Conceptos
Nuestras ofertas Managed Kubernetes
Cloud Temple ofrece dos ofertas distintas para satisfacer sus necesidades de orquestación de contenedores :
- Managed Core Kubernetes : Un producto minimalista que le proporciona una base Kubernetes robusta y segura, basada en componentes open source de vanguardia. Es ideal para equipos expertos que desean construir su propia plataforma a medida.
- Managed Kubernetes : Una solución completa y lista para usar que incluye un stack completo de herramientas para la red, la seguridad, el almacenamiento, el despliegue continuo, la observabilidad, la copia de seguridad y la gestión de costos.
Tabla comparativa de las ofertas
| Componente | Managed Core Kubernetes | Managed Kubernetes |
|---|---|---|
| SO | Talos | Talos |
| CNI | Cilium | Cilium |
| Observabilidad CNI | ❌ | Hubble |
| Balanceador de carga | MetalLB | MetalLB |
| Ingress | ❌ | Ingress Nginx |
| Almacenamiento | Rook-Ceph | Rook-Ceph |
| Despliegue Continuo (GitOps) | ❌ | ArgoCD |
| Observabilidad | ❌ | Prometheus, Grafana, Loki |
| Copia de seguridad y Migración | ❌ | Veeam Kasten |
| Gestión de Costos (FinOps) | ❌ | OpenCost |
| Gobernanza y Seguridad | ❌ | Kyverno, Capsule |
| Registro de Contenedores | ❌ | Harbor |
| Gestión de certificados | ❌ | Cert-Manager |
| Autenticación SSO | ❌ | Integración OIDC |
Presentación del producto Managed Kubernetes (completa)
La oferta Managed Kubernetes (también llamada "Kub Gestionado", o "KM") es una solución de contenedorización Kubernetes gestionada por Cloud-Temple, desplegada en forma de Máquinas Virtuales que funcionan sobre las infraestructuras IaaS Cloud-Temple OpenIaaS.
Managed Kubernetes se basa en Talos Linux (https://www.talos.dev/), un sistema operativo dedicado a Kubernetes que es ligero y seguro. Es inmutable, sin ningún shell ni acceso SSH, y se configura únicamente de manera declarativa a través de la API gRPC.
La instalación estandarizada incluye un conjunto de componentes, mayoritariamente Open Source y validados por la CNCF:
-
CNI Cillium, con interfaz de observabilidad (Hubble): Cillium es una solución de networking para contenedores Kubernetes (Container Network Interface). Gestiona la seguridad, el balanceo de carga, el service mesh, la observabilidad, el cifrado, etc... Es un componente de red fundamental que se encuentra en la mayoría de las variantes de Kubernetes (OpenShift, AKS, GKE, EKS,...). Hemos incluido la interfaz gráfica Hubble para la visualización de los flujos de Cillium.
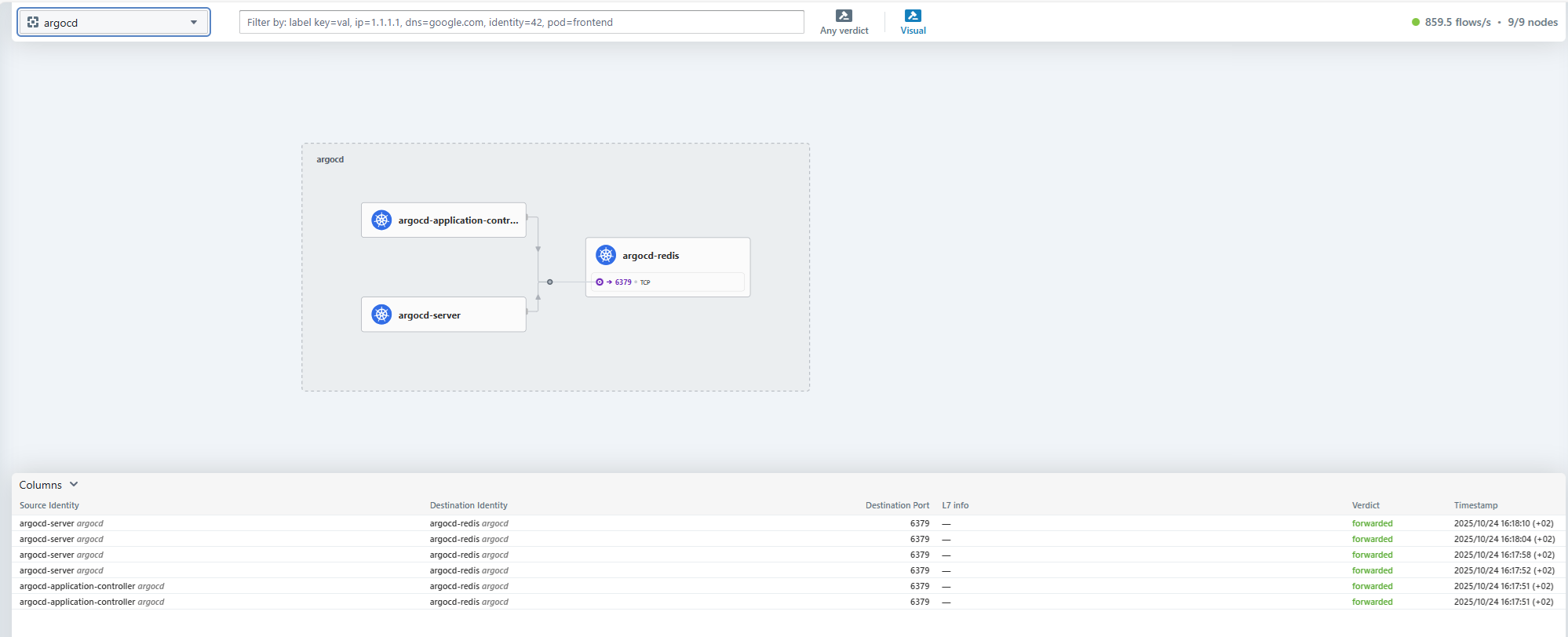
-
MetalLB y nginx: Para la exposición de aplicaciones Web, se integran de base 3 ingress-class nginx:
-
nginx-external-secured: exposición en una IP pública, filtrada en el firewall para permitir solo IPs conocidas (utilizado para las interfaces gráficas de los diferentes productos y la API de Kubernetes)
-
nginx-external: exposición en una segunda IP pública no filtrada (o filtrado específico para el cliente)
-
nginx-internal: exposición únicamente en una IP interna
Para los servicios "no web", un load-balancer metalLB permite exponer servicios en interno o en IPs públicas. (lo que permite desplegar otras ingresses, como por ejemplo un WAF)
-
-
Almacenamiento distribuido Rook-Ceph: para el almacenamiento de volúmenes persistentes (PV), se integra en la plataforma un almacenamiento distribuido Ceph Open Source. Permite utilizar las storage-classes ceph-block, ceph-bucket y ceph-filesystem. Se utiliza un almacenamiento de 7500 IOPS, lo que permite un alto rendimiento. En los despliegues de producción (en 3 AZ), los nodos de almacenamiento están dedicados (1 nodo por AZ); en los despliegues fuera de producción (1 AZ), el almacenamiento se comparte con los nodos workers.
-
Cert-Manager: el gestor de certificados Open Source Cert-Manager está integrado nativamente en la plataforma.
-
ArgoCD está a su disposición para sus despliegues automatizados a través de una cadena de CI/CD.
-
Stack Prometheus (Prometheus, Grafana, Loki): los clústeres Managed Kubernetes se entregan de serie con una stack Open Source completa de Prometheus para la observabilidad, que incluye:
-
Prometheus
-
Grafana, con numerosos dashboards
-
Loki: los registros de la plataforma se exportan al almacenamiento S3 Cloud-Temple (y se integran en Grafana).
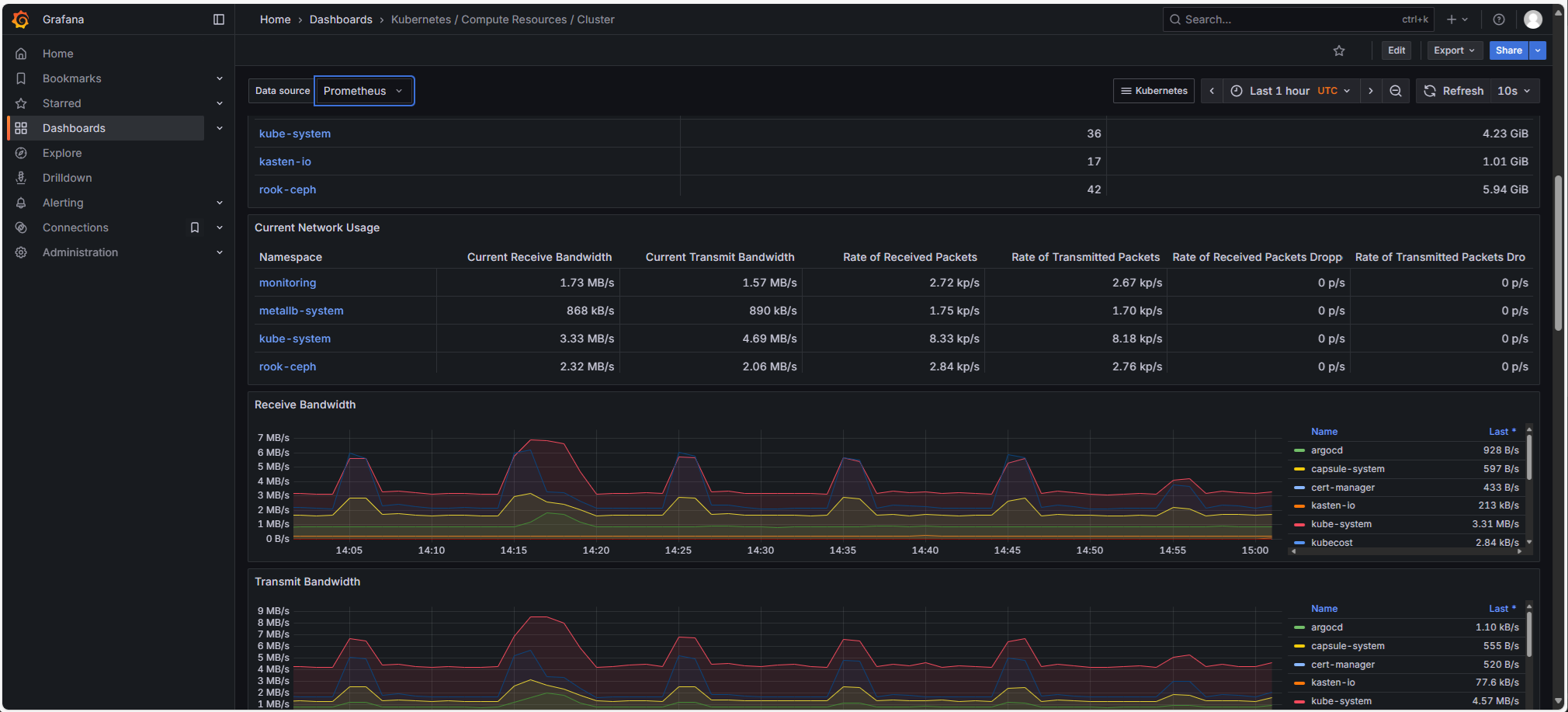
-
-
Harbor es un Container registry que le permite almacenar las imágenes de sus contenedores o sus charts de Helm directamente en el clúster. Realiza escaneos de vulnerabilidad en sus imágenes y puede firmarlas digitalmente. Harbor también permite sincronizaciones con otros registros. (https://goharbor.io/)
-
OpenCost (https://github.com/opencost/opencost) es una herramienta de gestión de costos (FinOps) para Kubernetes. Le permite seguir detalladamente el consumo de recursos de Kubernetes y realizar subfacturación por proyecto/namespace.
-
Estrategias de seguridad avanzadas con Kyverno y Capsule:
- Kyverno (https://kyverno.io/) es un controlador de admisión para Kubernetes que permite aplicar políticas. Es una herramienta esencial para la gobernanza y la seguridad en Kubernetes.
- Capsule (https://projectcapsule.dev/) es una herramienta de gestión de permisos que facilita la administración de derechos en Kubernetes. Introduce el concepto de tenant que permite centralizar y delegar permisos en varios namespaces. A través de Capsule, los usuarios de la plataforma Kubernetes Gestionado disponen, por tanto, de derechos restringidos únicamente a sus propios namespaces.
-
Veeam Kasten (también conocido como 'k10') es una solución para la copia de seguridad de las cargas de trabajo de Kubernetes.
Permite realizar copias de seguridad de un despliegue completo: manifiestos, volúmenes, etc... hacia el almacenamiento de objetos S3 Cloud-Temple. Kasten utiliza Kanister para permitir copias de seguridad aplicativas coherentes, por ejemplo para bases de datos (https://docs.kasten.io/latest/usage/blueprints/).
Kasten es una herramienta multiplataforma que puede funcionar con otros clústeres de Kubernetes (OpenShift, hiperescaladores,...). Por lo tanto, puede utilizarse para escenarios de reversibilidad o migración (K10 gestiona las adaptaciones necesarias mediante transformations, por ejemplo un cambio de ingress-class), pero también para "refresh" (ejemplo: restauración planificada de un entorno de producción en preproducción).
-
Autenticación SSO con un Identity Provider Externo OIDC (Microsoft Entra, FranceConnect, Okta, AWS IAM, Google, Salesforce, ...)
SLA e Información sobre el soporte
- Disponibilidad garantizada (producción 3 AZ) : 99.95 %
- Soporte : N1/N2/N3 incluido para el perímetro base (infraestructura y operadores estándar).
- Compromiso de tiempo de recuperación (ETR) : según contrato marco Cloud Temple.
- Mantenimiento (MCO) : aplicación regular de parches para Talos / Kubernetes / operadores estándar por parte del MSP, sin interrupción del servicio (rolling upgrade).
Los plazos de atención y recuperación dependen de la gravedad del incidente, de acuerdo con la matriz de soporte (P1 a P4).
Política de versiones y ciclo de vida
- Kubernetes soportado: N-2 (3 versiones principales por año, aproximadamente cada 4 meses). Cada versión es soportada oficialmente durante 12 meses, lo que garantiza una ventana de soporte de Cloud Temple de ~16 meses como máximo por versión.
- Talos OS: alineado con las versiones estables de Kubernetes.
- Cada rama se mantiene durante aproximadamente 12 meses (incluidos los parches de seguridad).
- Ritmo de actualización recomendado: 3 veces al año, en coherencia con las actualizaciones de Kubernetes.
- Los parches críticos (CVE, kernel) se aplican mediante rolling upgrade, sin interrupción del servicio.
- Operadores estándar: actualizados en un plazo de 90 días tras la versión estable.
- Actualizaciones:
- Principales (Kubernetes N+1, Talos X+1): programadas 3 veces/año, mediante rolling update.
- Menores: aplicadas automáticamente en un plazo de 30 a 60 días.
- Depreciación: versión N-3 → fin de soporte en un plazo de 90 días tras el lanzamiento de N.
Nodos de Kubernetes
Producción (multi-zona)
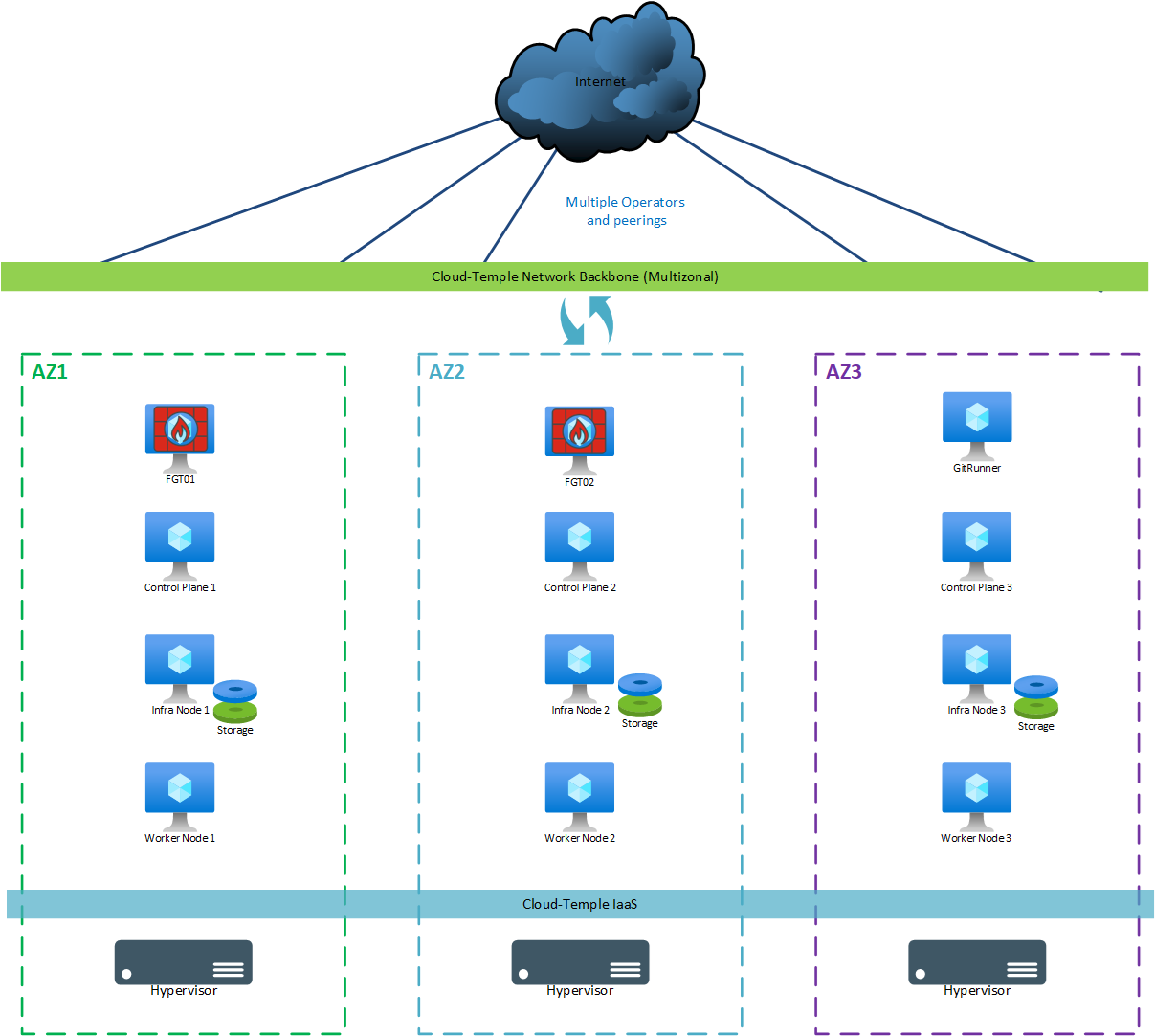
Para un despliegue "de producción" (multi-zona), se utilizan las siguientes máquinas:
| AZ | Máquina | vCores | RAM | Almacenamiento local |
|---|---|---|---|---|
| AZ07 | Git Runner | 4 | 8 Go | SO: 256 Go |
| AZ05 | Control Plane 1 | 8 | 12 Go | SO: 128 Go |
| AZ06 | Control Plane 2 | 8 | 12 Go | SO: 128 Go |
| AZ07 | Control Plane 3 | 8 | 12 Go | SO: 128 Go |
| AZ05 | Storage Node 1 | 12 | 24 Go | SO: 128 Go + Ceph 500 Go mínimo (*) |
| AZ06 | Storage Node 2 | 12 | 24 Go | SO: 128 Go + Ceph 500 Go mínimo (*) |
| AZ07 | Storage Node 3 | 12 | 24 Go | SO: 128 Go + Ceph 500 Go mínimo (*) |
| AZ05 | Worker Node 1 (**) | 12 | 24 Go | SO: 128 Go |
| AZ06 | Worker Node 2 (**) | 12 | 24 Go | SO: 128 Go |
| AZ07 | Worker Node 3 (**) | 12 | 24 Go | SO: 128 Go |
(*) : Cada nodo de almacenamiento se entrega con un mínimo de 500 Go de espacio en disco, para un almacenamiento útil Ceph distribuido de 500 Go (los datos se replican en cada AZ, por lo tanto x3). El espacio libre disponible para el cliente es de aproximadamente 350 Go. Este tamaño inicial puede aumentarse en el momento del despliegue, o más tarde, según sea necesario. Se aplican cuotas en Ceph, con una distribución Block/File.
(**) : El tamaño y la cantidad de Worker Nodes pueden adaptarse según la necesidad de capacidad de cálculo del cliente. La cantidad mínima de Worker nodes es de 3 (1 por AZ), y recomendamos aumentar su número en lotes de 3 para mantener una distribución multi-zona coherente. El tamaño de los Worker Node puede adaptarse, con un mínimo de 12 núcleos y 24 Go de RAM; el límite superior por Worker node está determinado por el tamaño de los hipervisores utilizados (por lo tanto, potencialmente 112 núcleos/1536 Go de RAM con blades Performance 3). La cantidad de Worker Nodes está limitada a 100. El CNCF recomienda tener worker nodes del mismo tamaño. El límite de pods por Worker Node es de 110.
Dev/Test
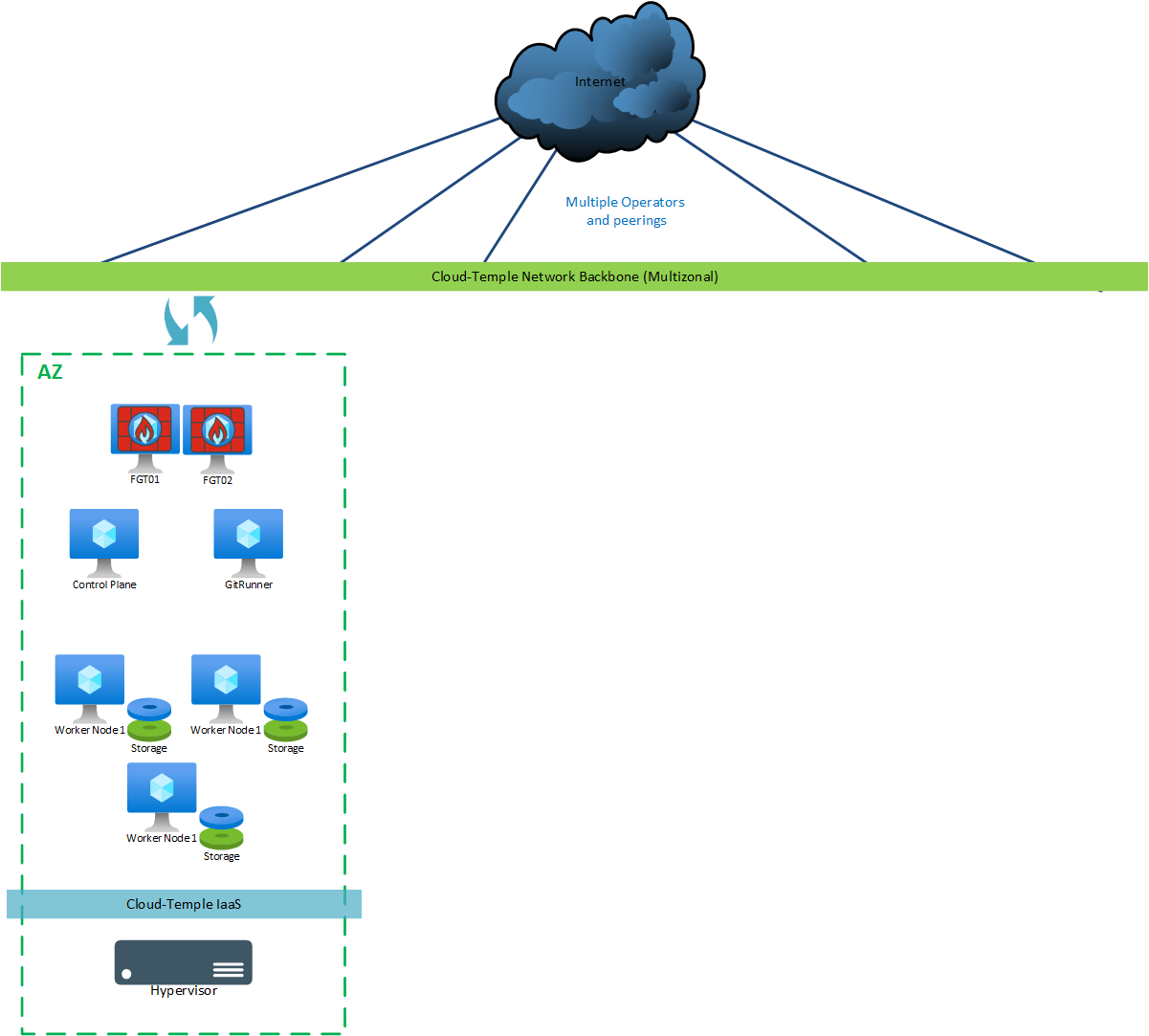
Para una versión "dev/test", se despliegan las siguientes máquinas:
| AZ | Máquina | vCores | RAM | Almacenamiento local |
|---|---|---|---|---|
| AZ0n | Git Runner | 4 | 8 Go | SO: 30 Go |
| AZ0n | Control Plane | 8 | 12 Go | SO: 128 Go |
| AZ0n | Worker Node 1 (**) | 12 | 24 Go | SO: 128 Go + Ceph 300 Go mínimo (*) |
| AZ0n | Worker Node 2 (**) | 12 | 24 Go | SO: 128 Go + Ceph 300 Go mínimo (*) |
| AZ0n | Worker Node 3 (**) | 12 | 24 Go | SO: 128 Go + Ceph 300 Go mínimo (*) |
(*) : 3 Worker nodes se utilizan como Storage nodes y se entregan con un mínimo de 300 Go de espacio en disco, para un almacenamiento útil distribuido de 300 Go (los datos se replican tres veces). El espacio libre disponible para el cliente es de aproximadamente 150 Go. Este tamaño inicial puede aumentarse en el momento del despliegue, o más tarde, según las necesidades.
(**) : El tamaño y la cantidad de Worker Nodes pueden adaptarse según la necesidad de capacidad de cálculo del cliente. El número mínimo de Worker nodes es de 3 (debido a la replicación del almacenamiento). El tamaño de los Worker Nodes puede adaptarse, con un mínimo de 12 núcleos y 24 Go de RAM; el límite superior por Worker node está determinado por el tamaño de los hipervisores utilizados (por lo tanto, potencialmente 112 núcleos/1536 Go de RAM con blades Performance 3). La cantidad de Worker Nodes está limitada a 250. El CNCF recomienda tener worker nodes del mismo tamaño. El límite de pods por Worker Node es de 110.
RACI
Arquitectura e Infraestructura
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Definir la arquitectura global del servicio Kubernetes | C | RA |
| Dimensionar el servicio Kubernetes (nombre de noeuds, ressources) | C | RA |
| Instalar el servicio Kubernetes con una configuración predeterminada | I | RA |
| Configuración del servicio Kubernetes | C | RA |
| Configurar la red base del servicio Kubernetes | I | RA |
| Despliegue de la configuración inicial de identidades y accesos | C | RA |
| Definir la estrategia de escalado y alta disponibilidad | C | RA |
Gestión de proyectos y aplicaciones empresariales
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Crear y gestionar los proyectos de Kubernetes | RA | I* |
| Desplegar y gestionar las aplicaciones en Kubernetes | RA | I* |
| Configurar los pipelines CI/CD | RA | I* |
| Gestionar las imágenes de contenedores y los registros | RA | I* |
*puede cambiar a "C" según el contrato de outsourcing
Monitoreo y rendimiento
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Monitorear el rendimiento del servicio de Kubernetes | I | RA* |
| Monitorear el rendimiento de las aplicaciones | RA | |
| Gestionar las alertas relacionadas con el servicio de Kubernetes | I | RA* |
| Gestionar las alertas relacionadas con las aplicaciones | RA |
(*) : Solo clúster de producción. En Dev/Test, el cliente tiene plena autonomía y responsabilidad.
Mantenimiento y actualizaciones de Infraestructuras
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Actualizar el servicio Kubernetes/OS | C | RA |
| Aplicar los parches de seguridad a Kubernetes | C | RA |
| Actualizar las aplicaciones desplegadas (opérateurs*) | C | RA |
*Paquete de operador incluido en Managed Kube - ver capítulos: Paquetes Helm gestionados
Seguridad
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Gestionar la seguridad del servicio Kubernetes | RA | RA* |
| Configurar y gestionar las políticas de seguridad de los pods | RA | I |
| Gestionar los certificados SSL/TLS para el servicio Kubernetes | C | RA* |
| Gestionar los certificados SSL/TLS para las aplicaciones | RA | I |
| Implementar y gestionar el control de acceso basado en roles de base (RBAC) | C | R* |
| Implementar y gestionar el control de acceso basado en roles del cliente (RBAC) | RA | I |
(*) : Solo clúster de producción. En Dev/Test el cliente tiene plena autonomía y responsabilidad.
Copia de seguridad y recuperación ante desastres
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Definir la estrategia de copia de seguridad para el servicio Kubernetes | I | RA |
| Implementar y gestionar las copias de seguridad del servicio Kubernetes | I | RA |
| Definir la estrategia de copia de seguridad para las aplicaciones | RA* | I* |
| Implementar y gestionar las copias de seguridad de las aplicaciones | RA* | I* |
| Probar los procedimientos de recuperación ante desastres para el servicio Kubernetes | CI | RA |
| Probar los procedimientos de recuperación ante desastres para las aplicaciones | RA* | CI* |
*puede cambiar a "CI | RA" según el contrato de externalización
Soporte y resolución de problemas
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Proporcionar soporte de nivel 1 para la infraestructura | I | RA |
| Proporcionar soporte de nivel 2 y 3 para la infraestructura | I | RA |
| Resolver problemas relacionados con el servicio Kubernetes | C | RA |
| Resolver problemas relacionados con las aplicaciones | RA | I |
Gestión de capacidades y evolución
Solo clúster de producción. En Dev/Test, el cliente es completamente autónomo y responsable.
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Monitorear el uso de los recursos de Kubernetes | C | RA |
| Planificar la evolución de las capacidades del servicio | RA | C |
| Implementar los cambios de capacidad | I | RA |
| Gestionar la evolución de las aplicaciones y sus recursos | RA | I |
Documentación y cumplimiento
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Mantener la documentación del producto Kubernetes | I | RA |
| Mantener la documentación de las aplicaciones | RA | I |
| Garantir el cumplimiento del servicio Kubernetes | I | RA |
| Garantir el cumplimiento de las aplicaciones | RA | I |
| Realizar auditorías del servicio Kubernetes | I | RA |
| Realizar auditorías de las aplicaciones | RA | I |
Gestión de operadores/CRD de Kubernetes (incluido en el producto)
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Disponibilidad del catálogo de Operadores predeterminado | CI | RA |
| Actualización de los Operadores | CI | RA |
| Monitoreo del estado de los Operadores | CI | RA |
| Resolución de problemas relacionados con los Operadores | CI | RA |
| Gestión de los permisos de los Operadores | CI | RA |
| Gestión de los recursos de los Operadores (ajout/suppression) | CI | RA |
| Respaldo de los datos de los recursos de los Operadores | CI | RA |
| Supervisión de los recursos de los Operadores | CI | RA |
| Restauración de los datos de los recursos de los Operadores | CI | RA |
| Auditoría de seguridad de los Operadores | CI | RA |
| Soporte de los Operadores | CI | RA |
| Gestión de licencias en los operadores | CI | RA |
| Gestión de planes de soporte específicos en los operadores | CI | RA |
*Paquete de operador incluido en Managed Kube - ver capítulos: Paquetes Helm gestionados
Gestión de aplicaciones/operadores/CRD de Kubernetes (del cliente)
Solo clúster de producción. En Dev/Test, el cliente tiene plena autonomía y responsabilidad.
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Despliegue de CRDs | I* | RA* |
| Actualización de operadores | RA | I |
| Monitoreo del estado de los operadores | RA | I |
| Resolución de problemas relacionados con los operadores | RA | I |
| Gestión de autorizaciones de los operadores | RA | I |
| Gestión de recursos de los operadores (agregado/eliminación) | RA | I |
| Copia de seguridad de datos de los recursos de los operadores | RA | I |
| Supervisión de recursos de operadores | RA | I |
| Restauración de datos de los recursos de los operadores | RA | I |
| Auditoría de seguridad de los operadores | RA | I |
| Soporte de operadores | RA | I |
| Gestión de licencias de los operadores | RA | I |
| Gestión de planes de soporte específicos para los operadores | RA | I |
Algunos servicios de operadores pueden estar cubiertos según el contrato de outsourcing.
*puede cambiar a "A | RC" según el contrato de outsourcing
Asistencia de aplicaciones
| Actividad | Cliente | Cloud Temple |
|---|---|---|
| Asistencia de aplicaciones (servicio externo) | RA | I |
Se puede proporcionar soporte de aplicaciones a través de un servicio complementario.
RACI (resumido)
- Cloud Temple : responsable y actor (RA) de la base Kubernetes, seguridad del clúster, respaldo de infraestructura, supervisión, CRD.
- Cliente : responsable y actor (RA) de los proyectos de aplicaciones, operadores de negocio, pipelines CI/CD, respaldos de aplicaciones.
- Zona "gris" : adaptaciones y extensiones (IAM, operadores específicos, endurecimiento de cumplimiento/seguridad del clúster) - facturadas en modalidad de proyecto.