Konzepte
Unsere Managed Kubernetes-Angebote
Cloud Temple bietet zwei separate Angebote an, um Ihre Anforderungen an die Container-Orchestrierung zu erfüllen:
- Managed Core Kubernetes : Ein minimalistisches Produkt, das Ihnen eine robuste und sichere Kubernetes-Basis bietet, die auf modernsten Open-Source-Komponenten basiert. Es ist ideal für erfahrene Teams, die ihre eigene maßgeschneiderte Plattform aufbauen möchten.
- Managed Kubernetes : Eine vollständige, sofort einsatzbereite Lösung, die einen umfassenden Tool-Stack für Netzwerk, Sicherheit, Speicher, Continuous Deployment, Observability, Backup und Kostenmanagement beinhaltet.
Vergleichstabelle der Angebote
| Komponente | Managed Core Kubernetes | Managed Kubernetes |
|---|---|---|
| Betriebssystem | Talos | Talos |
| CNI | Cilium | Cilium |
| CNI-Beobachtbarkeit | ❌ | Hubble |
| Load Balancer | MetalLB | MetalLB |
| Ingress | ❌ | Ingress Nginx |
| Speicher | Rook-Ceph | Rook-Ceph |
| Kontinuierliche Bereitstellung (GitOps) | ❌ | ArgoCD |
| Beobachtbarkeit | ❌ | Prometheus, Grafana, Loki |
| Sicherung und Migration | ❌ | Veeam Kasten |
| Kostenmanagement (FinOps) | ❌ | OpenCost |
| Governance und Sicherheit | ❌ | Kyverno, Capsule |
| Container-Registry | ❌ | Harbor |
| Zertifikatsverwaltung | ❌ | Cert-Manager |
| SSO-Authentifizierung | ❌ | OIDC-Integration |
Vorstellung des Produkts Managed Kubernetes (vollständig)
Das Angebot Managed Kubernetes (auch "Kub Managé" oder "KM" genannt) ist eine von Cloud-Temple verwaltete Kubernetes-Containerisierungslösung, die als virtuelle Maschinen auf den Cloud-Temple OpenIaaS IaaS-Infrastrukturen bereitgestellt wird.
Managed Kubernetes basiert auf Talos Linux (https://www.talos.dev/), einem für Kubernetes entwickelten Betriebssystem, das leichtgewichtig und sicher ist. Es ist unveränderlich, verfügt über keine Shell und keinen SSH-Zugriff und wird ausschließlich deklarativ über die gRPC-API konfiguriert.
Die standardisierte Installation umfasst eine Reihe von Komponenten, die größtenteils Open Source sind und vom CNCF zertifiziert wurden:
-
CNI Cilium, mit Observability-Schnittstelle (Hubble): Cilium ist eine Netzwerklösung für Kubernetes-Container (Container Network Interface). Es übernimmt Sicherheit, Load Balancing, Service Mesh, Observability, Verschlüsselung usw. Es ist eine grundlegende Netzwerkkomponente, die in den meisten Kubernetes-Varianten (OpenShift, AKS, GKE, EKS usw.) zu finden ist. Wir haben die grafische Oberfläche Hubble zur Visualisierung der Cilium-Flüsse integriert.
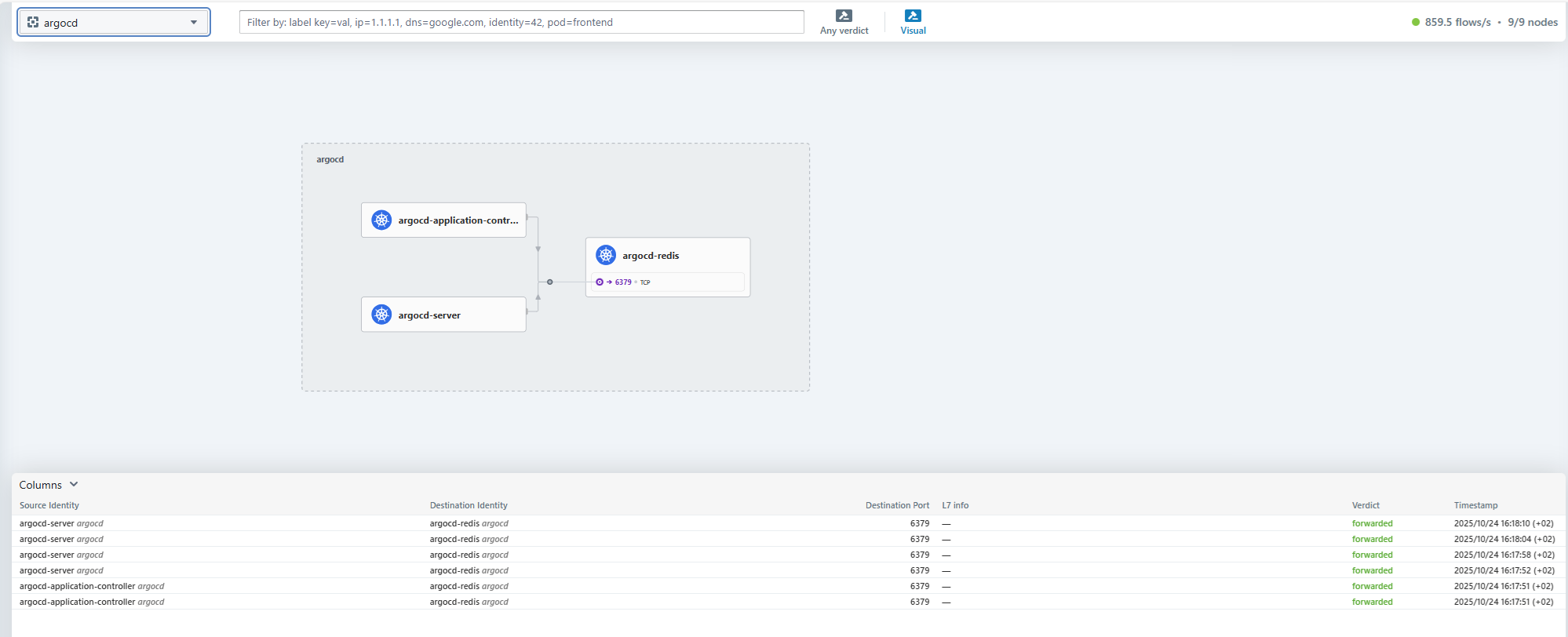
-
MetalLB und nginx: Für die Bereitstellung von Webanwendungen sind standardmäßig 3 ingress-class nginx integriert:
-
nginx-external-secured: Bereitstellung über eine öffentliche IP, die im Firewall gefiltert wird, um nur bekannte IPs zuzulassen (wird für die grafischen Oberflächen der verschiedenen Produkte und die Kubernetes-API verwendet)
-
nginx-external: Bereitstellung über eine zweite, nicht gefilterte öffentliche IP (oder kundenspezifische Filterung)
-
nginx-internal: Bereitstellung ausschließlich über eine interne IP
Für "nicht-Web"-Dienste ermöglicht ein MetalLB-Load-Balancer die Bereitstellung von Diensten intern oder über öffentliche IPs. (Dies ermöglicht den Einsatz weiterer Ingresses, wie z. B. eines WAF)
-
-
Verteiltes Rook-Ceph-Speicher: Für die Speicherung von persistenten Volumes (PV) ist ein verteiltes Open-Source-Ceph-Speichersystem in der Plattform integriert. Es ermöglicht die Nutzung der storage-classes ceph-block, ceph-bucket und ceph-filesystem. Es wird ein Speicher mit 7500 IOPS verwendet, der hohe Leistung bietet. In Produktionsbereitstellungen (über 3 AZs) sind die Speicherknoten dediziert (1 Knoten pro AZ); in Nicht-Produktionsbereitstellungen (1 AZ) wird der Speicher mit den Worker-Knoten geteilt.
-
Cert-Manager: Der Open-Source-Zertifikatsmanager Cert-Manager ist nativ in der Plattform integriert.
-
ArgoCD steht Ihnen für Ihre automatisierten Bereitstellungen über eine CI/CD-Pipeline zur Verfügung.
-
Prometheus-Stack (Prometheus, Grafana, Loki): Die Managed Kubernetes-Cluster werden standardmäßig mit einem vollständigen Open-Source-Prometheus-Stack für Observability geliefert, der Folgendes umfasst:
-
Prometheus
-
Grafana mit zahlreichen Dashboards
-
Loki: Die Plattformprotokolle werden in den Cloud-Temple S3-Speicher exportiert (und in Grafana integriert).
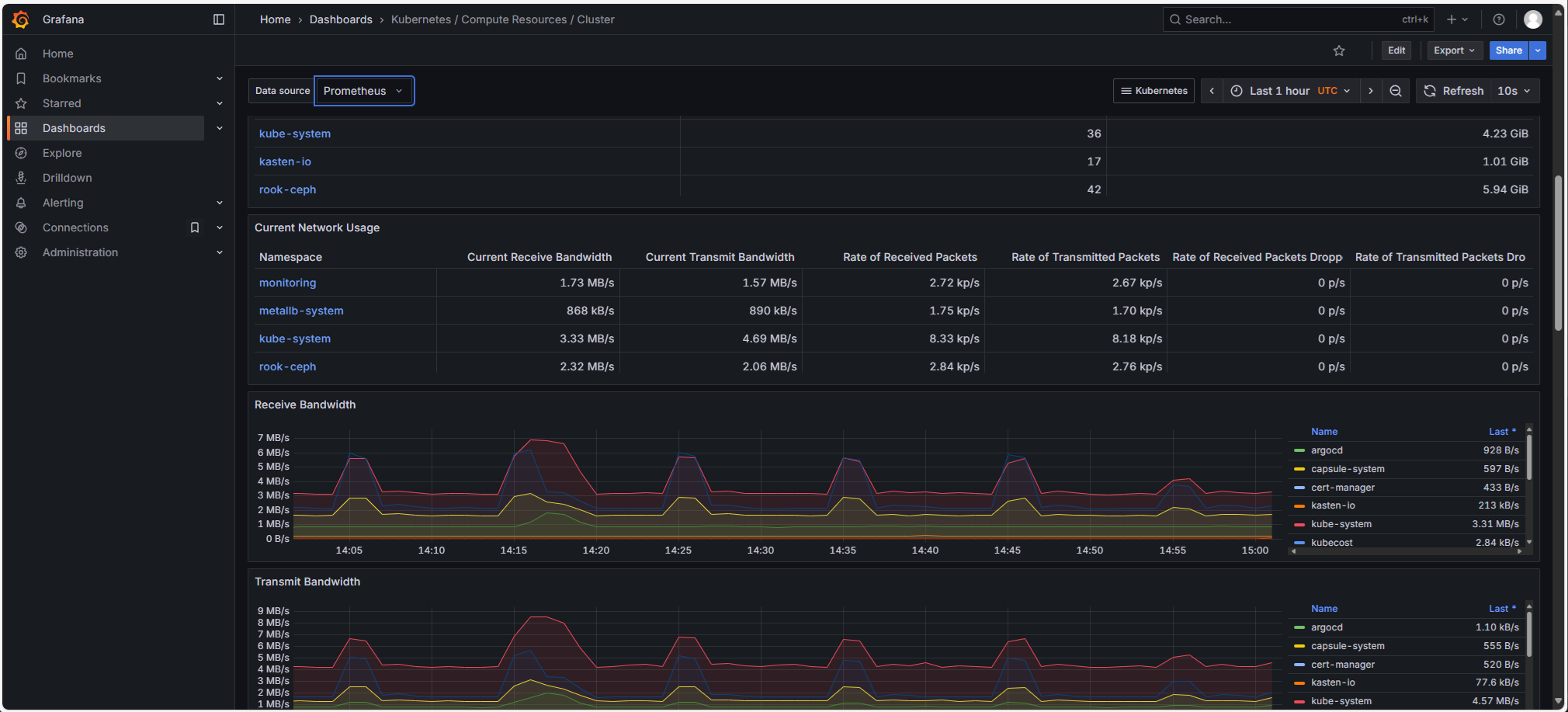
-
-
Harbor ist ein Container-Registry, mit dem Sie Ihre Container-Images oder Helm-Charts direkt im Cluster speichern können. Es führt Schwachstellen-Scans für Ihre Images durch und kann diese digital signieren. Harbor ermöglicht auch Synchronisationen mit anderen Registries. (https://goharbor.io/)
-
OpenCost (https://github.com/opencost/opencost) ist ein Kostenmanagement-Tool (FinOps) für Kubernetes. Es ermöglicht eine detaillierte Verfolgung des Kubernetes-Ressourcenverbrauchs und die Weiterabrechnung nach Projekt/Namespace.
-
Erweiterte Sicherheitsstrategien mit Kyverno und Capsule:
- Kyverno (https://kyverno.io/) ist ein Admission-Controller für Kubernetes, der das Durchsetzen von Richtlinien ermöglicht. Es ist ein essentielles Tool für Governance und Sicherheit in Kubernetes.
- Capsule (https://projectcapsule.dev/) ist ein Berechtigungsmanagement-Tool, das die Rechteverwaltung in Kubernetes erleichtert. Es führt das Konzept des Tenants ein, das die Zentralisierung und Delegation von Berechtigungen über mehrere Namespaces hinweg ermöglicht. Über Capsule sind die Berechtigungen der Nutzer der Managed Kubernetes-Plattform somit auf ihre eigenen Namespaces beschränkt.
-
Veeam Kasten (auch 'k10' genannt) ist eine Lösung zur Sicherung von Kubernetes-Workloads.
Es ermöglicht die Sicherung einer vollständigen Bereitstellung: Manifeste, Volumes usw. in den Cloud-Temple S3-Objektspeicher. Kasten nutzt Kanister, um konsistente anwendungsspezifische Sicherungen zu ermöglichen, beispielsweise für Datenbanken (https://docs.kasten.io/latest/usage/blueprints/).
Kasten ist ein plattformübergreifendes Tool, das auch mit anderen Kubernetes-Clustern (OpenShift, Hyperscaler usw.) funktioniert. Es kann daher für Reversibilitäts- oder Migrationsszenarien verwendet werden (K10 verwaltet eventuelle Anpassungen über Transformations, z. B. einen Wechsel der ingress-class), aber auch für "Refresh"-Szenarien (Beispiel: geplante Wiederherstellung einer Produktionsumgebung in der Pre-Production).
-
SSO-Authentifizierung mit einem externen OIDC-Identity-Provider (Microsoft Entra, FranceConnect, Okta, AWS IAM, Google, Salesforce, ...)
SLA & Supportinformationen
- Garantierte Verfügbarkeit (Produktion 3 AZ) : 99.95 %
- Support : N1/N2/N3 im Basisumfang enthalten (Infrastruktur und Standard-Operatoren).
- Zusicherung zur Wiederherstellungszeit (ETR) : gemäß Cloud Temple Rahmenvertrag.
- Wartung (MCO) : regelmäßiges Patching von Talos / Kubernetes / Standard-Operatoren durch MSP, ohne Dienstunterbrechung (Rolling Upgrade).
Die Reaktions- und Wiederherstellungszeiten hängen von der Schwere des Vorfalls ab, entsprechend der Supportmatrix (P1 bis P4).
Versionsrichtlinie & Lebenszyklus
- Unterstütztes Kubernetes : N-2 (3 Major-Releases pro Jahr, etwa alle 4 Monate). Jedes Release wird offiziell 12 Monate unterstützt, was ein Cloud Temple Supportfenster von maximal ~16 Monaten pro Version gewährleistet.
- Talos OS : an die stabilen Kubernetes-Versionen angepasst.
- Jeder Zweig wird etwa 12 Monate gewartet (einschließlich Sicherheitspatches).
- Empfohlener Upgrade-Rhythmus : 3-mal jährlich, im Einklang mit den Kubernetes-Upgrades.
- Kritische Patches (CVE, Kernel) werden als Rolling Upgrade angewendet, ohne Dienstunterbrechung.
- Standard-Operatoren : innerhalb von 90 Tagen nach dem stabilen Release aktualisiert.
- Updates :
- Major (Kubernetes N+1, Talos X+1) : 3-mal jährlich geplant, als Rolling Update.
- Minor : automatisch innerhalb von 30 bis 60 Tagen angewendet.
- Deprecation : Version N-3 → Supportende innerhalb von 90 Tagen nach Veröffentlichung von N.
Kubernetes-Knoten
Produktion (Multi-Zonen)
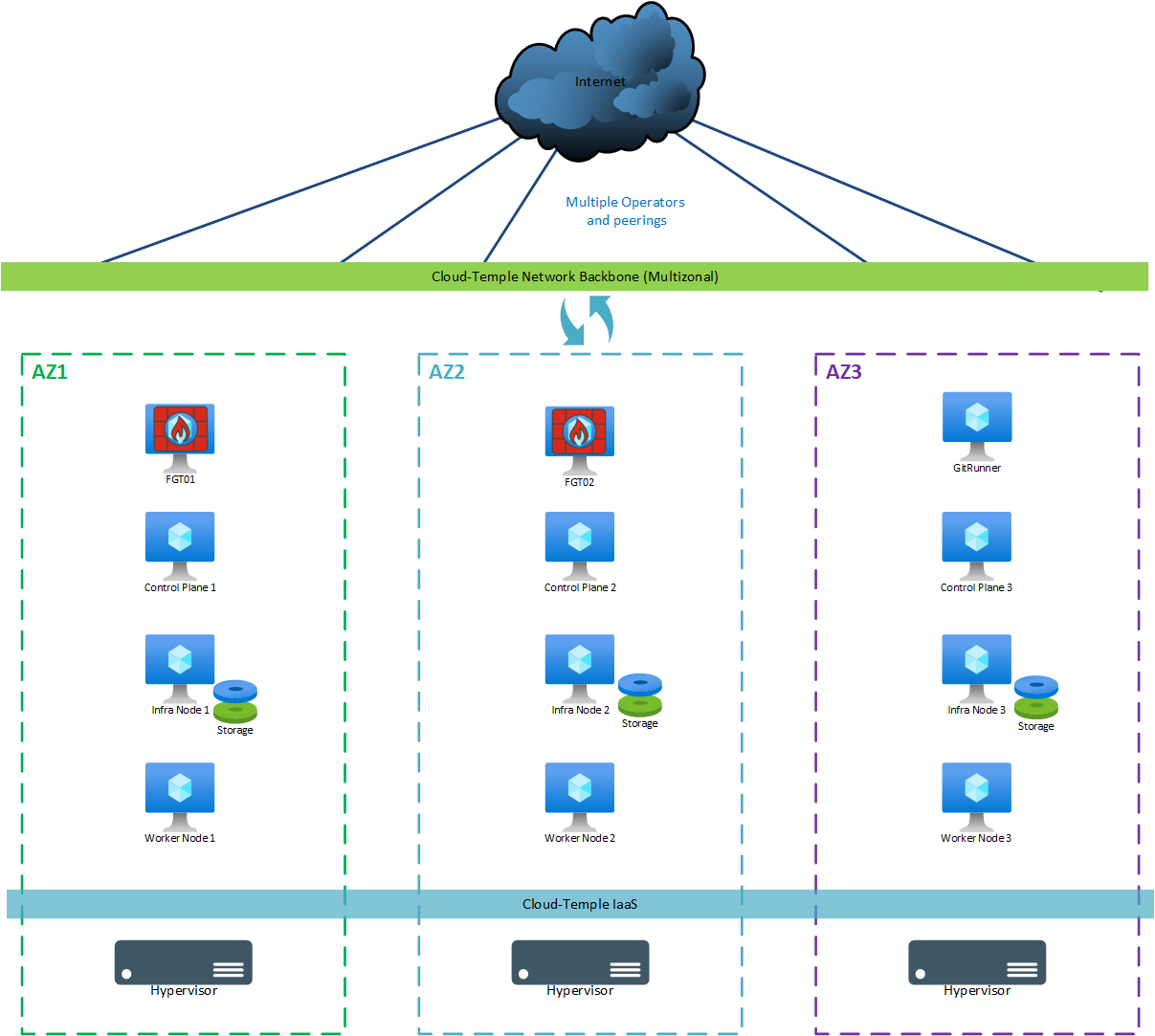
Für eine "Produktions"-Bereitstellung (Multi-Zonen) werden folgende Maschinen verwendet:
| AZ | Maschine | vCores | RAM | Lokaler Speicher |
|---|---|---|---|---|
| AZ07 | Git Runner | 4 | 8 GB | OS: 256 GB |
| AZ05 | Control Plane 1 | 8 | 12 GB | OS: 128 GB |
| AZ06 | Control Plane 2 | 8 | 12 GB | OS: 128 GB |
| AZ07 | Control Plane 3 | 8 | 12 GB | OS: 128 GB |
| AZ05 | Storage Node 1 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB Minimum (*) |
| AZ06 | Storage Node 2 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB Minimum (*) |
| AZ07 | Storage Node 3 | 12 | 24 GB | OS: 128 GB + Ceph 500 GB Minimum (*) |
| AZ05 | Worker Node 1 (**) | 12 | 24 GB | OS: 128 GB |
| AZ06 | Worker Node 2 (**) | 12 | 24 GB | OS: 128 GB |
| AZ07 | Worker Node 3 (**) | 12 | 24 GB | OS: 128 GB |
(*) : Jeder Storage Node wird mit mindestens 500 GB Festplattenspeicher geliefert, was einem nutzbaren, verteilten Ceph-Speicher von 500 GB entspricht (die Daten werden auf jede AZ repliziert, also x3). Der für den Kunden verfügbare freie Speicher beträgt etwa 350 GB. Diese anfängliche Größe kann bei der Bereitstellung oder später je nach Bedarf erhöht werden. Auf Ceph werden Quotas angewendet, mit einer Block-/Datei-Aufteilung.
(**) : Größe und Anzahl der Worker Nodes können je nach Rechenkapazitätsbedarf des Kunden angepasst werden. Die Mindestanzahl an Worker Nodes beträgt 3 (1 pro AZ), und wir empfehlen, ihre Anzahl in Schritten von 3 zu erhöhen, um eine konsistente Multi-Zonen-Verteilung beizubehalten. Die Größe der Worker Nodes kann angepasst werden, mit einem Minimum von 12 Kernen und 24 GB RAM; die Obergrenze pro Worker Node wird durch die Größe der verwendeten Hypervisoren festgelegt (potenziell also 112 Kerne/1536 GB RAM mit Performance 3 Blades). Die Anzahl der Worker Nodes ist auf 100 begrenzt. Das CNCF empfiehlt, Worker Nodes gleicher Größe zu verwenden. Die Begrenzung der Pods pro Worker Node liegt bei 110.
Dev/Test
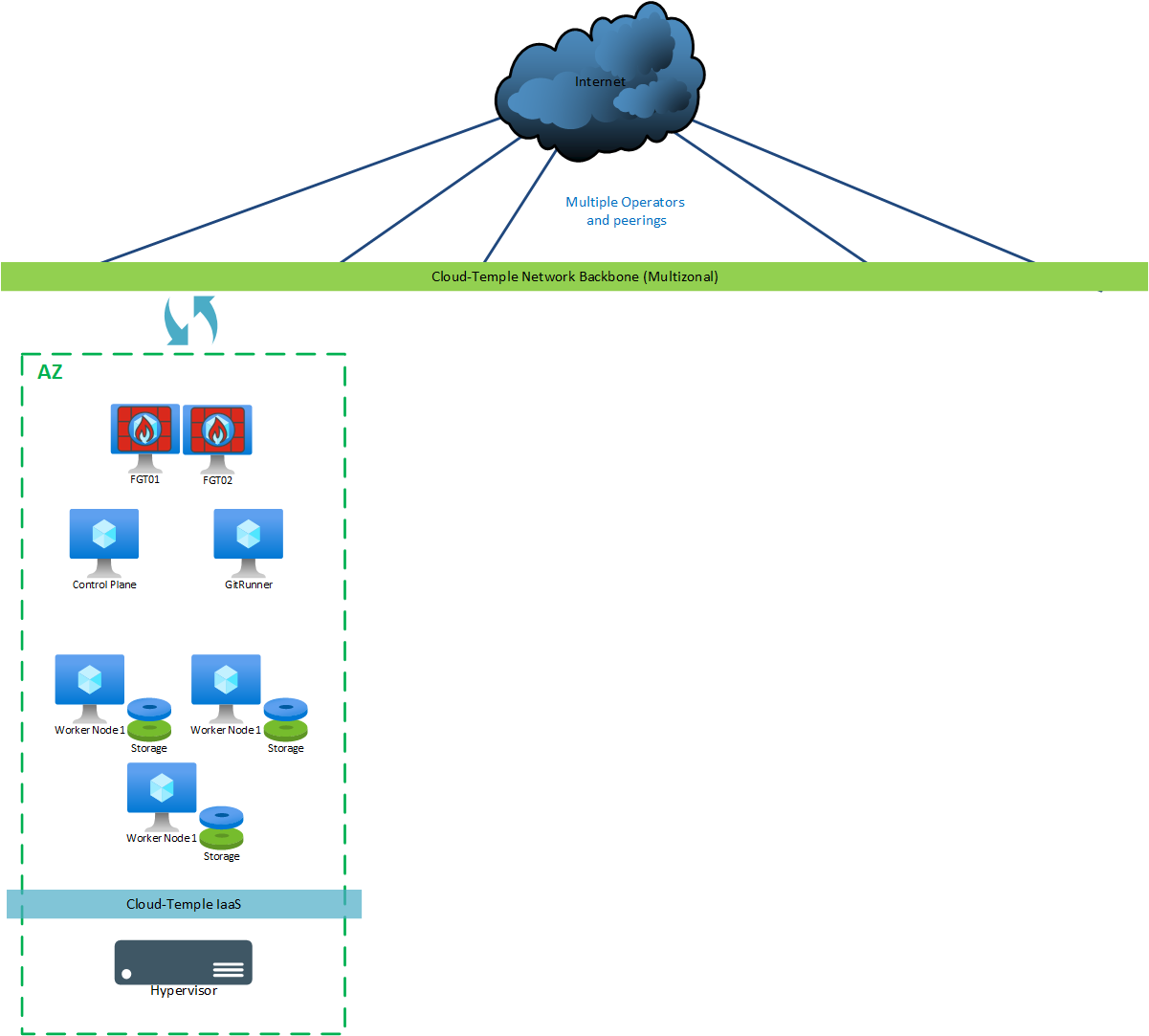
Für eine "Dev/Test"-Version werden folgende Maschinen bereitgestellt:
| AZ | Maschine | vCores | RAM | Lokaler Speicher |
|---|---|---|---|---|
| AZ0n | Git Runner | 4 | 8 GB | OS: 30 GB |
| AZ0n | Control Plane | 8 | 12 GB | OS: 128 GB |
| AZ0n | Worker Node 1 (**) | 12 | 24 GB | OS: 128 GB + Ceph mindestens 300 GB (*) |
| AZ0n | Worker Node 2 (**) | 12 | 24 GB | OS: 128 GB + Ceph mindestens 300 GB (*) |
| AZ0n | Worker Node 3 (**) | 12 | 24 GB | OS: 128 GB + Ceph mindestens 300 GB (*) |
(*) : 3 Worker Nodes werden als Storage Nodes verwendet und werden mit mindestens 300 GB Festplattenspeicher geliefert, was einer nutzbaren verteilten Speicherkapazität von 300 GB entspricht (die Daten werden dreifach repliziert). Der für den Kunden verfügbare freie Speicher beträgt etwa 150 GB. Diese anfängliche Größe kann bei der Provisionierung oder später je nach Bedarf erhöht werden.
(**) : Größe und Anzahl der Worker Nodes können an den Rechenleistungsbedarf des Kunden angepasst werden. Die Mindestanzahl an Worker Nodes beträgt 3 (aufgrund der Speicherreplikation). Die Größe der Worker Nodes kann angepasst werden, mit einem Minimum von 12 Kernen und 24 GB RAM; die Obergrenze pro Worker Node wird durch die Größe der verwendeten Hypervisoren festgelegt (potenziell also 112 Kerne/1536 GB RAM mit Performance-3-Blades). Die Anzahl der Worker Nodes ist auf 250 begrenzt. Der CNCF empfiehlt, Worker Nodes gleicher Größe zu verwenden. Die maximale Anzahl von Pods pro Worker Node beträgt 110.
RACI
Architektur & Infrastruktur
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Globale Architektur des Kubernetes-Services definieren | C | RA |
| Kubernetes-Service dimensionieren (Anzahl der Knoten, Ressourcen) | C | RA |
| Kubernetes-Service mit Standardkonfiguration installieren | I | RA |
| Konfiguration des Kubernetes-Services | C | RA |
| Basisnetzwerk des Kubernetes-Services konfigurieren | I | RA |
| Bereitstellung der initialen Identitäts- und Zugriffskonfiguration | C | RA |
| Skalierungs- und Hochverfügbarkeitsstrategie definieren | C | RA |
Projekt- und Geschäftsanwendungsmanagement
| Tätigkeit | Kunde | Cloud Temple |
|---|---|---|
| Erstellen und Verwalten von Kubernetes-Projekten | RA | I* |
| Bereitstellen und Verwalten von Anwendungen in Kubernetes | RA | I* |
| Konfigurieren von CI/CD-Pipelines | RA | I* |
| Verwalten von Container-Images und Registries | RA | I* |
*kann je nach Managed-Service-Vertrag auf "C" wechseln
Überwachung und Leistung
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Überwachung der Leistung des Kubernetes-Dienstes | I | RA* |
| Überwachung der Anwendungsleistung | RA | |
| Verwaltung der Alarme für den Kubernetes-Dienst | I | RA* |
| Verwaltung der Alarme für die Anwendungen | RA |
(*) : Nur für Produktionscluster. In Dev/Test ist der Kunde vollständig autonom und verantwortlich.
Wartung und Updates der Infrastrukturen
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Kubernetes/OS-Dienst aktualisieren | C | RA |
| Sicherheitspatches für Kubernetes anwenden | C | RA |
| Bereitgestellte Anwendungen aktualisieren (Operatoren*) | C | RA |
*Operator-Paket in Managed Kube enthalten – siehe Kapitel: Verwaltete Helm-Pakete
Sicherheit
| Aufgabe | Kunde | Cloud Temple |
|---|---|---|
| Sicherheit des Kubernetes-Dienstes verwalten | RA | RA* |
| Sicherheitsrichtlinien für Pods konfigurieren und verwalten | RA | I |
| SSL/TLS-Zertifikate für den Kubernetes-Dienst verwalten | C | RA* |
| SSL/TLS-Zertifikate für die Anwendungen verwalten | RA | I |
| Rollenbasierte Zugriffskontrolle (RBAC) implementieren und verwalten | C | R* |
| Rollenbasierte Zugriffskontrolle für Clients (RBAC) implementieren und verwalten | RA | I |
(*) : Nur für Produktionscluster. In Dev/Test ist der Kunde vollständig autonom und trägt die volle Verantwortung.
Sicherung und Disaster Recovery
| Aufgabe | Kunde | Cloud Temple |
|---|---|---|
| Strategie für die Sicherung des Kubernetes-Dienstes definieren | I | RA |
| Sicherungen des Kubernetes-Dienstes implementieren und verwalten | I | RA |
| Strategie für die Sicherung der Anwendungen definieren | RA* | I* |
| Sicherungen der Anwendungen implementieren und verwalten | RA* | I* |
| Disaster-Recovery-Verfahren für den Kubernetes-Dienst testen | CI | RA |
| Disaster-Recovery-Verfahren für die Anwendungen testen | RA* | CI* |
*kann je nach Managed-Service-Vertrag auf "CI | RA" geändert werden
Support und Fehlerbehebung
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Bereitstellung von Level-1-Support für die Infrastruktur | I | RA |
| Bereitstellung von Level-2- und Level-3-Support für die Infrastruktur | I | RA |
| Behebung von Problemen im Zusammenhang mit dem Kubernetes-Dienst | C | RA |
| Behebung von Problemen im Zusammenhang mit Anwendungen | RA | I |
Kapazitätsmanagement und Weiterentwicklung
Nur Produktionscluster. In Dev/Test ist der Kunde vollständig autonom und trägt die volle Verantwortung.
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Überwachung der Kubernetes-Ressourcennutzung | C | RA |
| Planung der Kapazitätsentwicklung des Dienstes | RA | C |
| Implementierung von Kapazitätsänderungen | I | RA |
| Verwaltung der Weiterentwicklung von Anwendungen und deren Ressourcen | RA | I |
Dokumentation und Compliance
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Dokumentation des Kubernetes-Produkts pflegen | I | RA |
| Dokumentation der Anwendungen pflegen | RA | I |
| Compliance des Kubernetes-Dienstes gewährleisten | I | RA |
| Compliance der Anwendungen gewährleisten | RA | I |
| Audits des Kubernetes-Dienstes durchführen | I | RA |
| Audits der Anwendungen durchführen | RA | I |
Verwaltung von Kubernetes-Operatoren/CRDs (im Produkt enthalten)
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Bereitstellung des Standard-Operator-Katalogs | CI | RA |
| Aktualisierung der Operatoren | CI | RA |
| Überwachung des Operator-Status | CI | RA |
| Behebung von Operator-bezogenen Problemen | CI | RA |
| Verwaltung der Operator-Berechtigungen | CI | RA |
| Verwaltung der Operator-Ressourcen (Hinzufügen/Entfernen) | CI | RA |
| Sicherung der Operator-Ressourcendaten | CI | RA |
| Überwachung der Operator-Ressourcen | CI | RA |
| Wiederherstellung der Operator-Ressourcendaten | CI | RA |
| Sicherheitsaudit der Operatoren | CI | RA |
| Support der Operatoren | CI | RA |
| Verwaltung der Operator-Lizenzen | CI | RA |
| Verwaltung spezifischer Supportpläne für Operatoren | CI | RA |
*Operator-Paket enthalten in Managed Kube - siehe Kapitel: Verwaltete Helm-Pakete
Verwaltung von Anwendungen/Operatoren/Kubernetes-CRDs (des Kunden)
Nur für Produktionscluster. In Dev/Test ist der Kunde vollständig autonom und trägt die volle Verantwortung.
| Tätigkeit | Kunde | Cloud Temple |
|---|---|---|
| Bereitstellung der CRDs | I* | RA* |
| Aktualisierung der Operatoren | RA | I |
| Überwachung des Operator-Status | RA | I |
| Fehlerbehebung bei Operatoren | RA | I |
| Verwaltung der Operator-Berechtigungen | RA | I |
| Verwaltung der Operator-Ressourcen (Hinzufügen/Entfernen) | RA | I |
| Sicherung der Operator-Ressourcendaten | RA | I |
| Überwachung der Operator-Ressourcen | RA | I |
| Wiederherstellung der Operator-Ressourcendaten | RA | I |
| Sicherheitsaudit der Operatoren | RA | I |
| Operator-Support | RA | I |
| Lizenzverwaltung für Operatoren | RA | I |
| Verwaltung spezifischer Supportpläne für Operatoren | RA | I |
Bestimmte Operator-Dienstleistungen können je nach Managed-Services-Vertrag übernommen werden.
*kann je nach Managed-Services-Vertrag zu "A | RC" wechseln
Anwendungssupport
| Aktivität | Kunde | Cloud Temple |
|---|---|---|
| Anwendungssupport (externe Leistung) | RA | I |
Ein Anwendungssupport kann über eine Zusatzleistung bereitgestellt werden.
RACI (zusammenfassend)
- Cloud Temple: Verantwortlich und ausführend (RA) für die Kubernetes-Basis, Clustersicherheit, Infrastruktursicherung, Monitoring, CRD.
- Kunde: Verantwortlich und ausführend (RA) für die Anwendungsprojekte, Business-Operatoren, CI/CD-Pipelines, Anwendungssicherungen.
- Grauzone: Anpassungen und Erweiterungen (IAM, spezifische Operatoren, Compliance- und Sicherheits-Härtung des Clusters) – projektbasiert abgerechnet.