LLMaaS Tutorials
Overview
These advanced tutorials cover integration, optimization, and best practices for fully leveraging LLMaaS Cloud Temple in production. Each tutorial includes tested code and real performance metrics.
🚀 LangChain Integrations and Frameworks
1. Basic Integration with LangChain
This first example demonstrates how to integrate our LLMaaS API with the popular LangChain framework by creating a custom "wrapper." A wrapper is a class that "encapsulates" our API to make it compatible with LangChain's internal mechanisms.
Code Explained
The code below defines a CloudTempleLLM class that inherits from the base LLM class in LangChain. This allows us to define custom behavior while remaining compatible with the LangChain ecosystem (chains, agents, etc.).
CloudTempleLLM(LLM): Our class inherits fromLLM, which requires us to implement certain methods, notably_call._call(self, prompt: str, ...): This is the core of our wrapper. Every time LangChain needs to invoke our language model, it will call this method. Inside, we format a standard HTTP POST request with the correct headers (Authorization) and the expectedpayloadfor our API endpoint/v1/chat/completions.example_langchain_basic(): This demonstration function shows how to use our wrapper. We instantiate it, create aPromptTemplateto structure our request, and combine them into anLLMChain. When we run the chain (chain.run(...)), LangChain internally calls the_callmethod we defined.
This approach is useful when you need full control over how LangChain interacts with the API, but it is more verbose than using the ChatOpenAI client (see API Reference).
# Installing dependencies
# pip install langchain requests pydantic
from langchain.llms.base import LLM
from langchain.schema import LLMResult, Generation
from typing import Optional, List, Any
from pydantic import Field
import requests
import json
import os
# --- Configuration ---
# It is recommended to store your API key in an environment variable
API_KEY = os.getenv("LLMAAS_API_KEY", "your-api-key-here")
BASE_URL = "https://api.ai.cloud-temple.com/v1"
class CloudTempleLLM(LLM):
"""
Custom LangChain wrapper for Cloud Temple's LLMaaS API.
This class enables using our API as a standard LLM within LangChain.
"""
api_key: str = Field(default="")
model_name: str = Field(default="granite3.3:8b")
temperature: float = Field(default=0.7)
max_tokens: int = Field(default=1000)
@property
def _llm_type(self) -> str:
"""Unique identifier for our LLM type."""
return "cloud_temple_llmaas"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
"""
Main method that makes the call to the LLMaaS API.
LangChain uses this method for each request to the model.
"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": self.model_name,
"messages": [{"role": "user", "content": prompt}],
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
if stop:
payload["stop"] = stop
# Execute POST request to the API
response = requests.post(
f"{BASE_URL}/chat/completions",
headers=headers,
json=payload,
timeout=60
)
response.raise_for_status() # Raises an exception on HTTP error
result = response.json()
# Return the content of the assistant's message
return result['choices'][0]['message']['content']
# --- Example usage ---
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
def example_langchain_wrapper():
"""Demonstrates the use of the LLM wrapper with a LangChain chain."""
# 1. Initialize our custom LLM
llm = CloudTempleLLM(
api_key=API_KEY,
model_name="granite3.3:8b"
)
# 2. Create a prompt template to structure requests
template = """
You are an expert in {domain}.
Answer this question in a detailed and professional manner:
Question: {question}
Answer:
"""
prompt = PromptTemplate(
input_variables=["domain", "question"],
template=template
)
# 3. Create a chain that combines the prompt and the LLM
chain = LLMChain(llm=llm, prompt=prompt)
# 4. Execute the chain with specific variables
result = chain.run(
domain="cybersecurity",
question="What are the best practices for securing a REST API?"
)
return result
# --- Running the test ---
if __name__ == "__main__":
if API_KEY == "your-api-key-here":
print("Please set your LLMAAS_API_KEY in your environment variables.")
else:
response = example_langchain_wrapper()
print("Response from the cybersecurity expert:\n")
print(response)
2. RAG (Retrieval-Augmented Generation) with the LLMaaS API
RAG is a powerful technique that enables a Large Language Model (LLM) to answer questions by leveraging an external knowledge base. This tutorial guides you through building a simple RAG pipeline using our API for embeddings and generation, and FAISS, a vector similarity library, to create an in-memory index.
Code Explained
The pipeline is broken down into several logical steps:
- Configuration: We import the necessary libraries and load our API key from environment variables. We define the models to use:
granite-embedding:278mfor vectorization andgranite3.3:8bfor response generation. LLMaaSEmbeddings: As in the previous example, we need a wrapper to interact with our embeddings API. This class is responsible for transforming text chunks into numerical vectors (embeddings).setup_rag_pipeline: This function orchestrates the creation of the pipeline.- Loading documents:
DirectoryLoaderloads text files from our knowledge base. - Splitting into chunks:
RecursiveCharacterTextSplitterdivides the documents into smaller pieces. This is essential so that the embedding model can process the text efficiently and ensure accurate similarity search. - Vectorization and Indexing:
FAISS.from_documentsis a key step. It takes the text chunks, uses ourLLMaaSEmbeddingsclass to call the API and obtain corresponding vectors, then stores these vectors in an in-memory FAISS index. - LLM Configuration: We use
ChatOpenAI, which is natively compatible with our API for the response generation part. - Creating the
RetrievalQAchain: This is the LangChain chain that ties everything together. When given a question, it: a. Uses theretriever(based on our FAISS index) to find the most relevant text chunks. b. "Stuff" (inserts) these chunks into a prompt along with the question. c. Sends this enriched prompt to the LLM to generate a contextually relevant response.
- Loading documents:
- Execution: The
mainfunction simulates real-world usage by creating temporary knowledge files, building the pipeline, and posing a question.
import os
import tempfile
import shutil
from pathlib import Path
from dotenv import load_dotenv
from typing import List
# --- LangChain Imports ---
from langchain_core.embeddings import Embeddings
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
# --- Configuration ---
# Load environment variables (e.g., LLMAAS_API_KEY)
load_dotenv()
API_KEY = os.getenv("LLMAAS_API_KEY")
BASE_URL = os.getenv("API_URL", "https://api.ai.cloud-temple.com/v1")
EMBEDDING_MODEL = "granite-embedding:278m"
LLM_MODEL = "granite3.3:8b"
# --- Custom Embedding Class ---
class LLMaaSEmbeddings(Embeddings):
"""Custom embedding class for Cloud Temple's LLMaaS API."""
def __init__(self, api_key: str, model_name: str):
if not api_key:
raise ValueError("The LLMaaS API key cannot be empty.")
self.api_key = api_key
self.model_name = model_name
self.base_url = BASE_URL
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
def _embed(self, texts: List[str]) -> List[List[float]]:
import httpx
payload = {"input": texts, "model": self.model_name}
try:
with httpx.Client(timeout=60.0) as client:
response = client.post(f"{self.base_url}/embeddings", headers=self.headers, json=payload)
response.raise_for_status()
data = response.json()['data']
data.sort(key=lambda e: e['index'])
return [item['embedding'] for item in data]
except httpx.HTTPStatusError as e:
print(f"HTTP error during embedding generation: {e.response.text}")
raise
except Exception as e:
print(f"An unexpected error occurred during embedding generation: {e}")
raise
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return self._embed(texts)
def embed_query(self, text: str) -> List[float]:
# The _embed method expects a list, so we wrap the single text.
return self._embed([text])[0]
# --- RAG Pipeline ---
def setup_rag_pipeline(documents_path: str):
"""Complete configuration of the RAG pipeline with LLMaaS tools."""
print("1. Loading and splitting documents...")
loader = DirectoryLoader(documents_path, glob="*.txt", loader_cls=TextLoader, loader_kwargs={'encoding': 'utf-8'})
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(documents)
print(f" -> {len(documents)} document(s) loaded and split into {len(splits)} chunks.")
print(f"2. Creating embeddings via LLMaaS (model: {EMBEDDING_MODEL})...")
embeddings = LLMaaSEmbeddings(api_key=API_KEY, model_name=EMBEDDING_MODEL)
print("3. Creating in-memory vector index (FAISS)...")
vectorstore = FAISS.from_documents(splits, embeddings)
print(" -> FAISS index created successfully.")
print(f"4. Configuring the LLM (model: {LLM_MODEL})...")
# Fix for Pydantic/LangChain compatibility
from langchain_core.caches import BaseCache
from langchain_core.callbacks.base import Callbacks
ChatOpenAI.model_rebuild()
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=LLM_MODEL,
temperature=0.3,
model_kwargs={"max_tokens": 300}
)
print("5. Creating the Question/Answer chain (RAG)...")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
print(" -> RAG pipeline ready.")
return qa_chain
# --- Execution ---
def main():
"""Main function to run the end-to-end RAG pipeline."""
if not API_KEY:
print("Error: The LLMAAS_API_KEY environment variable is not set.")
return
# Create temporary test documents
temp_dir = tempfile.mkdtemp()
print(f"\nCreating test documents in: {temp_dir}")
try:
documents_content = {
"overview.txt": "Cloud Temple is a French sovereign cloud provider qualified SecNumCloud.",
"pricing.txt": "The LLMaaS API pricing is €1.9 per million input tokens and €8 per million output tokens."
}
for filename, content in documents_content.items():
with open(Path(temp_dir) / filename, 'w', encoding='utf-8') as f:
f.write(content)
# Set up and run the pipeline
rag_chain = setup_rag_pipeline(temp_dir)
print("\n--- Querying the RAG Pipeline ---")
question = "What is the output token rate for the LLMaaS API at Cloud Temple?"
result = rag_chain({"query": question})
print(f"\nQuestion: {question}")
print(f"Answer: {result['result']}")
print("\nSources used for the answer:")
for source in result["source_documents"]:
print(f"- File: {os.path.basename(source.metadata['source'])}")
print(f" Content: \"{source.page_content}\"")
finally:
# Clean up the temporary directory
print(f"\nCleaning up temporary directory: {temp_dir}")
shutil.rmtree(temp_dir)
if __name__ == "__main__":
main()
3. Integration with a vector database (Qdrant)
For production RAG applications, using a dedicated vector database such as Qdrant is recommended. Unlike FAISS, which operates in memory, Qdrant provides data persistence, advanced search capabilities, and better scalability.
Code Explained
This tutorial adapts the previous RAG pipeline to use Qdrant.
- Prerequisites: The first step is to run a Qdrant instance. The easiest way is to use Docker.
setup_qdrant_rag_pipeline:- Embeddings and Documents: Creating embeddings and documents remains the same as in the previous example.
- Connecting to Qdrant: Instead of creating a FAISS index, we use
Qdrant.from_documents. This LangChain method handles several steps: a. It connects to your Qdrant instance via the provided URL. b. It creates a new "collection" (the equivalent of a table in a SQL database) if it doesn't already exist. c. It calls ourLLMaaSEmbeddingsclass to vectorize the documents. d. It inserts the documents and their vectors into the Qdrant collection. force_recreate=True: For this tutorial, we use this parameter to ensure the collection is empty on each run. In production, you would set it toFalseto preserve your data.
- The rest of the pipeline (LLM configuration, creation of the
RetrievalQAchain) remains identical, demonstrating LangChain's flexibility: simply changing theretriever(information retriever) source from FAISS to Qdrant is enough.
For this tutorial, you'll need a Qdrant instance. You can easily launch it with Docker:
# 1. Download the latest Qdrant image
docker pull qdrant/qdrant
# 2. Start the Qdrant container
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
The code below shows how to adapt the RAG pipeline to use Qdrant as the vector database.
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Qdrant
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from typing import List
from langchain_core.embeddings import Embeddings
# (The LLMaaSEmbeddings class is the same as in the previous example,
# We reuse it here. Make sure it is defined in your script.)
# --- Configuration ---
load_dotenv()
API_KEY = os.getenv("LLMAAS_API_KEY")
BASE_URL = os.getenv("API_URL", "https://api.ai.cloud-temple.com/v1")
EMBEDDING_MODEL = "granite-embedding:278m"
LLM_MODEL = "granite3.3:8b"
QDRANT_URL = os.getenv("QDRANT_URL", "http://localhost:6333")
QDRANT_COLLECTION_NAME = "tutorial_collection"
# --- Embedding Class (reused from previous example) ---
class LLMaaSEmbeddings(Embeddings):
def __init__(self, api_key: str, model_name: str):
if not api_key: raise ValueError("API Key is required.")
self.api_key, self.model_name, self.base_url = api_key, model_name, BASE_URL
self.headers = {"Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json"}
def _embed(self, texts: List[str]) -> List[List[float]]:
import httpx
payload = {"input": texts, "model": self.model_name}
with httpx.Client(timeout=60.0) as client:
r = client.post(f"{self.base_url}/embeddings", headers=self.headers, json=payload)
r.raise_for_status()
data = r.json()['data']
data.sort(key=lambda e: e['index'])
return [item['embedding'] for item in data]
def embed_documents(self, texts: List[str]) -> List[List[float]]: return self._embed(texts)
def embed_query(self, text: str) -> List[float]: return self._embed([text])[0]
def setup_qdrant_rag_pipeline():
"""Configure and return a RAG pipeline using Qdrant."""
print("1. Initializing LLMaaS embedding client...")
embeddings = LLMaaSEmbeddings(api_key=API_KEY, model_name=EMBEDDING_MODEL)
print("2. Preparing documents...")
documents_content = [
"Cloud Temple is a French sovereign cloud provider with SecNumCloud certification.",
"LLMaaS pricing is 1.9€ for input and 8€ for output per million tokens."
]
documents = [Document(page_content=d) for d in documents_content]
print(f"3. Connecting to Qdrant and populating collection '{QDRANT_COLLECTION_NAME}'...")
vectorstore = Qdrant.from_documents(
documents,
embeddings,
url=QDRANT_URL,
collection_name=QDRANT_COLLECTION_NAME,
force_recreate=True, # Ensures a clean collection for the tutorial
)
print(" -> Collection created and populated successfully.")
print(f"4. Configuring LLM ({LLM_MODEL})...")
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=LLM_MODEL,
temperature=0.3
)
print("5. Creating the RAG chain...")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
print(" -> Qdrant-based RAG pipeline ready.")
return qa_chain
# --- Execution ---
def main_qdrant():
"""Main function to run the RAG pipeline with Qdrant."""
if not API_KEY:
print("Error: The LLMAAS_API_KEY environment variable is not set.")
return
try:
rag_chain = setup_qdrant_rag_pipeline()
question = "What are the pricing details for Cloud Temple's LLMaaS API?"
print(f"\n--- Querying the pipeline ---")
result = rag_chain({"query": question})
print(f"\nQuestion: {question}")
print(f"Answer: {result['result']}")
print("\nSources used for the answer:")
for source in result["source_documents"]:
print(f"- Content: \"{source.page_content}\"")
except Exception as e:
print(f"\nAn error occurred: {e}")
print("Please ensure the Qdrant container is running.")
if __name__ == "__main__":
main_qdrant()
4. LangChain Agents with Tools
An agent is an LLM that does more than simply answer a question—it can use a set of tools (functions, APIs, etc.) to build a more complex response. It can reason, break down a problem, select an appropriate tool, execute it, observe the result, and repeat this cycle until it arrives at a final answer.
Code Explained
This example builds a simple agent capable of using two tools: one to query a (simulated) Cloud Temple API, and another to perform calculations.
-
Tool Definitions: The classes
CloudTempleAPIToolandCalculatorToolinherit fromBaseTool. Each tool has:- A
name: a simple and descriptive name. - A
description: crucial—this is what the LLM reads to decide which tool to use. It must be very clear about what the tool does and when to use it. - A
_runmethod: the actual code executed when the agent selects this tool.
- A
-
create_agent_with_tools:- LLM Initialization: We use our
CloudTempleLLMwrapper defined in the first tutorial. - Tool List: We provide the agent with a list of tools it is allowed to use.
- Agent Prompt: The prompt is highly specific. It's a "reasoning prompt" that instructs the LLM on how to think (
Thought), choose an action (Action), provide input for that action (Action Input), and observe the result (Observation). This is the core mechanism of the ReAct framework (Reasoning and Acting) used here. - Agent Creation:
create_react_agentassembles the LLM, tools, and prompt to create the agent. AgentExecutor: This is the engine that runs the agent in a loop until it produces aFinal Answer. Theverbose=Trueparameter is very useful for seeing the agent's "inner dialogue" (its thoughts, actions, etc.).
- LLM Initialization: We use our
from langchain.agents import Tool, AgentExecutor, create_react_agent
from langchain.tools import BaseTool
from langchain.prompts import PromptTemplate
import requests
import json
import os
# (The CloudTempleLLM class is the same as in the first example)
# --- Tool Definitions ---
class CloudTempleAPITool(BaseTool):
"""A tool that simulates calling an internal API to retrieve information about services."""
name = "cloud_temple_api_checker"
description = "Useful for obtaining information about services, products, and offerings from Cloud Temple."
def _run(self, query: str) -> str:
# In a real scenario, this would call a real API.
print(f"--- CloudTempleAPITool called with query: '{query}' ---")
if "service" in query.lower():
return "Cloud Temple offers the following services: IaaS, PaaS, LLMaaS, Managed Security."
return "Information not found."
async def _arun(self, query: str) -> str:
# Asynchronous implementation not needed for this example.
raise NotImplementedError("The API tool does not support asynchronous execution.")
class SimpleCalculatorTool(BaseTool):
"""A simple tool for performing mathematical calculations."""
name = "simple_calculator"
description = "Useful for performing simple mathematical calculations. Takes a valid Python expression."
def _run(self, expression: str) -> str:
print(f"--- SimpleCalculatorTool called with expression: '{expression}' ---")
try:
# WARNING: eval() is dangerous in production. This is only for demo purposes.
return str(eval(expression))
except Exception as e:
return f"Calculation error: {e}"
async def _arun(self, expression: str) -> str:
raise NotImplementedError("The Calculator tool does not support asynchronous execution.")
# --- Agent Creation ---
def create_agent():
"""Configure and return a LangChain agent with the defined tools."""
print("1. Initializing the LLM for the agent...")
llm = CloudTempleLLM(api_key=os.getenv("LLMAAS_API_KEY", "your-api-key-here"))
tools = [CloudTempleAPITool(), SimpleCalculatorTool()]
# The prompt template is crucial: it guides the LLM in its reasoning.
template = """
Answer the following questions as best as you can. You have access to the following tools:
{tools}
Use the following format:
Question: the question you must answer
Thought: you must always think about what you will do
Action: the action to take, must be one of [{tool_names}]
Action Input: the input for the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation sequence can repeat)
Thought: I now know the final answer.
Final Answer: the final answer to the original question
Begin!
Question: {input}
Thought:{agent_scratchpad}
"""
prompt = PromptTemplate.from_template(template)
print("2. Creating the agent using the ReAct framework...")
agent = create_react_agent(llm, tools, prompt)
# The AgentExecutor is responsible for running the agent's cycles.
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
print(" -> Agent ready.")
return agent_executor
# --- Execution ---
def run_agent():
"""Executes the agent with different questions to test its capabilities."""
if os.getenv("LLMAAS_API_KEY") is None:
print("Please set your LLMAAS_API_KEY.")
return
agent_executor = create_agent()
print("\n--- Test 1: Question requiring an information tool ---")
question1 = "What services are offered by Cloud Temple?"
response1 = agent_executor.invoke({"input": question1})
print(f"\nFinal agent response: {response1['output']}")
print("\n--- Test 2: Question requiring a calculation ---")
question2 = "What is the result of 125 * 8 + 50?"
response2 = agent_executor.invoke({"input": question2})
print(f"\nFinal agent response: {response2['output']}")
if __name__ == "__main__":
run_agent()
5. OpenAI SDK Integration
Seamless migration from OpenAI
from openai import OpenAI
# Configuration for Cloud Temple LLMaaS
def setup_cloud_temple_client():
"""OpenAI client configuration for Cloud Temple"""
client = OpenAI(
api_key="your-cloud-temple-api-key",
base_url="https://api.ai.cloud-temple.com/v1"
)
return client
def test_openai_compatibility():
"""Test compatibility with OpenAI SDK"""
client = setup_cloud_temple_client()
# Standard chat completion
response = client.chat.completions.create(
model="granite3.3:8b",
messages=[
{"role": "system", "content": "You are a professional AI assistant."},
{"role": "user", "content": "Explain cloud-native architecture to me."}
],
max_tokens=300,
temperature=0.7
)
print(f"Response: {response.choices[0].message.content}")
# Streaming
stream = client.chat.completions.create(
model="granite3.3:8b",
messages=[
{"role": "user", "content": "Write a poem about AI."}
],
stream=True,
max_tokens=200
)
print("Stream:")
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
print()
# Compatibility Test
test_openai_compatibility()
6. Semantic Kernel (Microsoft)
Semantic Kernel is an open-source SDK from Microsoft that enables integrating LLMs into .NET, Python, and Java applications. Although it is optimized for Azure OpenAI services, its flexibility allows it to be used with any OpenAI-compatible API, including our own.
Code Explained
This example does not require the full Semantic Kernel SDK. It demonstrates how the concept of a "semantic function" can be implemented with a simple call to our API. A semantic function is essentially a structured prompt sent to a Large Language Model (LLM) to perform a specific task.
semantic_kernel_simple(): This function simulates a "summarization function."- Structured Prompt: We use a
systemmessage to assign a role to the LLM ("You are an expert in summarization") and ausermessage containing the text to summarize. This is the core of the semantic function concept. - Direct API Call: A simple
requests.postcall to our/v1/chat/completionsendpoint is sufficient to execute the function.
This example illustrates that it's not always necessary to use a heavy framework. For simple, well-defined tasks, a direct call to the LLMaaS API is often the most efficient and performant solution.
import requests
import os
from dotenv import load_dotenv
def semantic_kernel_simulation():
"""
Simulates a "semantic function" for summarization by directly calling the LLMaaS API.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Please set the LLMAAS_API_KEY environment variable.")
return
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
text_to_summarize = """
Artificial intelligence (AI) is transforming numerous industrial sectors by automating tasks,
optimizing processes, and enabling advanced predictive analytics.
Cloud Temple, with its sovereign and SecNumCloud-certified LLMaaS offering, allows enterprises
to integrate these AI capabilities while ensuring the security and confidentiality of their data.
"""
# The prompt combines an instruction (system role) and data (user role)
payload = {
"model": "granite3.3:8b",
"messages": [
{"role": "system", "content": "You are an expert assistant for summarizing technical documents."},
{"role": "user", "content": f"Summarize the following text in a single concise sentence: {text_to_summarize}"}
],
"max_tokens": 100,
"temperature": 0.5
}
try:
response = requests.post(
"https://api.ai.cloud-temple.com/v1/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
summary = result['choices'][0]['message']['content']
print("Original text:\n", text_to_summarize)
print("\nGenerated summary:\n", summary)
return summary
except requests.exceptions.RequestException as e:
print(f"An API error occurred: {e}")
if __name__ == "__main__":
semantic_kernel_simulation()
7. Haystack Framework
Haystack is another powerful open-source framework for building semantic search, RAG, and agent applications. As with Semantic Kernel, our API can be integrated directly.
Code Explained
This example simulates a basic Haystack-style "pipeline" for question answering within a given context (Question Answering).
process_with_context: This function represents the core of a QA pipeline. It takes acontext(for example, a paragraph from a document) and aquestion.- Contextual Prompt: The prompt is carefully structured to include both the context and the question. This is a fundamental technique in RAG: we provide the LLM with relevant information so it can formulate a factual response.
- API Call: Once again, a simple
requests.postcall to our API is sufficient. The LLM receives the context and the question, and its task is to synthesize a response based solely on the provided information.
This example demonstrates the flexibility of the LLMaaS API, which can serve as a foundational building block for text generation in any framework—even those for which no official integration exists.
import requests
import os
from dotenv import load_dotenv
def haystack_simulation():
"""
Simulates a Haystack-style Question-Answering pipeline
using a direct call to the LLMaaS API.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Please set the LLMAAS_API_KEY environment variable.")
return
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# The context is the information the LLM is allowed to use.
context = """
A sovereign cloud is a cloud computing infrastructure that is entirely contained
within the borders of a specific country and subject to its laws.
The main advantages include guaranteed data residency, compliance with local regulations
(such as GDPR in Europe), and enhanced protection against access by foreign entities
under extraterritorial laws like the U.S. CLOUD Act.
"""
question = "What are the benefits of a sovereign cloud?"
# The prompt guides the LLM to base its response solely on the provided context.
prompt = f"""
Answer the question based exclusively on the following context.
Context:
---
{context}
---
Question: {question}
"""
payload = {
"model": "granite3.3:8b",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 200,
"temperature": 0.2 # Low temperature for factual responses
}
try:
response = requests.post(
"https://api.ai.cloud-temple.com/v1/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
answer = result['choices'][0]['message']['content']
print(f"Question: {question}")
print("\nGenerated Answer:\n", answer)
return answer
except requests.exceptions.RequestException as e:
print(f"An API error occurred: {e}")
if __name__ == "__main__":
haystack_simulation()
8. LlamaIndex Integration
LlamaIndex is a framework specialized in building RAG applications. It provides high-level components for data ingestion, indexing, and querying. Our API, being compatible with the OpenAI interface, integrates very easily.
Code Explanation
This example demonstrates how to configure LlamaIndex to use the LLMaaS API for text generation, while using a local embedding model for vectorization.
setup_and_run_llamaindex: This single function orchestrates the entire process.- LLM Configuration: LlamaIndex provides the
OpenAILikeclass, which allows connecting to any API that follows the OpenAI format. Simply provide yourapi_baseand anapi_key. This is the easiest way to make your LLM compatible. - Embedding Configuration: For this example, we use a local embedding model (
HuggingFaceEmbedding). This illustrates the flexibility of LlamaIndex, which allows mixing different components. You could just as easily use theLLMaaSEmbeddingsclass from previous examples to use our embedding API. Settings: TheSettingsobject in LlamaIndex is a convenient way to set default components (LLM, embedding model, chunk size, etc.) that will be used by other LlamaIndex objects.- Data Ingestion:
SimpleDirectoryReaderloads documents from a directory. - Index Creation:
VectorStoreIndex.from_documentsis LlamaIndex’s high-level method. It automatically handles chunking, vectorizing the chunks (using theembed_modelconfigured inSettings), and creating an in-memory index. - Query Engine:
.as_query_engine()creates a simple interface for asking questions against your index. When you call.query(), the engine vectorizes your question, finds the most relevant documents in the index, and sends them to the LLM (configured inSettings) along with the question to generate a response.
- LLM Configuration: LlamaIndex provides the
# Dependencies:
# pip install llama-index llama-index-llms-openai-like llama-index-embeddings-huggingface
import os
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai_like import OpenAILike
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import shutil
def setup_and_run_llamaindex():
"""
Configure and run a simple RAG pipeline with LlamaIndex and the LLMaaS API.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Please set the LLMAAS_API_KEY environment variable.")
return
# 1. Configure the LLM to use the LLMaaS API via the OpenAILike interface
print("1. Configuring the LLM to point to the LLMaaS API...")
llm = OpenAILike(
api_key=api_key,
api_base="https://api.ai.cloud-temple.com/v1",
model="granite3.3:8b",
is_chat_model=True,
# Sometimes it's necessary to add context window parameters for certain models
# context_window=3900,
)
# 2. Configure the embedding model (local in this example for simplicity)
print("2. Configuring the local embedding model...")
embed_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 3. Apply configurations globally via LlamaIndex's Settings object
Settings.llm = llm
Settings.embed_model = embed_model
print(" -> LLM and embedding model configured.")
# 4. Create a simple knowledge base in a temporary directory
print("4. Creating and loading a temporary knowledge base...")
temp_dir = "temp_llama_data"
os.makedirs(temp_dir, exist_ok=True)
knowledge_file = os.path.join(temp_dir, "knowledge.txt")
with open(knowledge_file, "w", encoding="utf-8") as f:
f.write("The LLMaaS offering from Cloud Temple is a sovereign generative AI solution, "
"fully operated in France and certified SecNumCloud by ANSSI.")
documents = SimpleDirectoryReader(temp_dir).load_data()
print(f" -> {len(documents)} document(s) loaded.")
# 5. Create the vector index. LlamaIndex handles chunking and embedding automatically.
print("5. Creating the vector index...")
index = VectorStoreIndex.from_documents(documents)
print(" -> Index created.")
# 6. Create the query engine and query the knowledge base
print("6. Creating the query engine and querying...")
query_engine = index.as_query_engine()
question = "What are the sovereignty guarantees of the LLMaaS offering?"
response = query_engine.query(question)
print(f"\nQuestion: {question}")
print(f"Answer: {response}")
# Clean up the temporary directory
shutil.rmtree(temp_dir)
print(f"\nTemporary directory '{temp_dir}' deleted.")
if __name__ == "__main__":
setup_and_run_llamaindex()
8. Configuring the CLINE Extension for VSCode
This tutorial guides you through setting up the CLINE extension in Visual Studio Code to use Cloud Temple's language models directly from your editor.
Configuration Steps
-
Open CLINE Settings: In VSCode, open the settings for the CLINE extension.
-
Create a New Model: Add a new model configuration.
-
Fill in the Fields: Configure the fields as shown below, based on the image below.
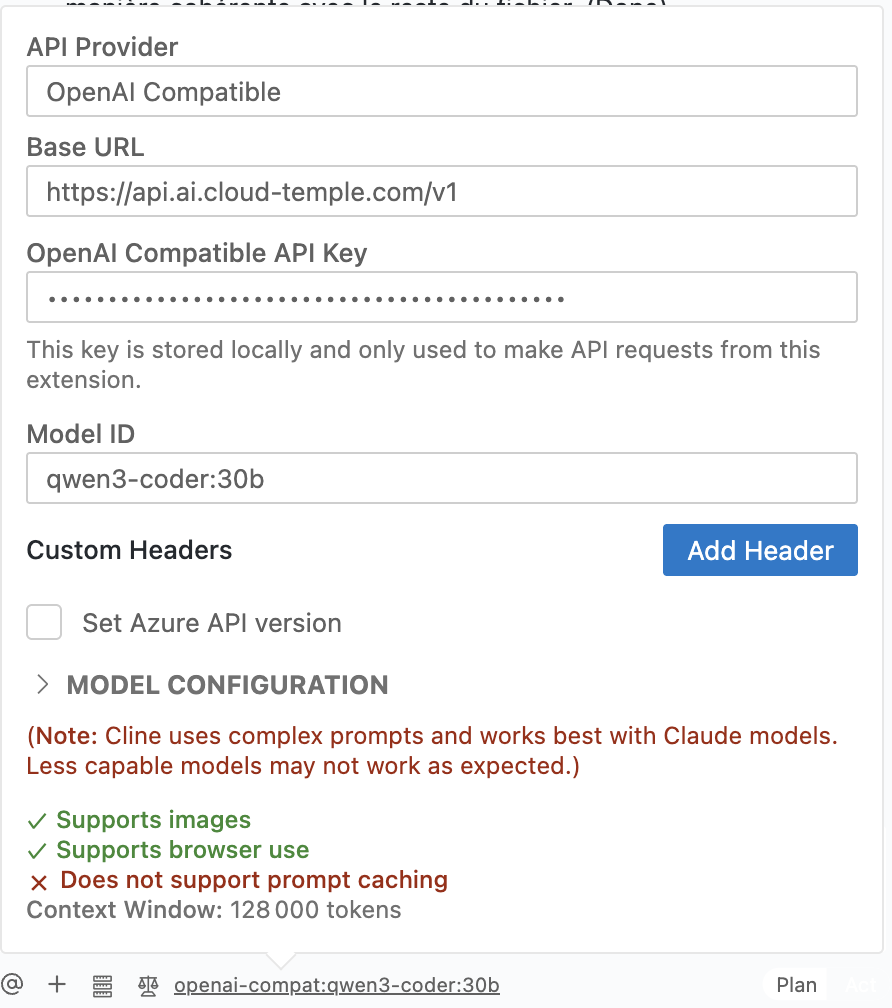
- API Provider: Select
OpenAI Compatible. - Base URL: Enter the LLMaaS API endpoint from Cloud Temple:
https://api.ai.cloud-temple.com/v1. - OpenAI Compatible API Key: Paste the API key you generated from the Cloud Temple console.
:::tip Generate API Key To generate your API key, go to the Cloud Temple console, navigate to LLMaaS > API Keys, then click "Create API Key".
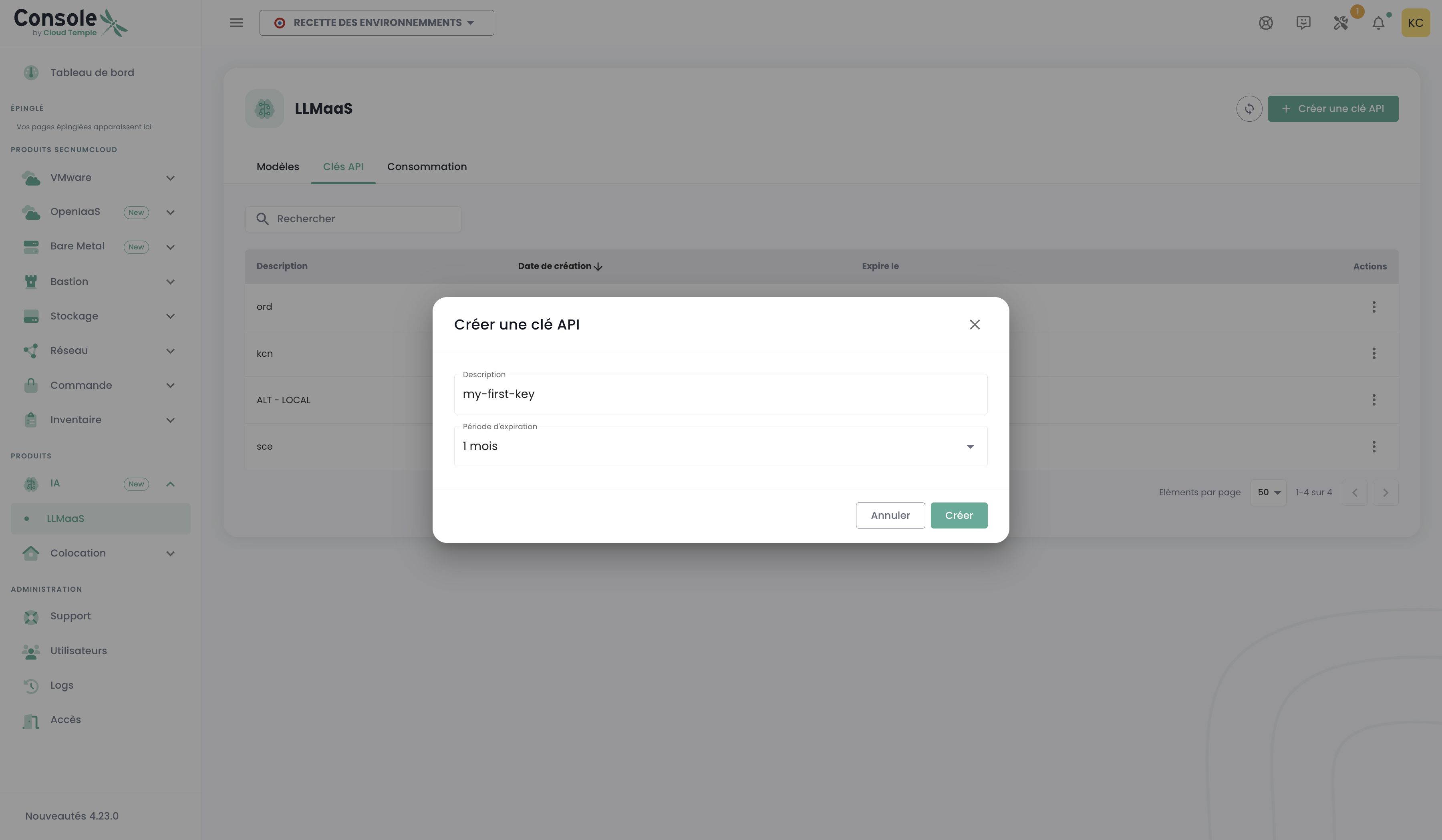 :::
:::- Model ID: Specify the model you want to use, for example
qwen3-coder:30b. You can find the list of available models in the Models section. - Model Configuration:
- Supports Images: Check this box if the model supports images.
- Supports browser use: Check this box.
- Context Window Size: Enter the model's context window size (e.g.,
128000). - Max Output Tokens: Leave as
-1for unlimited output by default. - Temperature: Set the temperature according to your needs (e.g.,
0).
- API Provider: Select
You can now select a model in CLINE and use it to generate code, answer questions, and more.
💡 Advanced Examples
The GitHub directory below contains a collection of code examples and scripts demonstrating the various features and use cases of Cloud Temple's LLM as a Service (LLMaaS) offering:
Cloud-Temple/product-llmaas-how-to
You'll find practical guides for:
-
Information Extraction and Text Analysis: Ability to analyze documents and extract structured data such as entities, events, relationships, and attributes, leveraging domain-specific ontologies (e.g., legal, HR, IT).
-
Conversational Interaction and Chatbots: Development of conversational agents capable of dialogue, maintaining conversation history, using system prompts, and invoking external tools.
-
Audio Transcription (Speech-to-Text): Conversion of audio content into text, including for large files, using techniques such as segmentation, normalization, and batch processing.
-
Text Translation: Translation of documents from one language to another, managing context across multiple segments to improve coherence.
-
Model Management and Evaluation: Listing available language models via the API, checking their specifications, and running tests to compare performance.
-
Real-Time Response Streaming: Demonstration of the ability to receive and display model responses progressively (token by token), essential for interactive applications.
-
RAG Pipeline with In-Memory Knowledge Base: Educational RAG demonstrator illustrating the Retrieval-Augmented Generation workflow. Uses the LLMaaS API for embedding and generation, with vector storage in memory (FAISS) for clear understanding of the process.
-
RAG Pipeline with Vector Database (Qdrant): Complete, containerized RAG demonstrator using Qdrant as the vector database. The LLMaaS API is used for document embedding and generating augmented responses.
-
OCR & Document Analysis (DeepSeek-OCR): Comprehensive guide and demonstration tool to convert images and PDFs into structured Markdown, extract tables, and transcribe mathematical formulas. See the dedicated documentation.