Concepts
Our Managed Kubernetes Offerings
Cloud Temple offers two distinct solutions to meet your container orchestration needs:
- Managed Core Kubernetes : A minimalist product that provides you with a robust and secure Kubernetes foundation, built on cutting-edge open-source components. It is ideal for expert teams looking to build their own custom platform.
- Managed Kubernetes : A comprehensive, out-of-the-box solution that includes a full stack of tools for networking, security, storage, continuous deployment, observability, backup, and cost management.
Offer Comparison Table
| Component | Managed Core Kubernetes | Managed Kubernetes |
|---|---|---|
| OS | Talos | Talos |
| CNI | Cilium | Cilium |
| CNI Observability | ❌ | Hubble |
| Load Balancer | MetalLB | MetalLB |
| Ingress | ❌ | Nginx Ingress |
| Storage | Rook-Ceph | Rook-Ceph |
| Continuous Deployment (GitOps) | ❌ | ArgoCD |
| Observability | ❌ | Prometheus, Grafana, Loki |
| Backup and Migration | ❌ | Veeam Kasten |
| Cost Management (FinOps) | ❌ | OpenCost |
| Governance and Security | ❌ | Kyverno, Capsule |
| Container Registry | ❌ | Harbor |
| Certificate Management | ❌ | Cert-Manager |
| SSO Authentication | ❌ | OIDC Integration |
Managed Kubernetes Product Overview (Complete)
The Managed Kubernetes offering (also referred to as "Managed Kub" or "MK") is a Cloud-Temple-managed Kubernetes containerization solution deployed as Virtual Machines running on Cloud-Temple OpenIaaS IaaS infrastructure.
Managed Kubernetes is built on Talos Linux (https://www.talos.dev/), a lightweight and secure operating system dedicated to Kubernetes. It is immutable, has no shell or SSH access, and is configured exclusively in a declarative manner via the gRPC API.
The standardized installation includes a set of components, mostly Open Source and CNCF-certified:
-
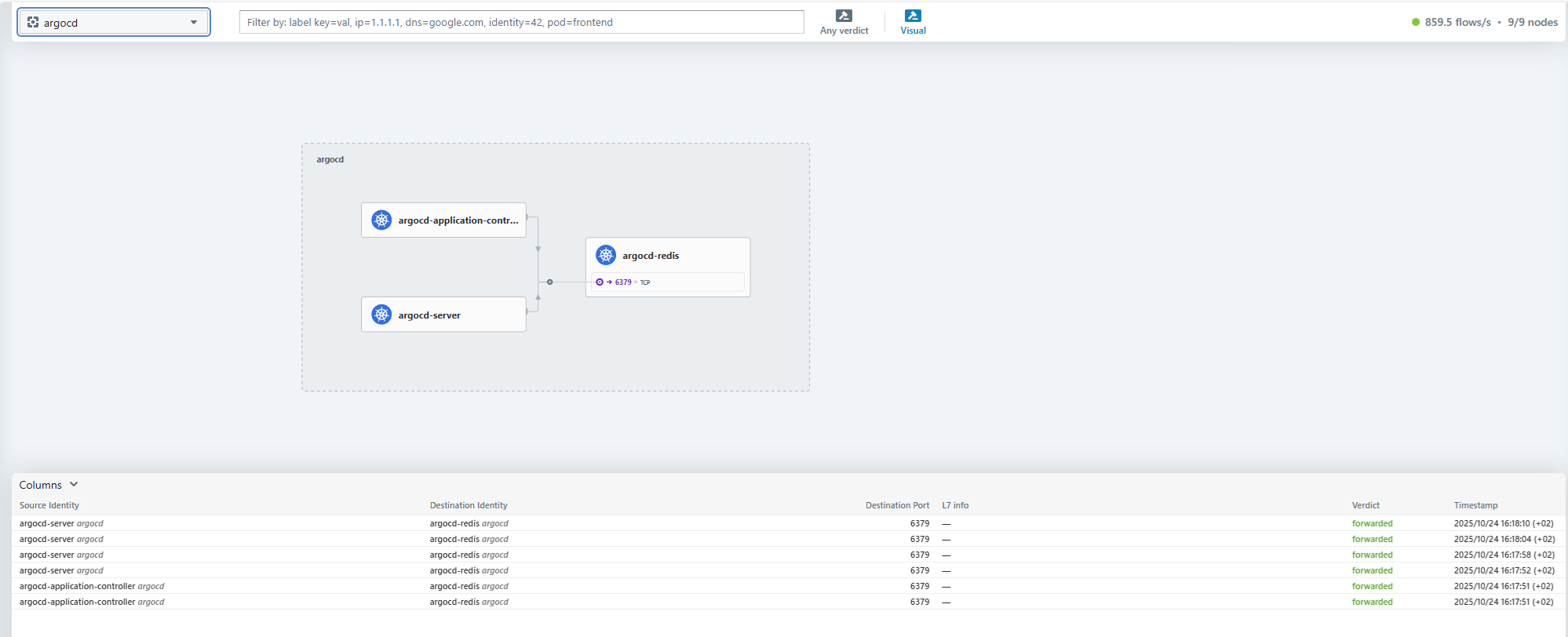
CNI Cilium, with observability interface (Hubble): Cilium is a networking solution for Kubernetes containers (Container Network Interface). It handles security, load balancing, service mesh, observability, encryption, etc. It is a fundamental networking component found in most Kubernetes distributions (OpenShift, AKS, GKE, EKS, etc.). We have included the Hubble GUI for visualizing Cilium traffic flows.
-
MetalLB and nginx: For exposing web applications, 3 nginx ingress-classes are integrated by default:
-
nginx-external-secured: exposure on a public IP, filtered at the firewall level to allow only known IPs (used for the GUIs of various products and the Kubernetes API)
-
nginx-external: exposure on a second unfiltered public IP (or client-specific filtering)
-
nginx-internal: exposure on an internal IP only
For "non-web" services, a MetalLB load balancer allows exposing services internally or on public IPs. (This enables deploying other ingress controllers, such as a WAF)
-
-
Distributed Rook-Ceph Storage: For persistent volume (PV) storage, an Open Source distributed Ceph storage system is integrated into the platform. It supports the ceph-block, ceph-bucket, and ceph-filesystem storage-classes. Storage with 7500 IOPS is used, enabling high performance. In production deployments (across 3 AZs), storage nodes are dedicated (1 node per AZ); in non-production deployments (1 AZ), storage is shared with worker nodes.
-
Cert-Manager: The Open Source certificate manager Cert-Manager is natively integrated into the platform.
-
ArgoCD is available for your automated deployments via a CI/CD pipeline.
-
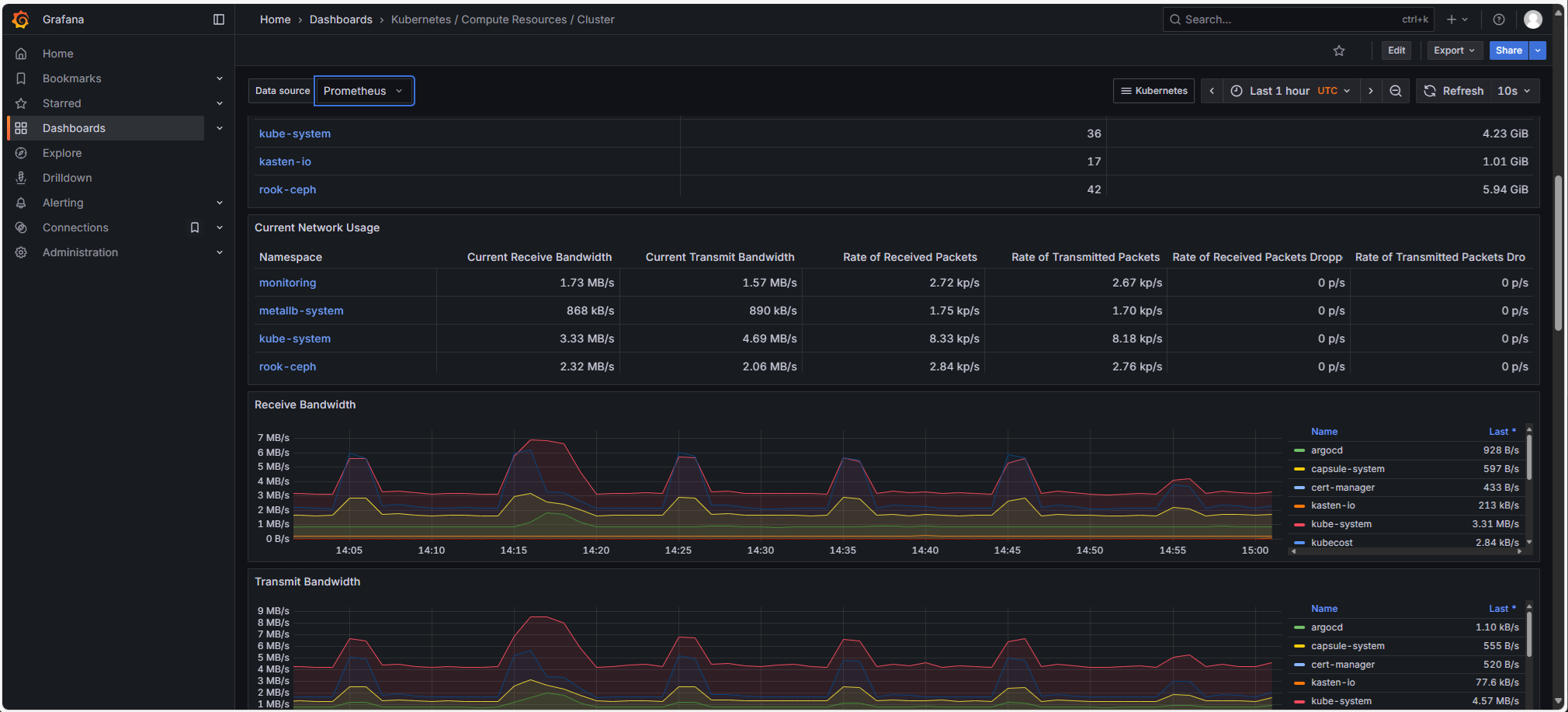
Prometheus Stack (Prometheus, Grafana, Loki): Managed Kubernetes clusters come standard with a complete Open Source Prometheus stack for observability, including:
-
Prometheus
-
Grafana, with numerous dashboards
-
Loki: Platform logs are exported to Cloud-Temple S3 storage (and integrated into Grafana).
-
-
Harbor is a Container registry that allows you to store your container images or Helm charts directly within the cluster. It performs vulnerability scanning on your images and can digitally sign them. Harbor also supports synchronization with other registries. (https://goharbor.io/)
-
OpenCost (https://github.com/opencost/opencost) is a cost management (FinOps) tool for Kubernetes. It allows you to closely track Kubernetes resource consumption and perform cost allocation/showback by project/namespace.
-
Advanced security policies with Kyverno and Capsule:
- Kyverno (https://kyverno.io/) is an admission controller for Kubernetes that enables policy enforcement. It is an essential tool for governance and security in Kubernetes.
- Capsule (https://projectcapsule.dev/) is a permission management tool that simplifies rights management in Kubernetes. It introduces the concept of a tenant, allowing centralized and delegated permissions across multiple namespaces. Through Capsule, users of the Managed Kubernetes platform are granted permissions restricted to their own namespaces only.
-
Veeam Kasten (aka 'k10') is a solution for backing up Kubernetes workloads.
It enables backing up complete deployments: manifests, volumes, etc., to Cloud-Temple S3 object storage. Kasten uses Kanister to enable application-consistent backups, for example for databases (https://docs.kasten.io/latest/usage/blueprints/).
Kasten is a cross-platform tool that can work with other Kubernetes clusters (OpenShift, Hyperscalers, etc.). It can therefore be used for reversibility or migration scenarios (K10 handles potential adaptations via transformations, such as changing an ingress-class), as well as for "refresh" operations (e.g., scheduled restoration of a production environment to pre-production).
-
SSO Authentication with an External OIDC Identity Provider (Microsoft Entra, FranceConnect, Okta, AWS IAM, Google, Salesforce, ...)
SLA & Support Information
- Guaranteed availability (production 3 AZ) : 99.95 %
- Support : N1/N2/N3 included for the core scope (infrastructure and standard operators).
- Recovery Time Commitment (ETR) : per Cloud Temple framework agreement.
- Maintenance (MCO) : regular patching of Talos / Kubernetes / standard operators by MSP, with no service interruption (rolling upgrade).
Response and recovery times depend on the incident severity, in accordance with the support matrix (P1 to P4).
Versioning Policy & Lifecycle
- Supported Kubernetes: N-2 (3 major releases per year, approximately every 4 months). Each release is officially supported for 12 months, ensuring a Cloud Temple support window of ~16 months maximum per version.
- Talos OS: aligned with stable Kubernetes versions.
- Each branch is maintained for approximately 12 months (security patches included).
- Recommended upgrade cadence: 3 times per year, in alignment with Kubernetes upgrades.
- Critical patches (CVE, kernel) are applied via rolling upgrade, with no service interruption.
- Standard operators: updated within 90 days following the stable release.
- Updates:
- Major (Kubernetes N+1, Talos X+1): scheduled 3 times/year, via rolling update.
- Minor: applied automatically within 30 to 60 days.
- Deprecation: version N-3 → end of support within 90 days after the release of N.
Kubernetes Nodes
Production (multi-zone)
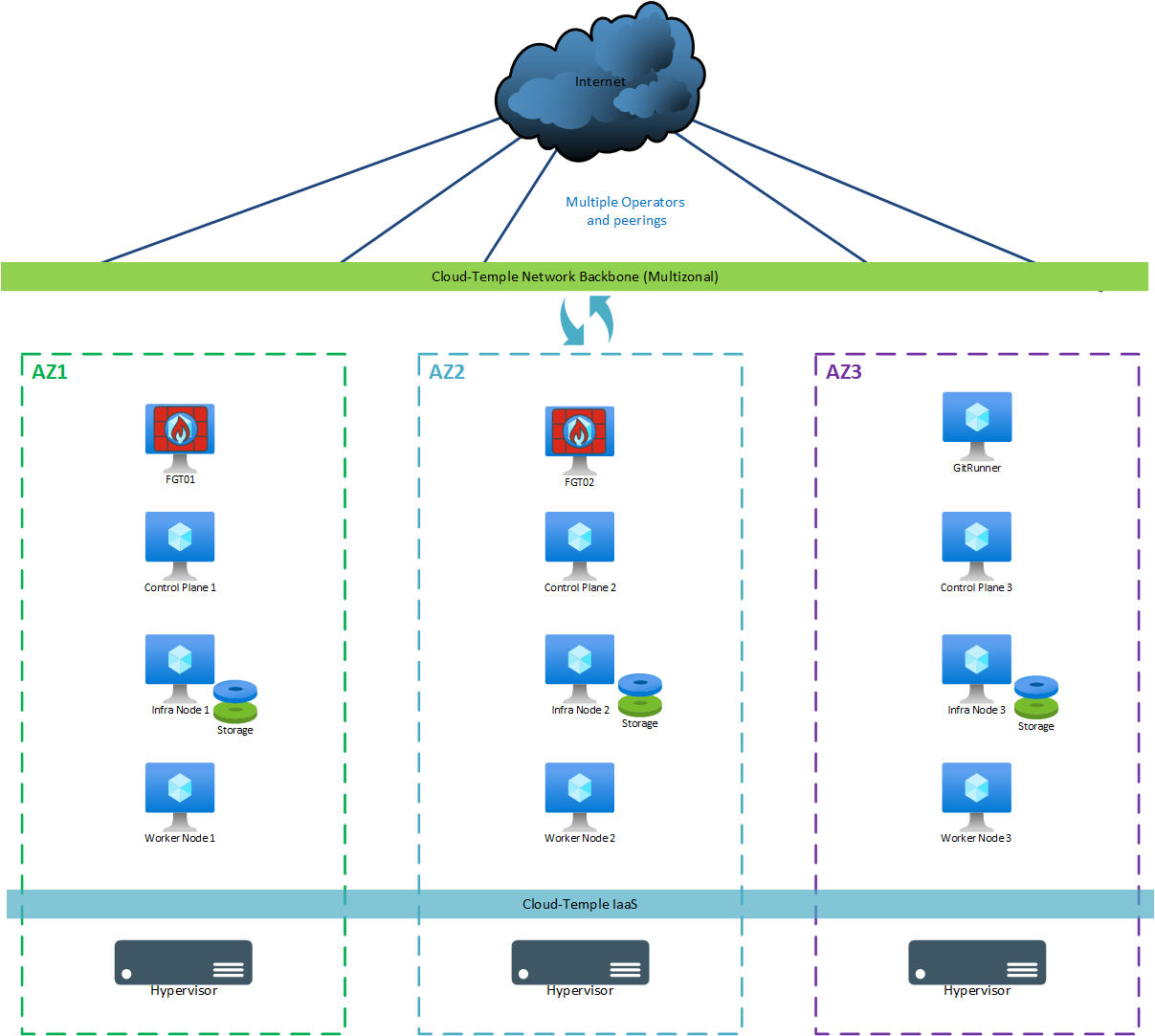
For a "production" deployment (multi-zone), the following machines are used:
| AZ | Machine | vCores | RAM | Local Storage |
|---|---|---|---|---|
| AZ07 | Git Runner | 4 | 8 GB | OS: 256 GB |
| AZ05 | Control Plane 1 | 8 | 12 GB | OS: 128 GB |
| AZ06 | Control Plane 2 | 8 | 12 GB | OS: 128 GB |
| AZ07 | Control Plane 3 | 8 | 12 GB | OS: 128 GB |
| AZ05 | Storage Node 1 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB minimum (*) |
| AZ06 | Storage Node 2 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB minimum (*) |
| AZ07 | Storage Node 3 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB minimum (*) |
| AZ05 | Worker Node 1 (**) | 12 | 24 GB | OS: 128 GB |
| AZ06 | Worker Node 2 (**) | 12 | 24 GB | OS: 128 GB |
| AZ07 | Worker Node 3 (**) | 12 | 24 GB | OS: 128 GB |
(*) : Each storage node comes with a minimum of 500 GB of disk space, providing 500 GB of usable distributed Ceph storage (data is replicated across each AZ, hence x3). The free space available to the client is approximately 350 GB. This initial size can be increased during initial provisioning, or later, depending on requirements. Quotas are applied on Ceph, with a Block/File allocation.
(**) : The size and number of Worker Nodes can be adjusted based on the client's compute capacity requirements. The minimum number of Worker Nodes is 3 (1 per AZ), and we recommend increasing their number in batches of 3 to maintain a consistent multi-zone distribution. The size of Worker Nodes can be adjusted, with a minimum of 12 cores and 24 GB of RAM; the upper limit per Worker Node is determined by the size of the hypervisors used (thus potentially 112 cores/1536 GB of RAM with Performance 3 blades). The number of Worker Nodes is limited to 100. The CNCF recommends having Worker Nodes of identical size. The limit on the number of pods per Worker Node is 110.
Dev/Test
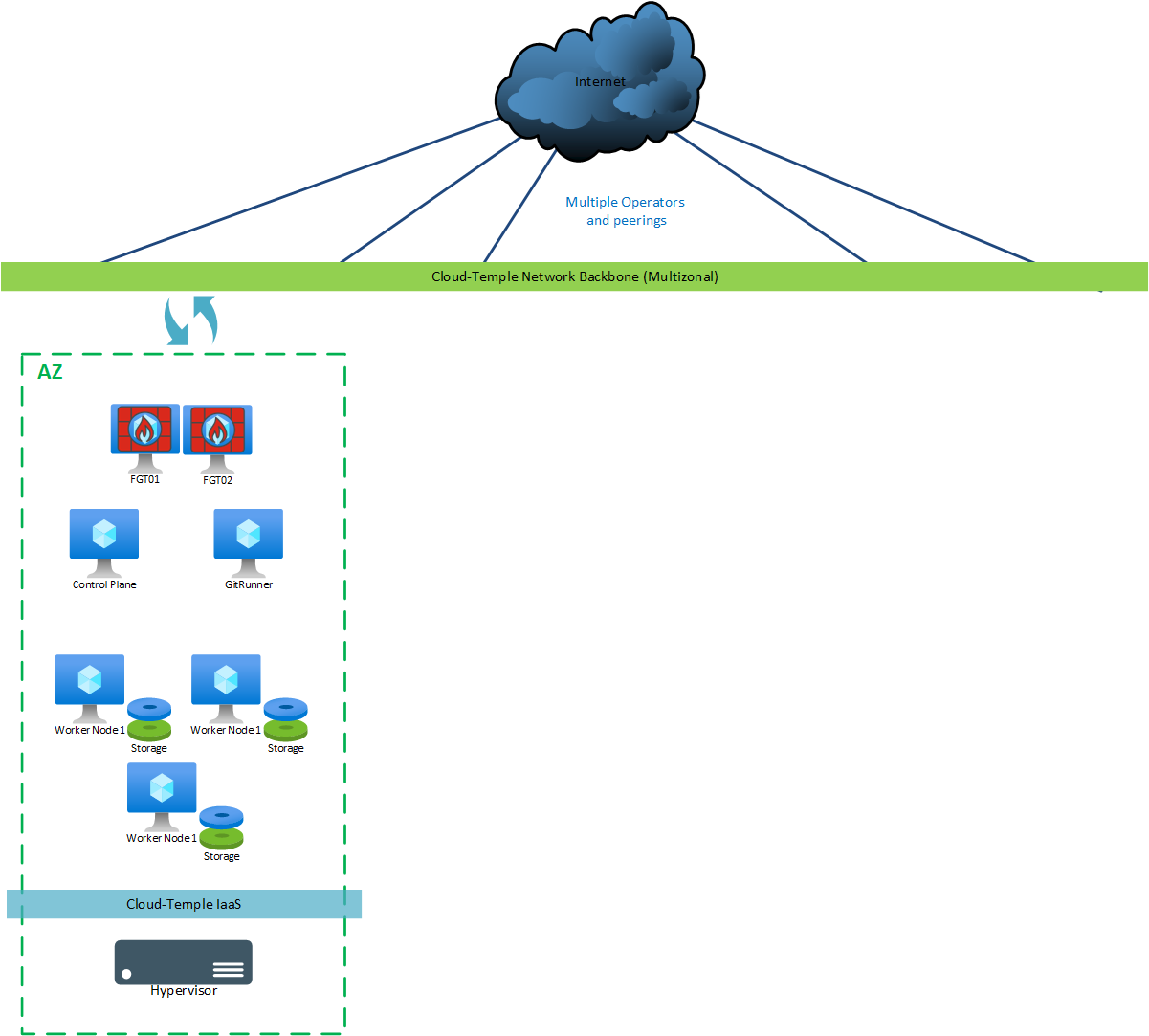
For a "dev/test" version, the following machines are deployed:
| AZ | Machine | vCores | RAM | Local Storage |
|---|---|---|---|---|
| AZ0n | Git Runner | 4 | 8 GB | OS: 30 GB |
| AZ0n | Control Plane | 8 | 12 GB | OS: 128 GB |
| AZ0n | Worker Node 1 (**) | 12 | 24 GB | OS: 128 GB + Ceph 300 GB minimum (*) |
| AZ0n | Worker Node 2 (**) | 12 | 24 GB | OS: 128 GB + Ceph 300 GB minimum (*) |
| AZ0n | Worker Node 3 (**) | 12 | 24 GB | OS: 128 GB + Ceph 300 GB minimum (*) |
(*) : 3 Worker nodes are used as Storage nodes and are provisioned with a minimum of 300 GB of disk space, providing 300 GB of usable distributed storage (data is replicated three times). The free space available to the client is approximately 150 GB. This initial size can be increased at deployment time, or later, depending on requirements.
(**) : The size and number of Worker Nodes can be adjusted based on the client's compute capacity requirements. The minimum number of Worker nodes is 3 (due to storage replication). The size of Worker Nodes can be adjusted, with a minimum of 12 cores and 24 GB of RAM; the upper limit per Worker node is determined by the size of the hypervisors used (thus potentially 112 cores/1536 GB of RAM with Performance 3 blades). The number of Worker Nodes is limited to 250. The CNCF recommends using worker nodes of identical size. The limit on the number of pods per Worker Node is 110.
RACI
Architecture & Infrastructure
| Activity | Client | Cloud Temple |
|---|---|---|
| Define the overall architecture of the Kubernetes service | C | RA |
| Size the Kubernetes service (number of nodes, resources) | C | RA |
| Install the Kubernetes service with a default configuration | I | RA |
| Configure the Kubernetes service | C | RA |
| Configure the base network of the Kubernetes service | I | RA |
| Deploy the initial identity and access configuration | C | RA |
| Define the scaling and high availability strategy | C | RA |
Project and Business Application Management
| Activity | Client | Cloud Temple |
|---|---|---|
| Create and manage Kubernetes projects | RA | I* |
| Deploy and manage applications in Kubernetes | RA | I* |
| Configure CI/CD pipelines | RA | I* |
| Manage container images and registries | RA | I* |
*may change to "C" depending on the managed services contract
Monitoring and Performance
| Activity | Client | Cloud Temple |
|---|---|---|
| Monitor Kubernetes service performance | I | RA* |
| Monitor application performance | RA | |
| Manage Kubernetes service-related alerts | I | RA* |
| Manage application-related alerts | RA |
(*) : Production Cluster only. In Dev/Test, the client is fully autonomous and responsible.
Infrastructure Maintenance and Updates
| Activity | Client | Cloud Temple |
|---|---|---|
| Update Kubernetes/OS service | C | RA |
| Apply security patches to Kubernetes | C | RA |
| Update deployed applications (operators*) | C | RA |
*Operator package included on Managed Kube - see chapters: Managed Helm Packages
Security
| Activity | Client | Cloud Temple |
|---|---|---|
| Manage Kubernetes service security | RA | RA* |
| Configure and manage pod security policies | RA | I |
| Manage SSL/TLS certificates for the Kubernetes service | C | RA* |
| Manage SSL/TLS certificates for applications | RA | I |
| Implement and manage base role-based access control (RBAC) | C | R* |
| Implement and manage client role-based access control (RBAC) | RA | I |
(*) : Production cluster only. In Dev/Test, the client is fully autonomous and responsible.
Backup and Disaster Recovery
| Activity | Client | Cloud Temple |
|---|---|---|
| Define the backup strategy for the Kubernetes service | I | RA |
| Implement and manage backups for the Kubernetes service | I | RA |
| Define the backup strategy for applications | RA* | I* |
| Implement and manage backups for applications | RA* | I* |
| Test disaster recovery procedures for the Kubernetes service | CI | RA |
| Test disaster recovery procedures for applications | RA* | CI* |
*may change to "CI | RA" depending on the managed services contract
Support and Troubleshooting
| Activity | Client | Cloud Temple |
|---|---|---|
| Provide level 1 support for the infrastructure | I | RA |
| Provide level 2 and 3 support for the infrastructure | I | RA |
| Resolve issues related to the Kubernetes service | C | RA |
| Resolve issues related to applications | RA | I |
Capacity Management and Evolution
Production Cluster only. In Dev/Test, the client is fully autonomous and responsible.
| Activity | Client | Cloud Temple |
|---|---|---|
| Monitor Kubernetes resource utilization | C | RA |
| Plan service capacity evolution | RA | C |
| Implement capacity changes | I | RA |
| Manage application evolution and associated resources | RA | I |
Documentation and Compliance
| Activity | Client | Cloud Temple |
|---|---|---|
| Maintain Kubernetes product documentation | I | RA |
| Maintain application documentation | RA | I |
| Ensure Kubernetes service compliance | I | RA |
| Ensure application compliance | RA | I |
| Conduct Kubernetes service audits | I | RA |
| Conduct application audits | RA | I |
Kubernetes Operators/CRD Management (included in the product)
| Activity | Client | Cloud Temple |
|---|---|---|
| Provisioning of the default Operators catalog | CI | RA |
| Updating Operators | CI | RA |
| Monitoring Operators status | CI | RA |
| Troubleshooting Operators issues | CI | RA |
| Managing Operators permissions | CI | RA |
| Managing Operators resources (addition/removal) | CI | RA |
| Backing up Operators resources data | CI | RA |
| Monitoring Operators resources | CI | RA |
| Restoring Operators resources data | CI | RA |
| Security auditing of Operators | CI | RA |
| Operators support | CI | RA |
| Managing licenses for Operators | CI | RA |
| Managing specific support plans for Operators | CI | RA |
*Operator package included on Managed Kube - see chapters: Managed Helm Packages
Management of Kubernetes applications/operators/CRDs (client-side)
Production Cluster only. In Dev/Test, the client is fully autonomous and responsible.
| Activity | Client | Cloud Temple |
|---|---|---|
| CRD Deployment | I* | RA* |
| Operator Updates | RA | I |
| Operator Status Monitoring | RA | I |
| Operator Issue Resolution | RA | I |
| Operator Permissions Management | RA | I |
| Operator Resources Management (addition/removal) | RA | I |
| Operator Resources Data Backup | RA | I |
| Operator Resources Monitoring | RA | I |
| Operator Resources Data Restoration | RA | I |
| Operator Security Auditing | RA | I |
| Operator Support | RA | I |
| Operator Licensing Management | RA | I |
| Specific Support Plans Management for Operators | RA | I |
Certain operator services may be covered depending on the managed services contract.
*may change to "A | RC" depending on the managed services contract
Application Support
| Activity | Client | Cloud Temple |
|---|---|---|
| Application support (external service) | RA | I |
Application support can be provided via a complementary service.
RACI (summary)
- Cloud Temple : Responsible and Accountable (RA) for the Kubernetes platform, cluster security, infrastructure backup, monitoring, CRD.
- Client : Responsible and Accountable (RA) for application projects, business operators, CI/CD pipelines, application backups.
- "Gray" area : adaptations and extensions (IAM, specific operators, cluster compliance/security hardening) - billed on a project basis.