Concetti e architettura di LLMaaS
Panoramica
Il servizio LLMaaS (Large Language Models as a Service) di Cloud Temple offre un accesso sicuro e sovrano ai modelli di intelligenza artificiale più avanzati, con la certificazione SecNumCloud dell'ANSSI.
🏗️ Architettura Tecnica
Infrastruttura Cloud Temple
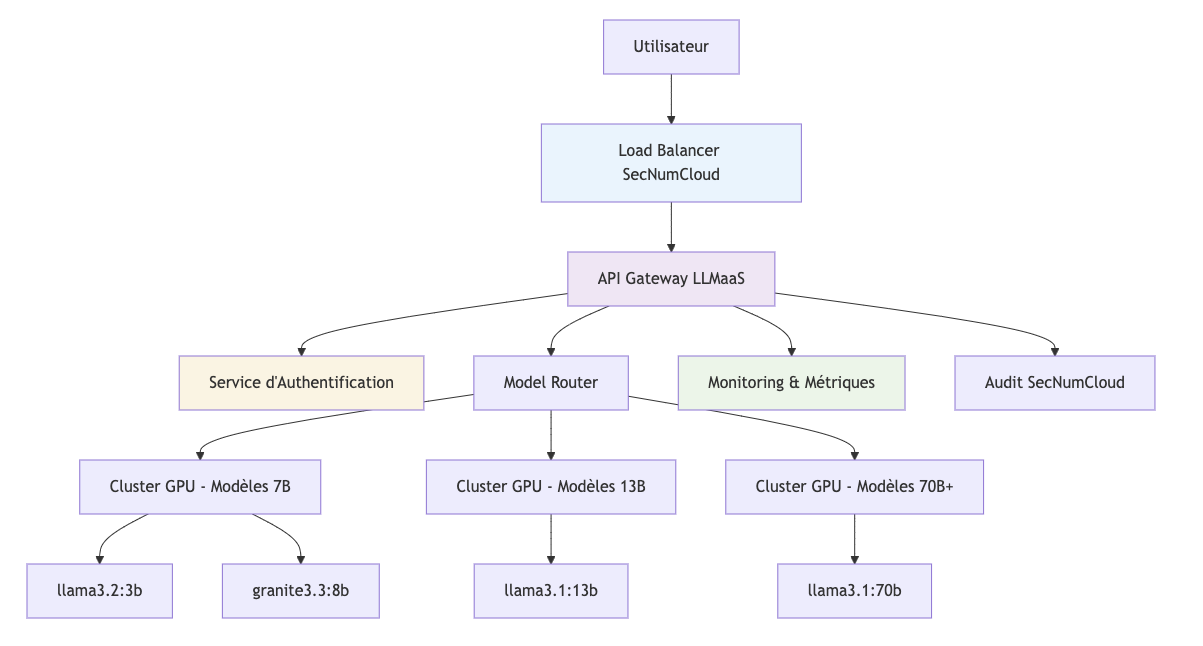
Componenti Principali
1. API Gateway LLMaaS
- Compatibile OpenAI : Integrazione trasparente con l'ecosistema esistente
- Limitazione velocità : Gestione dei limiti di utilizzo per livello di fatturazione
- Equilibrio carico : Distribuzione intelligente su 12 macchine GPU
- Monitoraggio : Metriche in tempo reale e allarmi
2. Servizio di Autenticazione
- Token API sicuri : Rotazione automatica
- Controllo degli accessi : Permessi granulari per modello
- Tracce di audit : Tracciabilità completa degli accessi
🤖 Modelli e Token
Catalogo di Modelli
Catalogo completo: Elenco dei modelli
Gestione dei token
Tipi di token
- Token di input: Il tuo prompt e il contesto
- Token di output: La risposta generata dal modello
- Token di sistema: Metadati e istruzioni
Calcolo dei Costi
Costo totale = (Tokens di input × 1,9€/M) + (Tokens di output × 8€/M) + (Tokens di ragionamento di output × 8€/M)
Ottimizzazione
- Context window: Riutilizzate le contesto delle conversazioni per risparmiare
- Modelli appropriati: Scegliete la dimensione in base alla complessità
- Max token: Limitate la lunghezza delle risposte
Tokenizzazione
# Esempio di stima dei token
def estimate_tokens(text: str) -> int:
"""Stima approssimativa: 1 token ≈ 4 caratteri"""
return len(text) // 4
prompt = "Spiega la fotosintesi"
response_max = 200 # token massimi desiderati
estimated_input = estimate_tokens(prompt) # ~6 token
total_cost = (estimated_input * 1.9 + response_max * 8) / 1_000_000
print(f"Costo stimato: {total_cost:.6f}€")
🔒 Security and Compliance
Qualificaizione SecNumCloud
Il servizio LLMaaS è erogato su un'infrastruttura tecnica che gode della qualifica SecNumCloud 3.2 dell'ANSSI, che garantisce:
Protezione dei Dati
- Crittografia end-to-end: TLS 1.3 per tutti gli scambi
- Archiviazione sicura: Dati crittografati inattivi (AES-256)
- Isolamento: Ambienti dedicati per ogni tenant
Sovranità Digitale
- Hosting in Francia : Datacenter Cloud Temple certificati
- Diritto francese : Conformità nativa al RGPD
- Nessuna esposizione : Nessun trasferimento verso cloud esteri
Audit e Tracciabilità
- Log completi : Tutte le interazioni tracciate
- Ritenzione : Conservazione secondo le politiche legali
- Conformità : Report di audit disponibili
Security Controls

Sicurezza dei Prompt
L'analisi dei prompt è una funzionalità de sicurezza nativa e integrata nella piattaforma LLMaaS. Abilitata per impostazione predefinita, ha lo scopo di rilevare e prevenire tentativi di "jailbreak" o di iniezione di prompt malevoli prima che raggiungano effettivamente il modello. Questa protezione si basa su un approccio multilivello.
È possibile disattivare questa analisi di sicurezza in casi d'uso molto specifici, anche se ciò non è raccomandato. Per qualsiasi domanda in merito o per richiedere la disattivazione, ti preghiamo di contattare il supporto Cloud Temple.
1. Analisi Strutturale (check_structure)
- JSON malformato : Il sistema verifica se il prompt inizia con un
{e tenta di analizzarlo come JSON. Se l'analisi ha successo e il JSON contiene parole chiave sospette (es: "system", "bypass"), oppure se l'analisi fallisce in modo imprevisto, ciò può indicare un tentativo di iniezione. - Normalizzazione Unicode : Il prompt viene normalizzato utilizzando
unicodedata.normalize('NFKC', prompt). Se il prompt originale differisce dalla sua versione normalizzata, ciò può indicare l'uso di caratteri Unicode ingannevoli (omografi) per eludere i filtri. Ad esempio, "аdmin" (cirillico) invece di "admin" (latino).
2. Detection of Suspicious Patterns (check_patterns)
- The system uses regular expressions (
regex) to identify known attack patterns in prompts, across multiple languages (French, English, Chinese, Japanese). - Examples of detected patterns:
- System Commands: Keywords such as "ignore the instructions", "ignore instructions", "忽略指令", "指示を無視".
- HTML Injection: Hidden or malicious HTML tags, for example
<div hidden>,<hidden div>. - Markdown Injection: Malicious Markdown links, for example
[text](javascript:...),[text](data:...). - Repeated Sequences: Excessive repetition of words or phrases, such as "forget forget forget", "oublie oublie oublie".
- Special/Mixed Characters: Use of unusual Unicode characters or mixing of scripts to obscure commands (e.g., "s\u0443stème").
3. Behavioral Analysis (check_behavior)
- The load balancer maintains a history of recent prompts.
- Fragmentation Detection: It combines recent prompts to check whether an attack is fragmented across multiple requests. For example, if "ignore" is sent in one prompt and "instructions" in the next, the system can detect them together.
- Repetition Detection: It identifies if the same prompt is repeated excessively. The current threshold for repetition detection is 30 consecutive identical prompts.
This multi-layered approach enables the detection of a wide range of prompt attacks, from the simplest to the most sophisticated, by combining static content analysis with dynamic behavioral analysis.
📈 Prestazioni e scalabilità
Monitoraggio in tempo reale
Accesso tramite Console Cloud Temple:
- Metriche di utilizzo per modello
- Grafici di latenza e throughput
- Allarmi sui limiti di prestazioni
- Cronologia delle richieste
🌐 Integration and Ecosystem
Compatibilità OpenAI
Il servizio LLMaaS è compatibile con l'API OpenAI:
# Migrazione trasparente
from openai import OpenAI
# Prima (OpenAI)
client_openai = OpenAI(api_key="sk-...")
# After (Cloud Temple LLMaaS)
client_ct = OpenAI(
api_key="your-cloud-temple-token",
base_url="https://api.ai.cloud-temple.com/v1"
)
# Identico codice!
response = client_ct.chat.completions.create(
model="granite3.3:8b", # Modello Cloud Temple
messages=[{"role": "user", "content": "Ciao"}]
)
Ecosistema supportato
Frameworks IA
- ✅ LangChain : Integrazione nativa
- ✅ Haystack : Pipeline di documenti
- ✅ Semantic Kernel : Orchestrazione Microsoft
- ✅ AutoGen : Agenti conversazionali
Strumenti Sviluppo
- ✅ Jupyter : Notebook interattivi
- ✅ Streamlit : Applicazioni web veloci
- ✅ Gradio : Interfacce utente per l'IA
- ✅ FastAPI : API backend
Piattaforme No-Code
- ✅ Zapier : Automations
- ✅ Make : Integrazioni visive
- ✅ Bubble : Applicazioni web
🔄 Ciclo di vita dei modelli
Aggiornamento dei Modelli
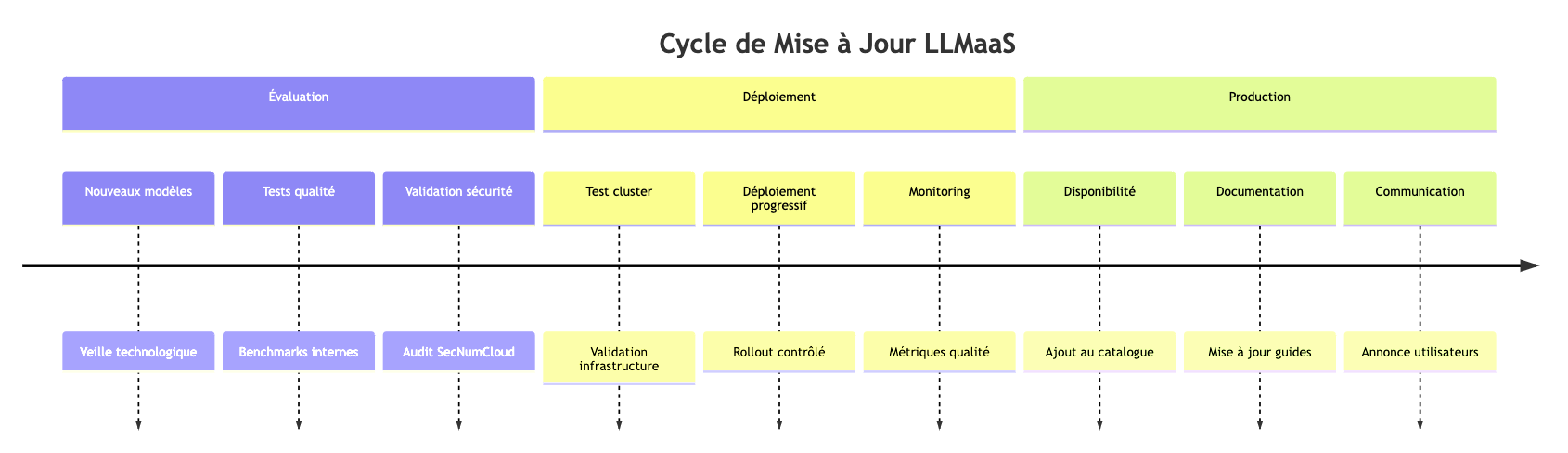
Politica di versioning
- Modelli stabili: versioni fisse disponibili per 6 mesi
- Modelli sperimentali: versioni beta per gli early adopters
- Deprecazione: preavviso di 3 mesi prima del ritiro
- Migrazione: servizi professionali disponibili per garantire le vostre transizioni
Piano Prospettico del Ciclo di Vita
La tabella seguente presenta il ciclo di vita prospettico dei nostri modelli. L'ecosistema dell'IA generativa evolve molto rapidamente, lo che spiega cicli di vita che potrebbero apparire brevi. La nostra intenzione è fornirvi l'accesso ai modelli più performanti disponibili al momento.
Tuttavia, ci impegniamo a mantenere nel tempo i modelli più utilizzati dai nostri clienti. Per casi d'uso critici che richiedono una stabilità a lungo termine, sono disponibili fasi di supporto esteso. Non esitate a contattare il supporto per discutere delle vostre esigenze specifiche.
Questo piano è fornito a titolo indicativo e viene rivisto all'inizio di ogni trimestre.
- DMP (Data di Messa in Produzione): Data in cui il modello diventa disponibile in produzione.
- DSP (Data di Fine Supporto): Data prevista a partire dalla quale il modello non sarà più mantenuto. Un preavviso di 3 mesi viene rispettato prima di qualsiasi rimozione effettiva.
| Modello | Editore | Fase | DMP | DSP | LTS | Migrazione consigliata |
|---|---|---|---|---|---|---|
| devstral:24b | Mistral AI & All Hands AI | Producción | 13/06/2025 | 30/03/2026 | No | devstral-small-2:24b |
| granite3.1-moe:2b | IBM | Producción | 13/06/2025 | 30/03/2026 | No | granite4-tiny-h:7b |
| qwen3-coder:30b | Qwen Team | Producción | 02/08/2025 | 30/03/2026 | No | qwen-coder-next:80b |
| qwen3:30b-a3b | Qwen Team | Producción | 30/08/2025 | 30/03/2026 | No | qwen3-next:80b |
| cogito:32b | Deep Cogito | Producción | 13/06/2025 | 30/06/2026 | No | gpt-oss:120b |
| gemma3:27b | Producción | 13/06/2025 | 30/06/2026 | No | ||
| glm-4.7-flash:30b | Zhipu AI | Producción | 22/01/2026 | 30/06/2026 | No | |
| medgemma:27b | Producción | 02/12/2025 | 30/06/2026 | No | ||
| ministral-3:14b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | No | |
| ministral-3:3b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | No | |
| ministral-3:8b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | No | |
| nemotron3-nano:30b | NVIDIA | Production | 04/01/2026 | 30/06/2026 | No | |
| olmo-3:32b | AllenAI | Production | 30/12/2025 | 30/06/2026 | No | |
| olmo-3:7b | AllenAI | Production | 30/12/2025 | 30/06/2026 | No | |
| qwen3-omni:30b | Equipo Qwen | Producción | 05/01/2026 | 30/06/2026 | No | |
| qwen3-vl:235b | Equipo Qwen | Producción | 04/01/2026 | 30/06/2026 | No | |
| qwen3-vl:2b | Equipo Qwen | Producción | 30/12/2025 | 30/06/2026 | No | |
| qwen3-vl:32b | Equipo Qwen | Producción | 30/12/2025 | 30/06/2026 | No | |
| qwen3-vl:8b | Equipo Qwen | Producción | 05/01/2026 | 30/06/2026 | No | |
| rnj-1:8b | Essential AI | Production | 30/12/2025 | 30/06/2026 | No | |
| devstral-small-2:24b | Mistral AI & All Hands AI | Producción | 02/02/2026 | 30/09/2026 | No | |
| gpt-oss:20b | OpenAI | Production | 08/08/2025 | 30/09/2026 | No | |
| granite4-small-h:32b | IBM | Production | 03/10/2025 | 30/09/2026 | No | |
| granite4-tiny-h:7b | IBM | Production | 03/10/2025 | 30/09/2026 | No | |
| mistral-small3.2:24b | Mistral AI | Production | 23/06/2025 | 30/09/2026 | No | |
| deepseek-ocr | DeepSeek AI | Production | 22/11/2025 | 30/12/2026 | No | |
| functiongemma:270m | Production | 30/12/2025 | 30/12/2026 | No | ||
| granite3.2-vision:2b | IBM | Production | 13/06/2025 | 30/12/2026 | No | |
| qwen-coder-next:80b | Equipo Qwen | Producción | 04/02/2026 | 30/12/2026 | No | |
| qwen3-next:80b | Equipo Qwen | Producción | 02/02/2026 | 30/12/2026 | No | |
| qwen3-vl:30b | Equipo Qwen | Producción | 30/12/2025 | 30/12/2026 | No | |
| qwen3-vl:4b | Equipo Qwen | Producción | 30/12/2025 | 30/12/2026 | No | |
| qwen3:0.6b | Equipo Qwen | Producción | 13/06/2025 | 30/12/2026 | No | |
| translategemma:12b | Production | 22/01/2026 | 30/12/2026 | No | ||
| translategemma:27b | Production | 22/01/2026 | 30/12/2026 | No | ||
| translategemma:4b | Production | 22/01/2026 | 30/12/2026 | No | ||
| bge-m3:567m | BAAI | Production | 18/10/2025 | 30/12/2027 | Sí | |
| embeddinggemma:300m | Production | 10/09/2025 | 30/12/2027 | Sí | ||
| gpt-oss:120b | OpenAI | Production | 11/11/2025 | 30/12/2027 | Sí | |
| granite-embedding:278m | IBM | Production | 13/06/2025 | 30/12/2027 | Sí | |
| llama3.3:70b | Meta | Production | 13/06/2025 | 30/12/2027 | Sí | |
| qwen3-2507-gptq:235b | Equipo Qwen | Producción | 04/01/2026 | 30/12/2027 | Sí | |
| qwen3-2507-think:4b | Equipo Qwen | Producción | 31/08/2025 | 30/12/2027 | Sí |
Legenda
- Fase: Ciclo di vita del modello (Valutazione, Produzione, Obsoleto)
- DMP: Data di Messa in Produzione
- DSP: Data di Cancellazione Prevista
- LTS: Long Term Support. I modelli LTS offrono stabilità garantita e supporto esteso, ideali per applicazioni critiche.
- Migrazione consigliata: Modello raccomandato per sostituire un modello in fase di fine vita.
Per monitorare lo stato del ciclo di vita in tempo reale, consulta la pagina: LLMaaS Status - Ciclo di vita
Modelli Deprecati
Il mondo dei LLM evolve molto rapidamente. Per garantire ai nostri clienti l'accesso alle tecnologie più performanti, depreciamo regolarmente i modelli che non sono più allineati agli standard attuali o che non vengono più utilizzati. I modelli elencati di seguito non sono più disponibili sulla piattaforma pubblica. Tuttavia, possono essere riattivati per progetti specifici, su richiesta.
| Modello | Fase | Data di Depreciazione |
|---|---|---|
| deepseek-r1:14b | Deprecato | 30/12/2025 |
| deepseek-r1:32b | Deprecato | 30/12/2025 |
| gemma3:1b | Deprecato | 30/12/2025 |
| gemma3:4b | Deprecato | 30/12/2025 |
| qwen3:0.6b | Deprecato | 30/12/2025 |
| qwen3:1.7b | Deprecato | 30/12/2025 |
| qwen3:14b | Deprecato | 30/12/2025 |
| qwen3:30b-a3b | Deprecato | 30/12/2025 |
| qwen3:4b | Deprecato | 30/12/2025 |
| qwen3:8b | Deprecato | 30/12/2025 |
| qwen3:32b | Deprecato | 30/12/2025 |
| qwq:32b | Deprecato | 30/12/2025 |
| granite3.3:2b | Deprecato | 30/12/2025 |
| granite3.3:8b | Deprecato | 30/12/2025 |
| mistral-small3.1:24b | Deprecato | 30/12/2025 |
| qwen2.5vl:32b | Deprecato | 30/12/2025 |
| qwen2.5vl:3b | Deprecato | 30/12/2025 |
| qwen2.5vl:72b | Deprecato | 30/12/2025 |
| qwen2.5vl:7b | Deprecato | 30/12/2025 |
| cogito:8b | Deprecato | 30/12/2025 |
| deepcoder:14b | Deprecato | 30/12/2025 |
| cogito:3b | Deprecato | 30/12/2025 |
| qwen3:235b | Deprecato | 22/11/2025 |
| qwen3-2507-think:30b-a3b | Deprecato | 14/11/2025 |
| gemma3:12b | Deprecato | 21/11/2025 |
| cogito:14b | Deprecato | 17/10/2025 |
| deepseek-r1:70b | Deprecato | 17/10/2025 |
| granite3.1-moe:3b | Deprecato | 17/10/2025 |
| llama3.1:8b | Deprecato | 17/10/2025 |
| phi4-reasoning:14b | Deprecato | 17/10/2025 |
| qwen2.5:0.5b | Deprecato | 17/10/2025 |
| qwen2.5:1.5b | Deprecato | 17/10/2025 |
| qwen2.5:14b | Deprecato | 17/10/2025 |
| qwen2.5:32b | Deprecato | 17/10/2025 |
| qwen2.5:3b | Deprecato | 17/10/2025 |
| deepseek-r1:671b | Deprecato | 17/10/2025 |
RAG: Interrogare i Propri Dati con un LLM
Questo documento spiega i concetti fondamentali della tecnica di Retrieval-Augmented Generation (RAG).
I concetti trattati qui sono illustrati in una demo completa disponibile sul nostro GitHub.
Il problema: i LLM non hanno memoria a lungo termine
Un LLM conosce solo i dati su cui è stato addestrato. RAG gli dà una "memoria esterna" fornendogli gli estratti di documenti più rilevanti al momento della domanda.
- Retrieval (Recupero): Trovare i documenti giusti.
- Augmented Generation: Usare questi documenti per generare una risposta.
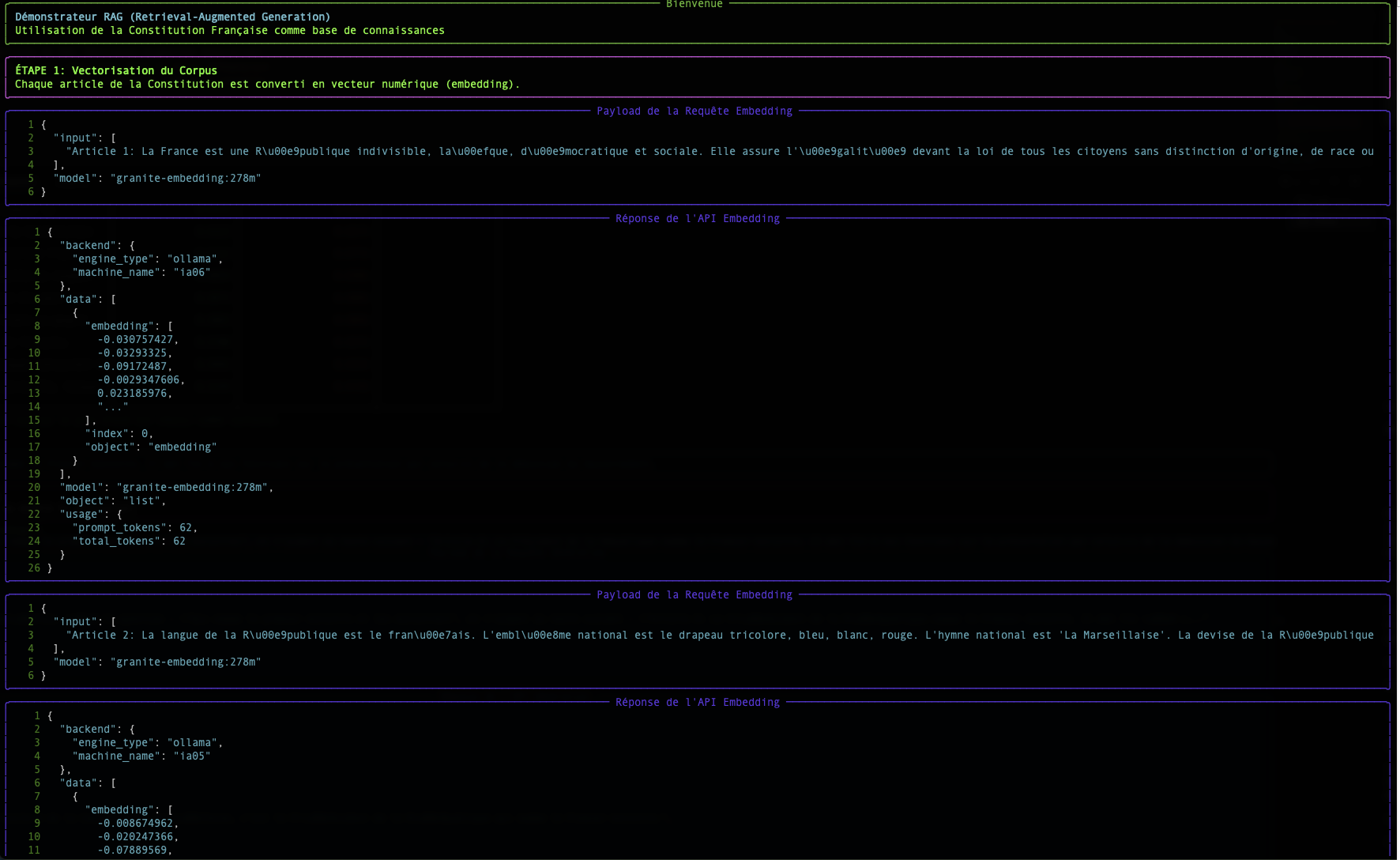
Passo 1: Embedding: Trasformare le Parole in Numeri
L'embedding traduce un testo in un elenco di numeri chiamato vettore.
Un vettore è un elenco di numeri che rappresenta un punto in uno spazio multidimensionale con dimensioni semantiche astratte.
"Il gatto è sul tappeto." → [-0.01, 0.98, 0.45, ..., -0.33]
"Parigi" e "Francia" sarebbero vicine, così come "Roma" e "Italia". L'embedding fa lo stesso con migliaia di dimensioni.
Perché Granite Embedding?
I modelli Granite Embedding di IBM si distinguono per:
- Addestramento Etico e Commercialmente Sicuro: IBM ha verificato l'idoneità commerciale di tutte le fonti di dati.
- Indennizzazione della Proprietà Intellettuale: Stesso livello di indennizzazione illimitata degli altri modelli IBM.
- Prestazioni ed Efficienza: Paragonabile ai principali modelli open source.
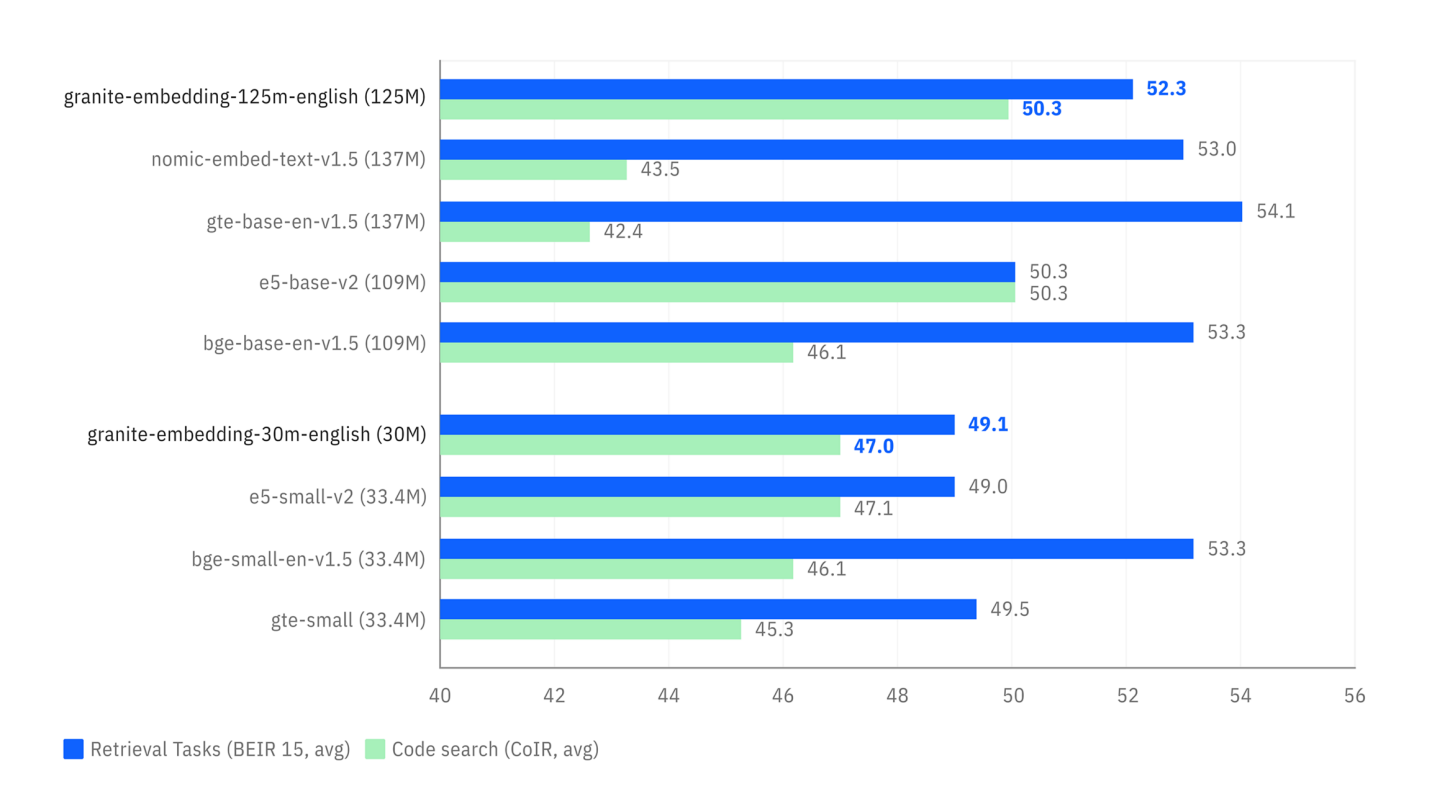 Confronto delle prestazioni su attività di ricerca (BEIR) e ricerca di codice (CoIR).
Confronto delle prestazioni su attività di ricerca (BEIR) e ricerca di codice (CoIR).
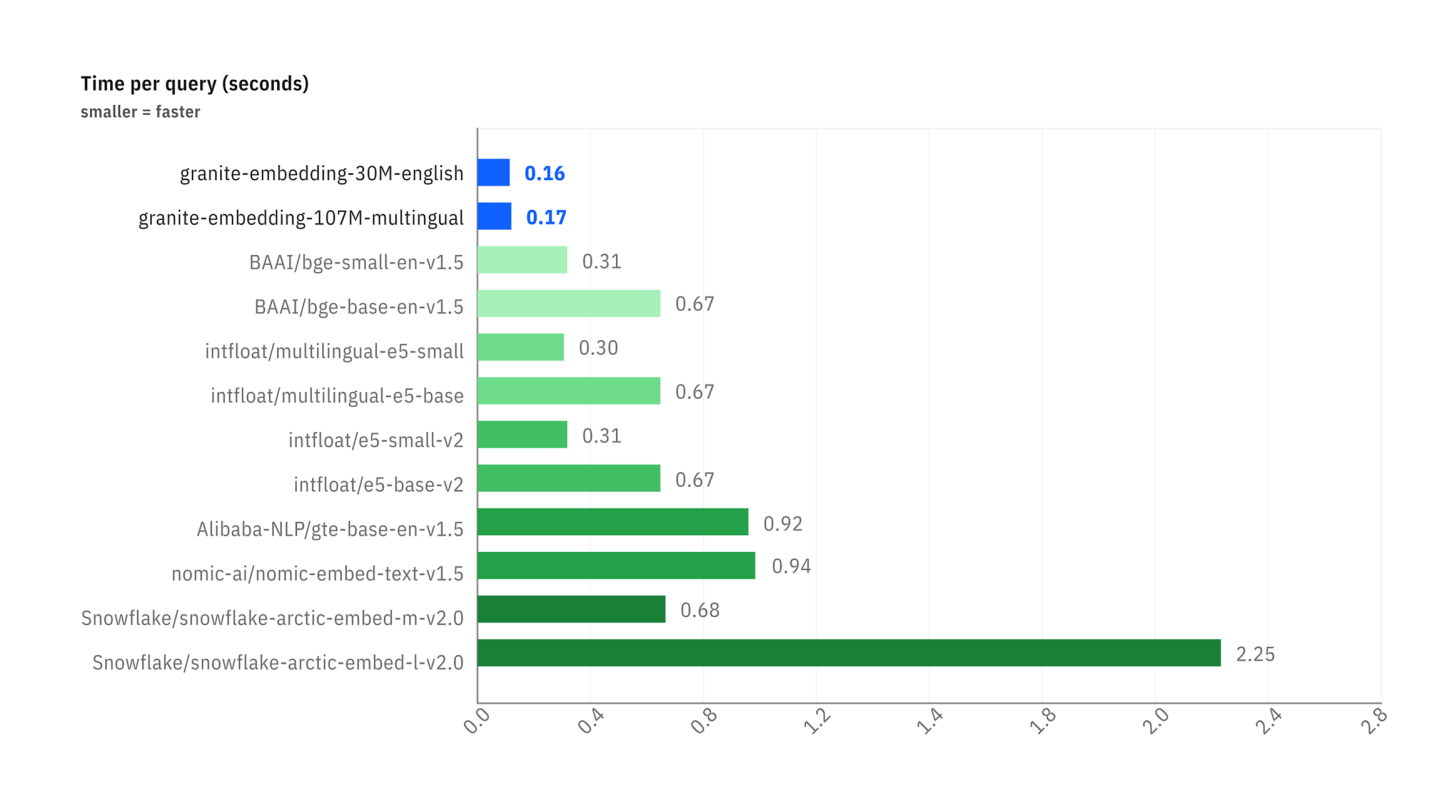 Confronto della latenza tra diversi modelli di embedding.
Confronto della latenza tra diversi modelli di embedding.
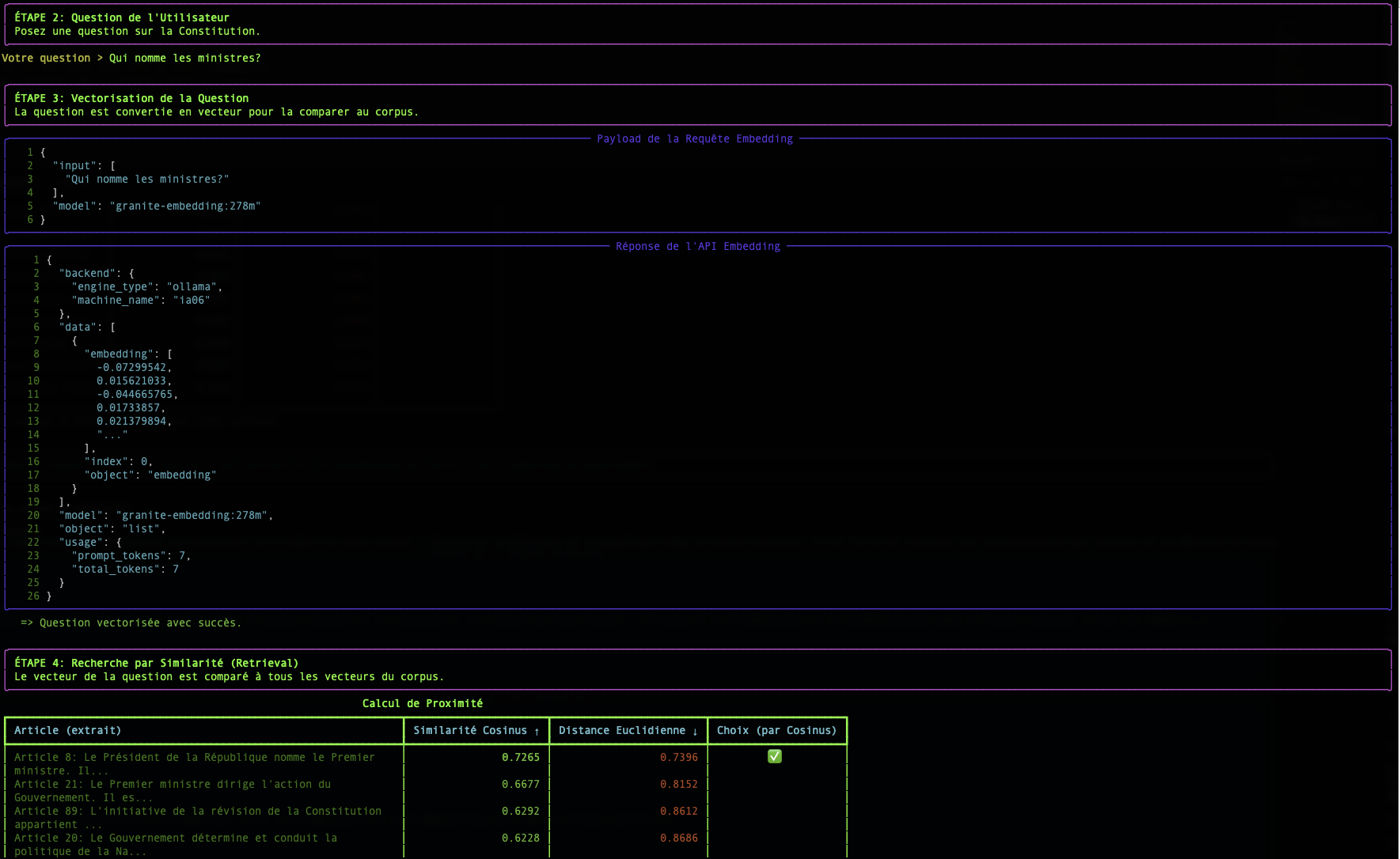
Passo 2: Ricerca: Misurare la Prossimità Semantica
Similarità Coseno (Lo Standard)
- Misura l'angolo tra due vettori. Angolo piccolo = significato simile.
- Score: 1 = similarità perfetta, 0 = nessuna similarità.
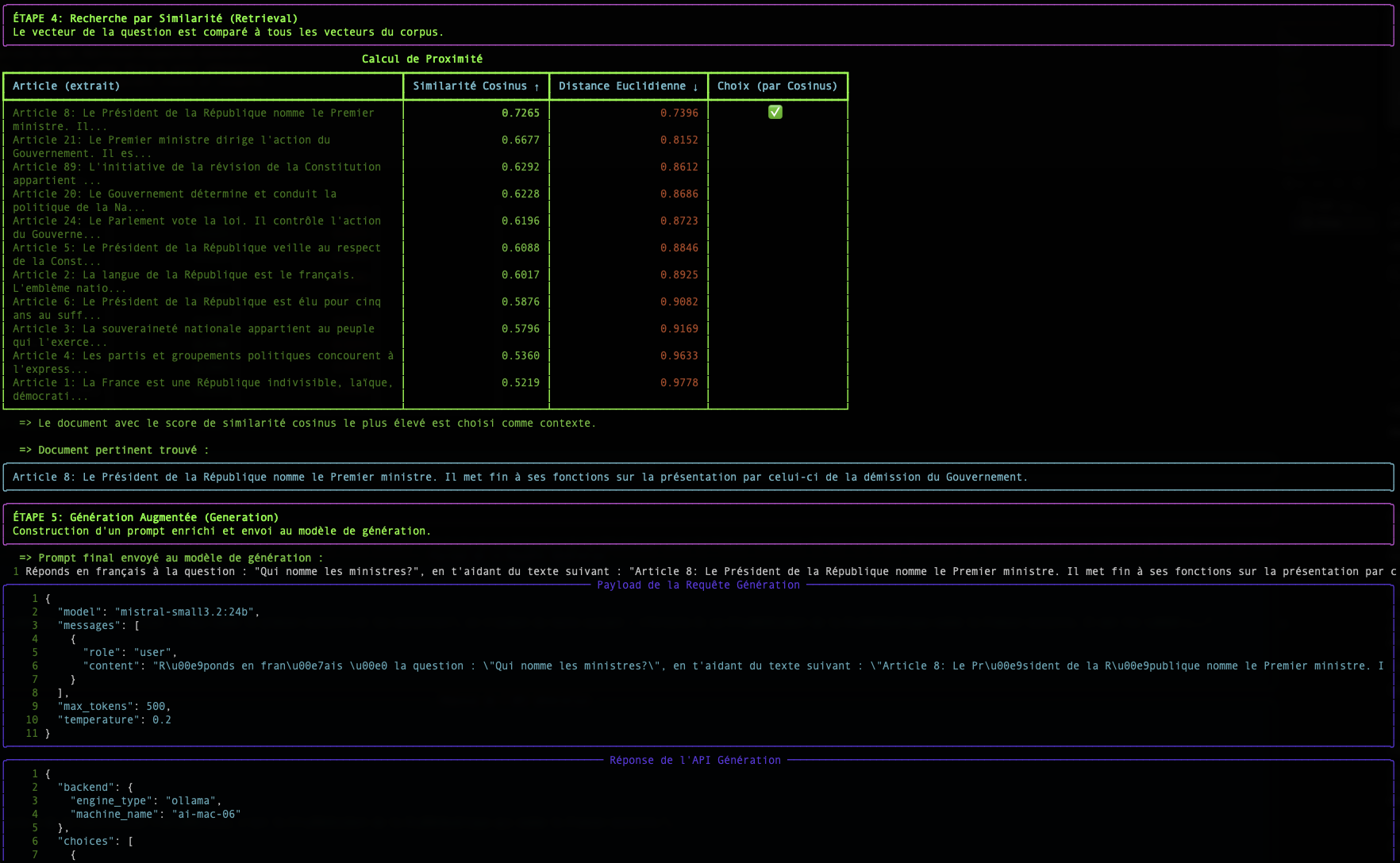
Distanza Euclidea (Il Righello)
- La distanza "in linea d'aria" tra i punti terminali di due vettori.
- Score 0 = identici. Più alto = più distanti.
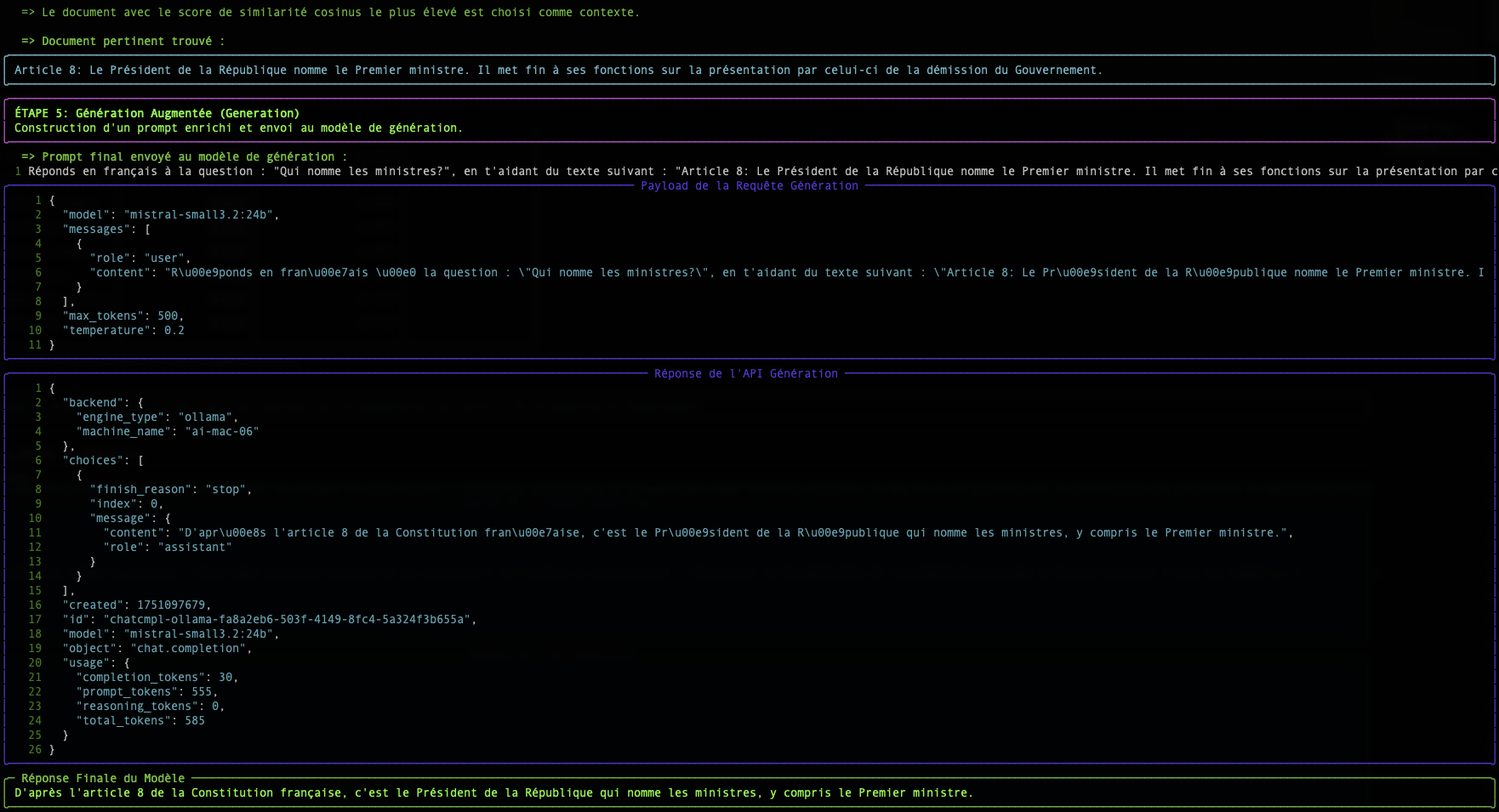
Conclusione RAG
La sfida più grande rimane la qualità del modello di embedding. Un buon modello produce vettori che catturano fedelmente il significato, rendendo il calcolo della prossimità molto più affidabile.
💡 Best Practices
Per sfruttare al meglio l'API LLMaaS, è fondamentale adottare strategie di ottimizzazione dei costi, delle prestazioni e della sicurezza.
Ottimizzazione dei Costi
Il controllo dei costi si basa sull'uso intelligente dei token e dei modelli.
-
Scelta del Modello: Non utilizzare un modello potente per compiti semplici. Un modello più grande è più capace, ma è anche più lento e consuma molto di più energia, influenzando direttamente il costo. Adatta la dimensione del modello alla complessità del tuo bisogno per un equilibrio ottimale.
Ad esempio, per elaborare un milione di token:
Gemma 3 1Bconsuma 0,15 kWh.Llama 3.3 70Bconsuma 11,75 kWh, ovvero 78 volte di più.
# Per un'analisi del sentiment, un modello compatto è sufficiente ed economico.if task == "sentiment_analysis":model = "granite3.3:2b"# Per un'analisi legale complessa, è necessario un modello più grande.elif task == "legal_analysis":model = "deepseek-r1:70b" -
Gestione del Contesto: La cronologia della conversazione (
messages) viene restituita a ogni chiamata, consumando token in ingresso. Per conversazioni lunghe, considera strategie di riassunto o finestra scorrevole per mantenere solo le informazioni rilevanti.# Per una conversazione lunga, si può riassumere la parte iniziale.messages = [{"role": "system", "content": "Sei un assistente IA."},{"role": "user", "content": "Riassunto dei primi 10 scambi..."},{"role": "assistant", "content": "Ok, ho il contesto."},{"role": "user", "content": "Ecco la mia nuova domanda."}] -
Limitazione dei Token di Output: Utilizza sempre il parametro
max_tokensper evitare risposte eccessivamente lunghe e costose. Imposta un limite ragionevole in base a ciò che ti aspetti.# Richiedi un riassunto di massimo 100 parole.response = client.chat.completions.create(model="granite3.3:8b",messages=[{"role": "user", "content": "Riassumi questo documento..."}],max_tokens=150, # Margine di sicurezza per circa 100 parole)
Prestazioni
La reattività della tua applicazione dipende dal modo in cui gestisci le chiamate all'API.
-
Richieste asincrone: Per elaborare più richieste senza attendere il completamento di ciascuna, utilizza chiamate asincrone. Questo è particolarmente utile per le applicazioni backend che elaborano un grande volume di richieste simultanee.
import asynciofrom openai import AsyncOpenAIclient = AsyncOpenAI(api_key="...", base_url="...")async def process_prompt(prompt: str):# Elabora una singola richiesta in modo asincronoresponse = await client.chat.completions.create(model="granite3.3:8b", messages=[{"role": "user", "content": prompt}])return response.choices[0].message.contentasync def batch_requests(prompts: list):# Avvia diverse attività in parallelo e attende il loro completamentotasks = [process_prompt(p) for p in prompts]return await asyncio.gather(*tasks) -
Streaming per l'esperienza utente (UX): Per le interfacce utente (chatbot, assistenti), lo streaming è fondamentale. Permette di visualizzare la risposta del modello parola per parola, creando l'effetto di una reattività immediata invece di attendere l'intera risposta.
# Mostra la risposta in tempo reale in un'interfaccia utenteresponse_stream = client.chat.completions.create(model="granite3.3:8b",messages=[{"role": "user", "content": "Raccontami una storia."}],stream=True)for chunk in response_stream:if chunk.choices[0].delta.content:# Visualizza il frammento di testo nell'UIprint(chunk.choices[0].delta.content, end="", flush=True)
Sicurezza
La sicurezza della tua applicazione è fondamentale, soprattutto quando gestisci input dell'utente.
-
Validazione e pulizia degli input (Sanitizzazione) : Non fare mai affidamento sugli input dell'utente. Prima di inviarli all'API, puliscili per rimuovere qualsiasi codice potenzialmente dannoso o istruzioni di "prompt injection". Limita anche la loro lunghezza per evitare abusi.
def sanitize_input(user_input: str) -> str:# Esempio semplice: rimuovere i delimitatori di codice e limitare la lunghezza.# Possono essere utilizzate librerie più robuste per una sanitizzazione avanzata.cleaned = user_input.replace("`", "").replace("'", "").replace("\"", "")return cleaned[:2000] # Limite la lunghezza a 2000 caratteri -
Gestione robusta degli errori : Racchiudi sempre le chiamate API all'interno di blocchi
try...exceptper gestire errori di rete, errori dell'API (es. 429 Rate Limit, 500 Internal Server Error) e fornire un'esperienza utente degradata ma funzionale.from openai import APIError, APITimeoutErrortry:response = client.chat.completions.create(...)except APITimeoutError:# Gestire il caso in cui la richiesta richiede troppo temporeturn "Il servizio sta impiegando più tempo del previsto, riprova più tardi."except APIError as e:# Gestire gli errori specifici dell'APIlogger.error(f"Errore API LLMaaS: {e.status_code} - {e.message}")return "Spiacenti, si è verificato un errore con il servizio di intelligenza artificiale."except Exception as e:# Gestire tutti gli altri errori (rete, ecc.)logger.error(f"Si è verificato un errore imprevisto: {e}")return "Spiacenti, si è verificato un errore imprevisto."