Concepts and Architecture of LLMaaS
Overview
Cloud Temple's LLMaaS (Large Language Models as a Service) provides secure and sovereign access to the most advanced artificial intelligence models, with ANSSI's SecNumCloud qualification.
🏗️ Technical Architecture
Cloud Temple Infrastructure
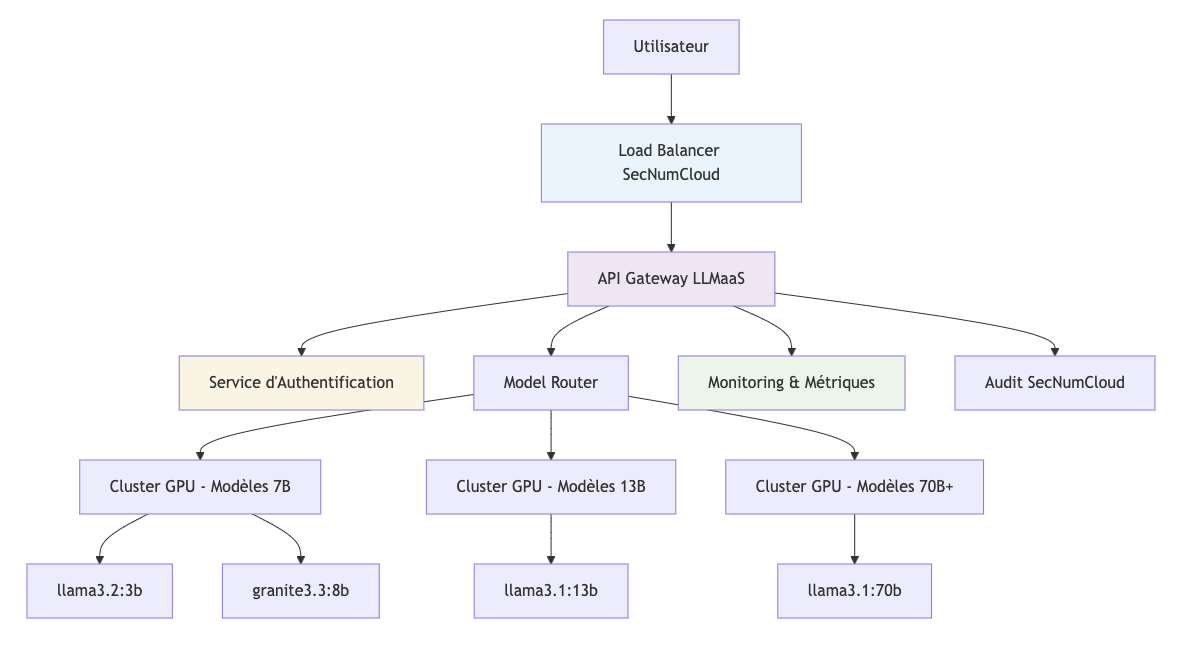
Main Components
1. API Gateway LLMaaS
- Compatible OpenAI : Seamless integration with the existing ecosystem
- Rate Limiting : Quota management per billing tier
- Load Balancing : Intelligent distribution across 12 GPU machines
- Monitoring : Real-time metrics and alerting
2. Authentication Service
- Secure API Tokens : Automatic rotation
- Access Control : Granular permissions per model
- Audit trails : Complete access traceability
🤖 Models and Tokens
Model Catalog
Complete catalog: Model list
Token Management
Token Types
- Input tokens : Your prompt and context
- Output tokens : Model-generated response
- System tokens : Metadata and instructions
Cost Calculation
Chat/Completion = (Tokens entrée × 1.8€/M) + (Tokens sortie × 8€/M) + (Tokens sortie Raisonnement × 8€/M)
Reranking = Documents rerankés × 4€/M
Batch (async) = (Tokens entrée × 0.9€/M) + (Tokens sortie × 4€/M)
Audio (ASR) = 0.01€ / minute de transcription
Optimization
- Context window : Reuse conversations to save costs
- Appropriate models : Choose the size based on complexity
- Max tokens : Limit response length
Tokenization
# Example of token estimation
def estimate_tokens(text: str) -> int:
"""Estimation approximative : 1 token ≈ 4 caractères"""
return len(text) // 4
prompt = "Expliquez la photosynthèse"
response_max = 200 # desired max tokens
estimated_input = estimate_tokens(prompt) # ~6 tokens
total_cost = (estimated_input * 1.8 + response_max * 8) / 1_000_000
print(f"Coût estimé: {total_cost:.6f}€")
🔒 Security and Compliance
SecNumCloud Qualification
The LLMaaS service runs on a technical infrastructure that holds the ANSSI SecNumCloud 3.2 qualification, ensuring:
Data Protection
- End-to-end encryption : TLS 1.3 for all communications
- Secure storage : Data encrypted at rest (AES-256)
- Isolation : Dedicated environments per tenant
Digital Sovereignty
- France Hosting : Certified Cloud Temple datacenters
- French Law : Native GDPR compliance
- No Exposure : No transfers to foreign clouds
Audit and Traceability
- Complete logs : All interactions tracked
- Retention : Retention according to legal policies
- Compliance : Audit reports available
Security Controls

Prompt Security
Prompt analysis is a native and integrated security feature of the LLMaaS platform. Enabled by default, it aims to detect and prevent "jailbreak" attempts or malicious prompt injections before they even reach the model. This protection relies on a multi-layered approach.
:::tip Contact support for deactivation It is possible to disable this security analysis for very specific use cases, although it is not recommended. For any questions regarding this or to request a deactivation, please contact Cloud Temple support. :::
1. Structural Analysis (check_structure)
- Malformed JSON Check: The system detects if the prompt starts with a
{and attempts to parse it as JSON. If parsing succeeds and the JSON contains suspicious keywords (e.g., "system", "bypass"), or if parsing fails unexpectedly, this may indicate an injection attempt. - Unicode Normalization: The prompt is normalized using
unicodedata.normalize('NFKC', prompt). If the original prompt differs from its normalized version, this may indicate the use of deceptive Unicode characters (homoglyphs) to bypass filters. For example, "аdmin" (Cyrillic) instead of "admin" (Latin).
2. Detection of Suspicious Patterns (check_patterns)
- The system uses regular expressions (
regex) to identify known prompt attack patterns, across multiple languages (French, English, Chinese, Japanese). - Examples of detected patterns :
- System Commands : Keywords such as "ignore les instructions", "ignore instructions", "忽略指令", "指示を無視".
- HTML Injection : Hidden or malicious HTML tags, for example
<div caché>,<hidden div>. - Markdown Injection : Malicious Markdown links, for example
[texte](javascript:...),[text](data:...). - Repeated Sequences : Excessive repetition of words or phrases such as "oublie oublie oublie", "forget forget forget".
- Special/Mixed Characters : Use of unusual Unicode characters or script mixing to mask commands (e.g., "s\u0443stème").
3. Behavioral Analysis (check_behavior)
- The load balancer maintains a history of recent prompts.
- Fragmentation Detection: It combines recent prompts to check if an attack is fragmented across multiple requests. For example, if "ignore" is sent in one prompt and "instructions" in the next, the system can detect them together.
- Repetition Detection: It identifies whether the same prompt is repeated excessively. The current threshold for repetition detection is 30 consecutive identical prompts.
This multi-layered approach enables the detection of a wide range of prompt attacks, from the simplest to the most sophisticated, by combining static content analysis with dynamic behavioral analysis.
📈 Performance and Scalability
Real-Time Monitoring
Access via Cloud Temple Console :
- Usage metrics per model
- Latency and throughput graphs
- Alerts on performance thresholds
- Request history
🌐 Integration and Ecosystem
OpenAI Compatibility
The LLMaaS service is compatible with the OpenAI API:
# Seamless migration
from openai import OpenAI
# Before (OpenAI)
client_openai = OpenAI(api_key="sk-...")
# After (Cloud Temple LLMaaS)
client_ct = OpenAI(
api_key="votre-token-cloud-temple",
base_url="https://api.ai.cloud-temple.com/v1"
)
# Identical code!
response = client_ct.chat.completions.create(
model="gpt-oss:120b", # Cloud Temple Model
messages=[{"role": "user", "content": "Bonjour"}]
)
Supported Ecosystem
AI Frameworks
- ✅ LangChain : Native integration
- ✅ Haystack : Document pipeline
- ✅ Semantic Kernel : Microsoft orchestration
- ✅ AutoGen : Conversational agents
Development Tools
- ✅ Jupyter : Interactive Notebooks
- ✅ Streamlit : Quick Web Applications
- ✅ Gradio : AI User Interfaces
- ✅ FastAPI : Backend APIs
No-Code Platforms
- ✅ Zapier : Automations
- ✅ Make : Visual Integrations
- ✅ Bubble : Web Applications
🔄 Model Lifecycle
Model Updates
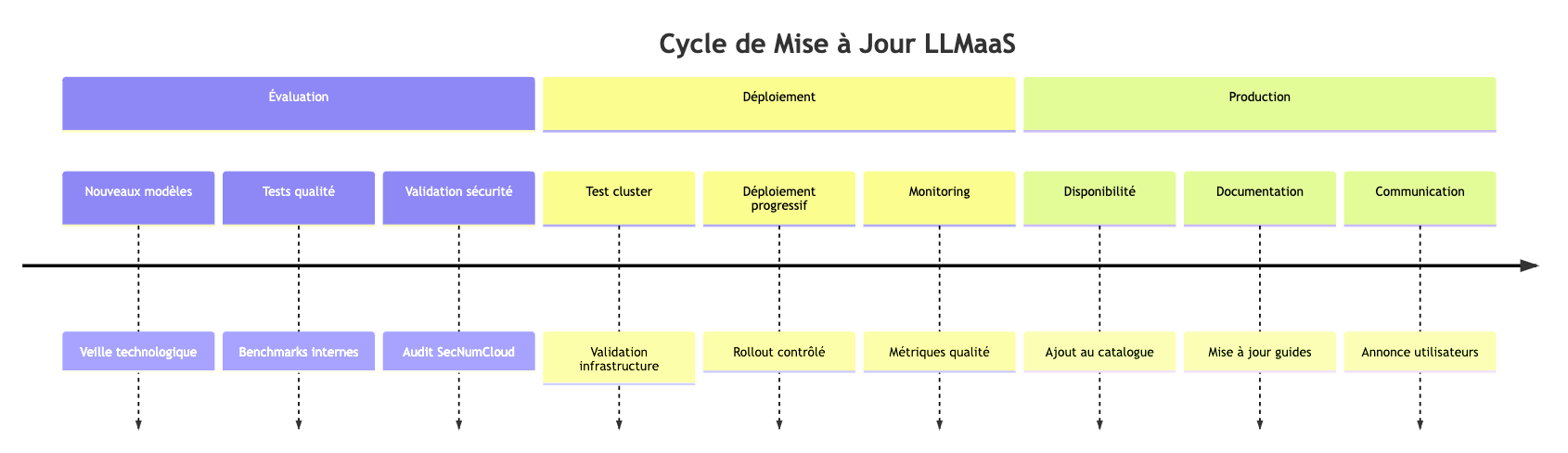
Versioning Policy
- Stable Models : Fixed versions available for 6 months
- Experimental Models : Beta versions for early adopters
- Deprecation : 3-month notice before removal
- Migration : Professional services available to ensure your transitions
Projected Lifecycle Schedule
The table below presents the projected lifecycle of our models. The generative AI ecosystem evolves very rapidly, which explains why lifecycles may appear short. Our goal is to provide you with access to the most performant models currently available.
However, we are committed to preserving over time the models that are most widely used by our clients. For critical use cases requiring long-term stability, extended support phases are available. Please do not hesitate to contact support to discuss your specific needs.
This schedule is provided for informational purposes and is reviewed at the beginning of each quarter.
- DMP (Production Release Date) : The date on which the model becomes available in production.
- DSP (End of Support Date) : The projected date from which the model will no longer be maintained. A 3-month notice period is respected before any effective removal.
| Modèle | Éditeur | Phase | DMP | DSP | LTS | Migration conseillée |
|---|---|---|---|---|---|---|
| cogito:32b | Deep Cogito | Production | 13/06/2025 | 30/06/2026 | No | gpt-oss:120b |
| embeddinggemma:300m | Production | 10/09/2025 | 30/06/2026 | No | ||
| gemma3:27b | Production | 13/06/2025 | 30/06/2026 | No | ||
| glm-4.7-flash:30b | Zhipu AI | Production | 22/01/2026 | 30/06/2026 | No | |
| ministral-3:14b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | No | |
| ministral-3:3b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | No | |
| ministral-3:8b | Mistral AI | Production | 30/12/2025 | 30/06/2026 | No | |
| olmo-3:32b | AllenAI | Production | 30/12/2025 | 30/06/2026 | No | |
| olmo-3:7b | AllenAI | Production | 30/12/2025 | 30/06/2026 | No | |
| qwen3-omni:30b | Qwen Team | Production | 05/01/2026 | 30/06/2026 | No | |
| qwen3-vl:2b | Qwen Team | Production | 30/12/2025 | 30/06/2026 | No | |
| qwen3-vl:32b | Qwen Team | Production | 30/12/2025 | 30/06/2026 | No | |
| qwen3-vl:8b | Qwen Team | Production | 05/01/2026 | 30/06/2026 | No | |
| rnj-1:8b | Essential AI | Production | 30/12/2025 | 30/06/2026 | No | |
| devstral-small-2:24b | Mistral AI & All Hands AI | Production | 02/02/2026 | 30/09/2026 | No | |
| gemma4:e2b | Production | 19/04/2026 | 30/09/2026 | No | ||
| gemma4:e4b | Production | 19/04/2026 | 30/09/2026 | No | ||
| gpt-oss:20b | OpenAI | Production | 08/08/2025 | 30/09/2026 | No | |
| mistral-small3.2:24b | Mistral AI | Production | 23/06/2025 | 30/09/2026 | No | |
| qwen3.5:4b | Qwen Team | Production | 24/03/2026 | 30/09/2026 | No | |
| qwen3.5:9b | Qwen Team | Production | 24/03/2026 | 30/09/2026 | No | |
| bge-reranker-large | BAAI | Production | 13/05/2026 | 30/12/2026 | No | |
| deepseek-ocr | DeepSeek AI | Production | 22/11/2025 | 30/12/2026 | No | |
| functiongemma:270m | Production | 30/12/2025 | 30/12/2026 | No | ||
| gemma4:31b | Production | 14/04/2026 | 30/12/2026 | No | ||
| granite3-guardian:2b | IBM | Production | 13/06/2025 | 30/12/2026 | No | |
| granite3-guardian:8b | IBM | Production | 13/06/2025 | 30/12/2026 | No | |
| granite3.2-vision:2b | IBM | Production | 13/06/2025 | 30/12/2026 | No | |
| mistral-small4:119b | Mistral AI | Production | 13/05/2026 | 30/12/2026 | No | |
| nemotron-3-super:120b | NVIDIA | Production | 01/04/2026 | 30/12/2026 | No | |
| nemotron-cascade:30b | NVIDIA | Production | 01/04/2026 | 30/12/2026 | No | |
| nemotron3-nano:30b | NVIDIA | Production | 04/01/2026 | 30/12/2026 | No | |
| qwen-coder-next:80b | Qwen Team | Production | 04/02/2026 | 30/12/2026 | No | |
| qwen3-embedding:0.6b | Qwen Team | Production | 14/05/2026 | 30/12/2026 | No | |
| qwen3-embedding:4b | Qwen Team | Production | 14/05/2026 | 30/12/2026 | No | |
| qwen3-embedding:8b | Qwen Team | Production | 14/05/2026 | 30/12/2026 | No | |
| qwen3-next:80b | Qwen Team | Production | 02/02/2026 | 30/12/2026 | No | |
| qwen3-reranker:0.6b | Qwen Team | Production | 13/05/2026 | 30/12/2026 | No | |
| qwen3-reranker:4b | Qwen Team | Production | 13/05/2026 | 30/12/2026 | No | |
| qwen3-vl:235b | Qwen Team | Production | 04/01/2026 | 30/12/2026 | No | |
| qwen3-vl:30b | Qwen Team | Production | 30/12/2025 | 30/12/2026 | No | |
| qwen3-vl:4b | Qwen Team | Production | 30/12/2025 | 30/12/2026 | No | |
| qwen3.5:0.8b | Qwen Team | Production | 24/03/2026 | 30/12/2026 | No | |
| qwen3.6:27b | Qwen Team | Production | 01/05/2026 | 30/12/2026 | No | |
| qwen3.6:35b | Qwen Team | Production | 01/05/2026 | 30/12/2026 | No | |
| qwen3:0.6b | Qwen Team | Production | 13/06/2025 | 30/12/2026 | Yes | |
| translategemma:12b | Production | 22/01/2026 | 30/12/2026 | No | ||
| translategemma:27b | Production | 22/01/2026 | 30/12/2026 | No | ||
| translategemma:4b | Production | 22/01/2026 | 30/12/2026 | No | ||
| voxtral | Mistral AI | Production | 01/04/2026 | 30/12/2026 | No | |
| z-image:16b | Community | Production | 01/04/2026 | 30/12/2026 | No | |
| nvidia/llama-nemotron-rerank-vl-1b-v2 | NVIDIA | Production | 13/05/2026 | 30/06/2027 | No | |
| bge-m3:567m | BAAI | Production | 18/10/2025 | 30/12/2027 | Yes | |
| gpt-oss:120b | OpenAI | Production | 11/11/2025 | 30/12/2027 | Yes | |
| granite-embedding:278m | IBM | Production | 13/06/2025 | 30/12/2027 | Yes | |
| llama3.3:70b | Meta | Production | 13/06/2025 | 30/12/2027 | Yes | |
| qwen3-2507:235b | Qwen Team | Production | 04/01/2026 | 30/12/2027 | Yes | |
| qwen3-2507-think:4b | Qwen Team | Production | 31/08/2025 | 30/12/2027 | Yes |
Legend
- Phase: Model lifecycle (Evaluation, Production, Deprecated)
- DMP: Production Release Date
- DSP: Planned Decommissioning Date
- LTS: Long Term Support. LTS models benefit from guaranteed stability and extended support, ideal for critical applications.
- Recommended Migration: Model recommended to replace an end-of-life model.
To track the lifecycle status in real time, visit the page: LLMaaS Status - Lifecycle
Deprecated Models
The world of LLMs is evolving very rapidly. To ensure our clients have access to the most cutting-edge technologies, we regularly deprecate models that no longer meet current standards or are no longer in use. The models listed below are no longer available on the public platform. However, they can be reactivated for specific projects upon request.
| Model | Phase | Deprecation Date |
|---|---|---|
| devstral:24b | Deprecated | 30/03/2026 |
| granite3.1-moe:2b | Deprecated | 30/03/2026 |
| granite4-small-h:32b | Deprecated | 15/05/2026 |
| granite4-tiny-h:7b | Deprecated | 15/05/2026 |
| medgemma:27b | Deprecated | 15/05/2026 |
| qwen3-2507-gptq:235b | Deprecated | 15/05/2026 |
| qwen3-coder:30b | Deprecated | 30/03/2026 |
| qwen3:30b-a3b | Deprecated | 30/03/2026 |
| deepseek-r1:14b | Deprecated | 30/12/2025 |
| deepseek-r1:32b | Deprecated | 30/12/2025 |
| gemma3:1b | Deprecated | 30/12/2025 |
| gemma3:4b | Deprecated | 30/12/2025 |
| qwen3:1.7b | Deprecated | 30/12/2025 |
| qwen3:14b | Deprecated | 30/12/2025 |
| qwen3:4b | Deprecated | 30/12/2025 |
| qwen3:8b | Deprecated | 30/12/2025 |
| qwen3:32b | Deprecated | 30/12/2025 |
| qwq:32b | Deprecated | 30/12/2025 |
| granite3.3:2b | Deprecated | 30/12/2025 |
| granite3.3:8b | Deprecated | 30/12/2025 |
| mistral-small3.1:24b | Deprecated | 30/12/2025 |
| qwen2.5vl:32b | Deprecated | 30/12/2025 |
| qwen2.5vl:3b | Deprecated | 30/12/2025 |
| qwen2.5vl:72b | Deprecated | 30/12/2025 |
| qwen2.5vl:7b | Deprecated | 30/12/2025 |
| cogito:8b | Deprecated | 30/12/2025 |
| deepcoder:14b | Deprecated | 30/12/2025 |
| cogito:3b | Deprecated | 30/12/2025 |
| qwen3:235b | Deprecated | 22/11/2025 |
| qwen3-2507-think:30b-a3b | Deprecated | 14/11/2025 |
| gemma3:12b | Deprecated | 21/11/2025 |
| cogito:14b | Deprecated | 17/10/2025 |
| deepseek-r1:70b | Deprecated | 17/10/2025 |
| granite3.1-moe:3b | Deprecated | 17/10/2025 |
| llama3.1:8b | Deprecated | 17/10/2025 |
| phi4-reasoning:14b | Deprecated | 17/10/2025 |
| qwen2.5:0.5b | Deprecated | 17/10/2025 |
| qwen2.5:1.5b | Deprecated | 17/10/2025 |
| qwen2.5:14b | Deprecated | 17/10/2025 |
| qwen2.5:32b | Deprecated | 17/10/2025 |
| qwen2.5:3b | Deprecated | 17/10/2025 |
| deepseek-r1:671b | Deprecated | 17/10/2025 |
💡 Best Practices
To get the most out of the LLMaaS API, it is essential to adopt cost, performance, and security optimization strategies.
Cost Optimization
Cost management relies on the intelligent use of tokens and models.
-
Model Selection : Do not use an overly powerful model for a simple task. A larger model is more capable, but it is also slower and consumes significantly more energy, which directly impacts the cost. Adjust the model size to the complexity of your requirement for an optimal balance.
For example, to process one million tokens:
Gemma 3 1Bconsumes 0.15 kWh.Llama 3.3 70Bconsumes 11.75 kWh, which is 78 times more.
# For sentiment classification, a compact model is sufficient and cost-effective.if task == "sentiment_analysis":model = "qwen3.5:0.8b"# For complex legal analysis, a larger model is required.elif task == "legal_analysis":model = "gpt-oss:120b" -
Context Management : The conversation history (
messages) is returned with each call, consuming input tokens. For long conversations, consider summarization or windowing strategies to retain only relevant information.# For a long conversation, you can summarize the initial exchanges.messages = [{"role": "system", "content": "Vous êtes un assistant IA."},{"role": "user", "content": "Résumé des 10 premiers échanges..."},{"role": "assistant", "content": "Ok, j'ai le contexte."},{"role": "user", "content": "Voici ma nouvelle question."}] -
Output Token Limitation : Always use the
max_tokensparameter to avoid excessively long and costly responses. Set a reasonable limit based on your expectations.# Request a summary of up to 100 words.response = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Résume ce document..."}],max_tokens=150, # Safety margin for ~100 words)
Performance
The responsiveness of your application depends on how you handle API calls.
-
Asynchronous Requests : To process multiple requests without waiting for each to finish, use asynchronous calls. This is particularly useful for backend applications handling a high volume of concurrent requests.
import asynciofrom openai import AsyncOpenAIclient = AsyncOpenAI(api_key="...", base_url="...")async def process_prompt(prompt: str):# Process a single request asynchronouslyresponse = await client.chat.completions.create(model="gpt-oss:120b", messages=[{"role": "user", "content": prompt}])return response.choices[0].message.contentasync def batch_requests(prompts: list):# Launch multiple tasks in parallel and wait for their completiontasks = [process_prompt(p) for p in prompts]return await asyncio.gather(*tasks) -
Streaming for User Experience (UX) : For user interfaces (chatbots, assistants), streaming is essential. It allows displaying the model's response word by word, giving an impression of immediate responsiveness instead of waiting for the complete response.
# Display the response in real-time in a user interfaceresponse_stream = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Raconte-moi une histoire."}],stream=True)for chunk in response_stream:if chunk.choices[0].delta.content:# Display the text chunk in the UIprint(chunk.choices[0].delta.content, end="", flush=True)
Security
Application security is paramount, especially when handling user input.
-
Input Validation and Sanitization: Never trust user input. Before sending it to the API, sanitize it to remove any potentially malicious code or "prompt injection" instructions. Also limit their size to prevent abuse.
def sanitize_input(user_input: str) -> str:# Simple example: remove code delimiters and limit length.# More robust libraries can be used for advanced sanitization.cleaned = user_input.replace("`", "").replace("'", "").replace("\"", "")return cleaned[:2000] # Limits the size to 2000 characters -
Robust Error Handling: Always wrap your API calls in
try...exceptblocks to handle network errors, API errors (e.g., 429 Rate Limit, 500 Internal Server Error), and provide a degraded but functional user experience.from openai import APIError, APITimeoutErrortry:response = client.chat.completions.create(...)except APITimeoutError:# Handle the case where the request takes too longreturn "Le service prend plus de temps que prévu, veuillez réessayer."except APIError as e:# Handle specific API errorslogger.error(f"Erreur API LLMaaS: {e.status_code} - {e.message}")return "Désolé, une erreur est survenue avec le service d'IA."except Exception as e:# Handle all other errors (network, etc.)logger.error(f"Une erreur inattendue est survenue: {e}")return "Désolé, une erreur inattendue est survenue."