
Codice: Analisi documenti (OCR)
Prendiamo ad esempio questa ricevuta svizzera:

Ecco uno script robusto che gestisce il ridimensionamento e la codifica ottimale dell'immagine:
import base64
import io
import requests
from PIL import Image
# Configurazione
API_KEY = "IL_TUO_TOKEN_API"
API_URL = "https://api.ai.cloud-temple.com/v1/chat/completions"
IMAGE_PATH = "ReceiptSwiss.jpg" # Assicurati che l'immagine sia nella directory corrente
def encode_image_optimized(path):
"""
Ottimizza l'immagine (ridimensionamento + compressione JPEG) per l'API.
"""
with Image.open(path) as img:
# 1. Conversione RGB (per evitare problemi PNG/Alpha)
if img.mode != 'RGB':
img = img.convert('RGB')
# 2. Ridimensionamento intelligente se troppo grande (> 2048px)
# Questo previene errori 413 (Payload Too Large) e velocizza l'elaborazione
max_size = 2048
if max(img.size) > max_size:
img.thumbnail((max_size, max_size))
# 3. Compressione JPEG in memoria
buffer = io.BytesIO()
img.save(buffer, format="JPEG", quality=85)
return base64.b64encode(buffer.getvalue()).decode('utf-8')
# 1. Costruzione del messaggio multimodale
encoded_image = encode_image_optimized(IMAGE_PATH)
payload = {
"model": "deepseek-ai/DeepSeek-OCR",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Converti il documento in markdown." # Prompt OCR standard
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
}
}
]
}
],
"temperature": 0.0, # CRUCIALE: 0.0 per la fedeltà
"max_tokens": 4096
}
# 2. Invia
print("Invio della richiesta...")
response = requests.post(
API_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json=payload
)
# 3. Risultato
if response.status_code == 200:
print("\n--- Risultato OCR ---\n")
print(response.json()['choices'][0]['message']['content'])
else:
print(f"Errore {response.status_code}: {response.text}")
Esempio di output:
# Berghotel
**Grosse Scheidegg**
3818 Grindelwald
Famiglia R. Müller
N. fattura 4572
Bar Tavolo 7/01
2xLatte Macchiato a 4.50 CHF 9.00
1xGloki a 5.00 CHF 5.00
...
**Totale:** CHF **54.50**
**Incl. 7.6% IVA** 54.50 CHF: 3.85
### Codice: analisi grafica (analisi approfondita)
Per analizzare un grafico finanziario in un rapporto, è sufficiente modificare il testo del prompt nel payload sopra:
```python
# ... nel payload ...
"text": "Analizza la figura."
# ...
Il modello restituirà una rappresentazione testuale o tabellare dei dati del grafico.
Casi d'uso avanzati
Estrazione di tabelle complesse
DeepSeek-OCR eccelle nella conversione di tabelle, anche senza linee di demarcazione chiare.
Immagine di input:
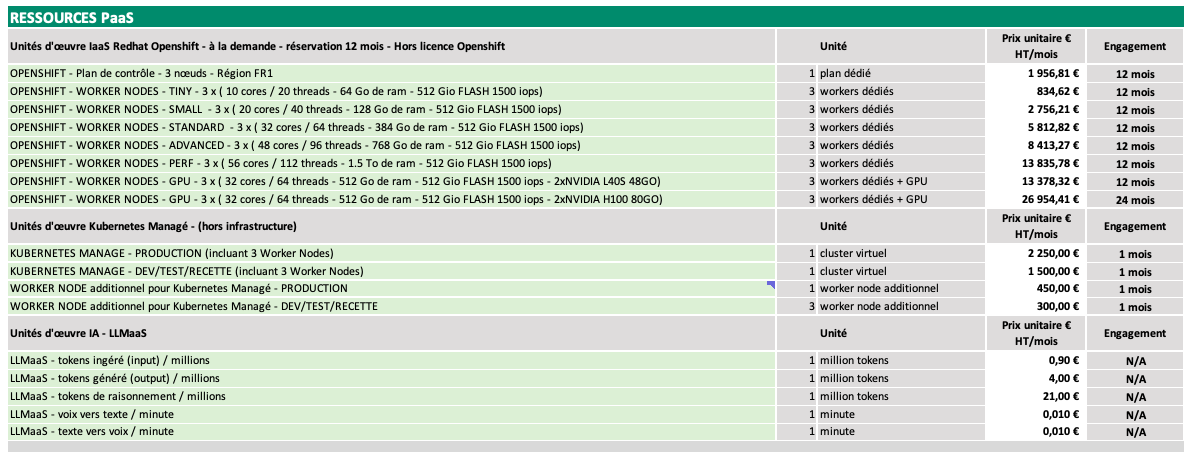
Output del modello (Prompt: "Convert the document to markdown table."):
# RISORSE PAAS
## Unità di lavoro laaS Redhat Openshift - su richiesta - prenotazione 12 mesi - Licenza Openshift esclusa
| | Unità | Prezzo unitario € IVA escl. / mese | Impegno |
|---|---|---|---|
| OPENSHIFT - Piano di controllo - 3 nodi - Regione FR1 | 1 piano dedicato | 1.956,81 € | 12 mesi |
| OPENSHIFT - NODI WORKER - TINY - 3 x (10 core / 20 thread - 64 GB di ram - 512 Gio FLASH 1500 ips) | 3 worker dedicati | 834,62 € | 12 mesi |
| OPENSHIFT - NODI WORKER - SMALL - 3 x (20 core / 40 thread - 128 GB di ram - 512 Gio FLASH 1500 ips) | 3 worker dedicati | 2.756,21 € | 12 mesi |
| OPENSHIFT - NODI WORKER - STANDARD - 3 x (32 core / 64 thread - 384 GB di ram - 512 Gio FLASH 1500 ips) | 3 worker dedicati | 5.812,82 € | 12 mesi |
| OPENSHIFT - NODI WORKER - ADVANCED - 3 x (48 core / 96 thread - 768 GB di ram - 512 Gio FLASH 1500 ips) | 3 worker dedicati | 8.413,27 € | 12 mesi |
| OPENSHIFT - NODI WORKER - PERF - 3 x (56 core / 112 thread - 1.5 TB di ram - 512 Gio FLASH 1500 ips) | 3 worker dedicati | 13.835,78 € | 12 mesi |
| OPENSHIFT - NODI WORKER - GPU - 3 x (32 core / 64 thread - 512 GB di ram - 512 Gio FLASH 1500 ips - 2xNVIDIA L40S 48GB) | 3 worker dedicati + GPU | 13.378,32 € | 12 mesi |
| OPENSHIFT - NODI WORKER - GPU - 3 x (32 core / 64 thread - 512 GB di ram - 512 Gio FLASH 1500 ips - 2xNVIDIA H100 80GB) | 3 worker dedicati + GPU | 26.954,41 € | 24 mesi |
## Unità di lavoro Kubernetes Manage - (esclusa l'infrastruttura)
| | Unità | Prezzo unitario € IVA esclusa/mese | Impegno |
|---|---|---|---|
| KUBERNETES MANAGE - PRODUZIONE (include 3 nodi worker) | 1 cluster virtuale | 2.250,00 € | 1 mese |
| KUBERNETES MANAGE - SVILUPPO/TEST/COLLAUDO (include 3 nodi worker) | 1 cluster virtuale | 1.500,00 € | 1 mese |
| NODO WORKER aggiuntivo per Kubernetes Manage - PRODUZIONE | 1 nodo worker aggiuntivo | 450,00 € | 1 mese |
| NODO WORKER aggiuntivo per Kubernetes Manage - SVILUPPO/TEST/COLLAUDO | 3 nodi worker aggiuntivi | 300,00 € | 1 mese |
## Unità di lavoro IA - LLMaaS
| | Unità | Prezzo unitario € IVA escl. / mese | Impegno |
|---|---|---|---|
| LLMaaS - token in ingresso / milioni | 1 milione di token | 0,90 € | N/A |
| LLMaaS - token in uscita / milioni | 1 milione di token | 4,00 € | N/A |
| LLMaaS - token di ragionamento / milioni | 1 milione di token | 21,00 € | N/A |
| LLMaaS - voce-testo / minuto | 1 minuto | 0,010 € | N/A |
| LLMaaS - testo-voce / minuto | 1 minuto | 0,010 € | N/A |
### Formule matematiche (LaTeX)
Ideale per documenti accademici. Il modello riconosce le equazioni e le esporta in sintassi LaTeX standard.
**Immagine di input:**

**Output del modello (Prompt: "Convert to latex.") :**
> Ecco il rendering matematico del risultato OCR:
Errore quadratico medio:
$$
\frac{1}{T} \int_{-T/2}^{T/2} \left[ f(t) - T_N(t) \right]^2 dt = E_N \left( a_0, \ldots, a_N; b_1, \ldots, b_N \right)
$$
Condizione per il minimo di $E_N$:
$$
\frac{\partial E_N}{\partial a_0} = 0, \frac{\partial E_N}{\partial a_i} = 0, \ldots, \frac{\partial E_N}{\partial b_N} = 0
$$
(2n+1) equazioni:
$$
\frac{\partial E_N}{\partial a_i} = \frac{1}{T} \int_{-T/2}^{T/2} \frac{\partial}{\partial a_i} \left( f(t) - T_N(t) \right)^2 dt = \frac{1}{T} \int_{-T/2}^{T/2} \left\{ 2 \left( f(t) - T_N(t) \right) \frac{\partial}{\partial a_i} \left( f(t) - T_N(t) \right) \right\} dt
$$
$$
= -\frac{1}{T} \int_{-T/2}^{T/2} 2 \left( f(t) - T_N(t) \right) \cos i \omega t dt = 0 \quad \text{per punto stazionario.}
$$
$$
\frac{2}{T} \int_{-T/2}^{T/2} f(t) \cos i \omega t dt = \frac{2}{T} \int_{-T/2}^{T/2} \left[ \frac{a_0}{2} + \sum_{n=1}^{N} \left( a_n \cos n \omega t + b_n \sin n \omega t \right) \right] \cos i \omega t dt \quad i \neq 0
$$
## Limitazioni note
- **Orientamento**: Il modello non gestisce la rotazione automatica. Assicurati che le tue immagini siano correttamente orientate (testo orizzontale).
- **Testo manoscritto**: Sebbene sia efficiente, il tasso di errore è più elevato sulla scrittura corsiva complessa rispetto al testo stampato.
- **Risoluzione molto alta**: Le immagini che superano le dimensioni della modalità "Gundam" (~2000x2000) vengono ridimensionate, il che può rendere il testo microscopico illeggibile. Dividi le immagini molto grandi in più parti.