Tutorials LLMaaS
Overview
These advanced tutorials cover integration, optimization, and best practices for fully leveraging LLMaaS Cloud Temple in production. Each tutorial includes tested code and real performance metrics.
🚀 LangChain Integrations and Frameworks
1. Basic Integration with LangChain
This first example demonstrates how to integrate our LLMaaS API with the popular framework LangChain by creating a custom "wrapper." A wrapper is a class that "wraps" our API to make it compatible with LangChain's internal mechanisms.
Der Code erklärt
Der folgende Code definiert eine Klasse CloudTempleLLM, die von der Basisklasse LLM von LangChain erbt. Dadurch können wir ein maßgeschneidertes Verhalten definieren, während wir gleichzeitig mit dem LangChain-Ökosystem (Chains, Agents usw.) kompatibel bleiben.
CloudTempleLLM(LLM): Unsere Klasse erbt vonLLM, was uns verpflichtet, bestimmte Methoden zu implementieren, insbesondere_call._call(self, prompt: str, ...): Dies ist das Herzstück unseres Wrappers. Jedes Mal, wenn LangChain unseren Sprachmodell aufrufen muss, ruft es diese Methode auf. Innerhalb dieser Methode formatieren wir eine standardmäßige HTTP-POST-Anfrage mit den richtigen Headern (Authorization) und dem erwartetenpayloadfür unsere API/v1/chat/completions.beispiel_langchain_basic(): Diese Demonstrationsfunktion zeigt, wie man unseren Wrapper verwendet. Wir instanziieren ihn, erstellen einPromptTemplate, um unsere Anfrage zu strukturieren, und kombinieren beides in einerLLMChain. Wenn wir die Kette ausführen (chain.run(...)), LangChain im Hintergrund die von uns definierte Methode_callaufruft.
Diese Vorgehensweise ist nützlich, wenn Sie vollständige Kontrolle über die Interaktion von LangChain mit der API haben möchten, ist aber aufwändiger als die Verwendung des Clients ChatOpenAI (siehe API-Referenz).
# Installation der Abhängigkeiten
# pip install langchain requests pydantic
from langchain.llms.base import LLM
from langchain.schema import LLMResult, Generation
from typing import Optional, List, Any
from pydantic import Field
import requests
import json
import os
# --- Konfiguration ---
# It is recommended to store your API key in an environment variable
API_KEY = os.getenv("LLMAAS_API_KEY", "your-api-key-here")
BASE_URL = "https://api.ai.cloud-temple.com/v1"
class CloudTempleLLM(LLM):
"""
Custom LangChain wrapper for the Cloud Temple LLMaaS API.
This class enables using our API as a standard LLM within LangChain.
"""
api_key: str = Field(default="")
model_name: str = Field(default="granite3.3:8b")
temperature: float = Field(default=0.7)
max_tokens: int = Field(default=1000)
@property
def _llm_type(self) -> str:
"""Unique identifier for our LLM type."""
return "cloud_temple_llmaas"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
"""
Main method that makes the call to the LLMaaS API.
LangChain uses this method for each request to the model.
"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": self.model_name,
"messages": [{"role": "user", "content": prompt}],
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
if stop:
payload["stop"] = stop
# Execute POST request to the API
response = requests.post(
f"{BASE_URL}/chat/completions",
headers=headers,
json=payload,
timeout=60
)
response.raise_for_status() # Raises an exception on HTTP error
result = response.json()
# Returns the content of the assistant's message
return result['choices'][0]['message']['content']
# --- Beispiel zur Verwendung ---
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
def beispiel_langchain_wrapper():
"""Zeigt die Verwendung des LLM-Wrappers mit einer LangChain-Kette."""
# 1. Initialisierung unseres benutzerdefinierten LLMs
llm = CloudTempleLLM(
api_key=API_KEY,
model_name="granite3.3:8b"
)
# 2. Erstellung eines Prompt-Vorlage zum Strukturieren der Anfragen
template = """
Sie sind ein Experte im Bereich {domaine}.
Beantworten Sie die folgende Frage detailliert und professionell:
Frage: {question}
Antwort:
"""
prompt = PromptTemplate(
input_variables=["domaine", "question"],
template=template
)
# 3. Erstellung einer Kette, die den Prompt und das LLM kombiniert
chain = LLMChain(llm=llm, prompt=prompt)
# 4. Ausführung der Kette mit spezifischen Variablen
result = chain.run(
domaine="Cybersicherheit",
question="Welche sind die besten Praktiken zur Sicherung einer REST-API?"
)
return result
# --- Start the test ---
if __name__ == "__main__":
if API_KEY == "your-api-key-here":
print("Please set your LLMAAS_API_KEY in your environment variables.")
else:
response = example_langchain_wrapper()
print("Response from the cybersecurity expert:\n")
print(response)
2. RAG (Retrieval-Augmented Generation) with the LLMaaS API
RAG is a powerful technique that enables a large language model (LLM) to answer questions by leveraging an external knowledge base. This tutorial guides you through building a simple RAG pipeline using our API for embeddings and generation, and FAISS, a vector similarity library, to create an in-memory index.
Der Code erklärt
Der Pipeline besteht aus mehreren logischen Schritten:
- Konfiguration: Wir importieren die erforderlichen Bibliotheken und laden unsere API-Schlüssel aus den Umgebungsvariablen. Wir definieren die zu verwendenden Modelle:
granite-embedding:278mfür die Vektorisierung undgranite3.3:8bfür die Antwortgenerierung. LLMaaSEmbeddings: Wie im vorherigen Beispiel benötigen wir einen Wrapper, um mit unserer Embeddings-API zu interagieren. Diese Klasse ist dafür verantwortlich, Textstücke (chunks) in numerische Vektoren (Embeddings) zu transformieren.setup_rag_pipeline: Diese Funktion orchestriert die Erstellung der Pipeline.- Dokumentenladen:
DirectoryLoaderlädt die Textdateien unserer Wissensbasis. - Aufteilung in Chunks:
RecursiveCharacterTextSplitterteilt die Dokumente in kleinere Stücke auf. Dies ist entscheidend hat, damit das Embedding-Modell den Text effizient verarbeiten kann und die Ähnlichkeitssuche präzise ist. - Vektorisierung und Indizierung:
FAISS.from_documentsist ein entscheidender Schritt. Er nimmt die Textchunks, verwendet unsere KlasseLLMaaSEmbeddings, um die entsprechenden Vektoren über die API abzurufen, und speichert diese Vektoren im FAISS-Index im Speicher. - Konfiguration des LLM: Wir verwenden
ChatOpenAI, das nativ mit unserer API für die Antwortgenerierung kompatibel ist. - Erstellung der Chain
RetrievalQA: Dies ist die LangChain-Chain, die alle Komponenten verbindet. Wenn wir ihr eine Frage stellen, führt sie folgende Schritte aus: a. Nutzt denretriever(basierend auf unserem FAISS-Index), um die relevantesten Textchunks zu finden. b. „Füllt“ (stuff) diese Chunks zusammen mit der Frage in einen Prompt. c. Sendet diesen erweiterten Prompt an das LLM, um eine kontextbasierte Antwort zu generieren.
- Dokumentenladen:
- Ausführung: Die Funktion
mainsimuliert eine reale Nutzung, indem sie temporäre Wissensdateien erstellt, die Pipeline aufbaut und eine Frage stellt.
import os
import tempfile
import shutil
from pathlib import Path
from dotenv import load_dotenv
from typing import List
# --- Imports LangChain ---
from langchain_core.embeddings import Embeddings
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
# --- Konfiguration ---
# Lädt Umgebungsvariablen (z. B. LLMAAS_API_KEY)
load_dotenv()
API_KEY = os.getenv("LLMAAS_API_KEY")
BASE_URL = os.getenv("API_URL", "https://api.ai.cloud-temple.com/v1")
EMBEDDING_MODEL = "granite-embedding:278m"
LLM_MODEL = "granite3.3:8b"
# --- Custom Embedding Class ---
class LLMaaSEmbeddings(Embeddings):
"""Custom embedding class for the Cloud Temple LLMaaS API."""
def __init__(self, api_key: str, model_name: str):
if not api_key:
raise ValueError("The LLMaaS API key cannot be empty.")
self.api_key = api_key
self.model_name = model_name
self.base_url = BASE_URL
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
def _embed(self, texts: List[str]) -> List[List[float]]:
import httpx
payload = {"input": texts, "model": self.model_name}
try:
with httpx.Client(timeout=60.0) as client:
response = client.post(f"{self.base_url}/embeddings", headers=self.headers, json=payload)
response.raise_for_status()
data = response.json()['data']
data.sort(key=lambda e: e['index'])
return [item['embedding'] for item in data]
except httpx.HTTPStatusError as e:
print(f"HTTP error during embedding generation: {e.response.text}")
raise
except Exception as e:
print(f"An unexpected error occurred during embedding generation: {e}")
raise
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return self._embed(texts)
def embed_query(self, text: str) -> List[float]:
# The _embed method expects a list, so we wrap the single text.
return self._embed([text])[0]
# --- RAG-Pipeline ---
def setup_rag_pipeline(documents_path: str):
"""Vollständige Konfiguration der RAG-Pipeline mit LLMaaS-Tools."""
print("1. Laden und Aufteilung der Dokumente...")
loader = DirectoryLoader(documents_path, glob="*.txt", loader_cls=TextLoader, loader_kwargs={'encoding': 'utf-8'})
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(documents)
print(f" -> {len(documents)} Dokument(e) geladen und in {len(splits)} Chunks aufgeteilt.")
print(f"2. Erstellung von Embeddings über LLMaaS (Modell: {EMBEDDING_MODEL})...")
embeddings = LLMaaSEmbeddings(api_key=API_KEY, model_name=EMBEDDING_MODEL)
print("3. Erstellung des vektorbasierten Index im Speicher (FAISS)...")
vectorstore = FAISS.from_documents(splits, embeddings)
print(" -> FAISS-Index erfolgreich erstellt.")
print(f"4. Konfiguration des LLM (Modell: {LLM_MODEL})...")
# Korrektur für Kompatibilität mit Pydantic/LangChain
from langchain_core.caches import BaseCache
from langchain_core.callbacks.base import Callbacks
ChatOpenAI.model_rebuild()
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=LLM_MODEL,
temperature=0.3,
model_kwargs={"max_tokens": 300}
)
print("5. Erstellung der Frage-Antwort-Kette (RAG)...")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
print(" -> RAG-Pipeline ist bereit.")
return qa_chain
# --- Execution ---
def main():
"""Hauptfunktion zum Ausführen des vollständigen RAG-Pipelines."""
if not API_KEY:
print("Fehler: Die Umgebungsvariable LLMAAS_API_KEY ist nicht definiert.")
return
# Erstellen temporärer Testdokumente
temp_dir = tempfile.mkdtemp()
print(f"\nErstellung von Testdokumenten in: {temp_dir}")
try:
documents_content = {
"overview.txt": "Cloud Temple ist ein französischer Anbieter von souveränem Cloud-Computing mit der Zertifizierung SecNumCloud.",
"pricing.txt": "Die Preise für die LLMaaS-API betragen 1,90 € pro Million Eingabetokens und 8 € pro Million Ausgabetokens."
}
for filename, content in documents_content.items():
with open(Path(temp_dir) / filename, 'w', encoding='utf-8') as f:
f.write(content)
# Pipeline konfigurieren und ausführen
rag_chain = setup_rag_pipeline(temp_dir)
print("\n--- Abfrage der RAG-Pipeline ---")
question = "Was sind die Preise für Ausgabetokens der LLMaaS-API von Cloud Temple?"
result = rag_chain({"query": question})
print(f"\nFrage: {question}")
print(f"Antwort: {result['result']}")
print("\nVerwendete Quellen für die Antwort:")
for source in result["source_documents"]:
print(f"- Datei: {os.path.basename(source.metadata['source'])}")
print(f" Inhalt: \"{source.page_content}\"")
finally:
# Temporäres Verzeichnis bereinigen
print(f"\nBereinigung des temporären Verzeichnisses: {temp_dir}")
shutil.rmtree(temp_dir)
if __name__ == "__main__":
main()
3. Integration mit einer vektorbasierten Datenbank (Qdrant)
Für RAG-Anwendungen in der Produktion wird die Verwendung einer spezialisierten vektorbasierten Datenbank wie Qdrant empfohlen. Im Gegensatz zu FAISS, das im Arbeitsspeicher arbeitet, bietet Qdrant Datenpersistenz, erweiterte Suchfunktionen und eine bessere Skalierbarkeit.
Code erläutert
Dieses Tutorial passt den vorherigen RAG-Pipeline-Ansatz an, um Qdrant zu verwenden.
- Voraussetzungen: Der erste Schritt besteht darin, eine Qdrant-Instanz zu starten. Der einfachste Weg hierfür ist die Verwendung von Docker.
setup_qdrant_rag_pipeline:- Embeddings und Dokumente: Die Erstellung von Embeddings und Dokumenten bleibt identisch mit dem vorherigen Beispiel.
- Verbindung zu Qdrant: Anstelle eines FAISS-Indexes verwenden wir
Qdrant.from_documents. Diese Methode von LangChain verarbeitet mehrere Schritte: a. Sie verbindet sich mit Ihrer Qdrant-Instanz über die bereitgestellte URL. b. Sie erstellt eine neue "Collection" (das Äquivalent einer Tabelle in einer SQL-Datenbank), falls sie noch nicht existiert. c. Sie ruft unsere KlasseLLMaaSEmbeddingsauf, um die Dokumente zu vektorisieren. d. Sie fügt die Dokumente und ihre Vektoren in die Qdrant-Collection ein. force_recreate=True: Für dieses Tutorial verwenden wir diesen Parameter, um sicherzustellen, dass die Collection bei jeder Ausführung leer ist. In der Produktion setzen Sie ihn aufFalse, um Ihre Daten beizubehalten.
- Der Rest des Pipelines (Konfiguration des LLM, Erstellung der Kette
RetrievalQA) bleibt unverändert, was die Flexibilität von LangChain verdeutlicht: Es genügt, die Quelle desretriever(Informationsrecherche-Modul) zu wechseln, um von FAISS auf Qdrant zu wechseln.
Für dieses Tutorial benötigen Sie eine Qdrant-Instanz. Sie können sie einfach mit Docker starten:
# 1. Download the latest Qdrant image
docker pull qdrant/qdrant
# 2. Start the Qdrant container
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
The code below shows how to adapt the RAG pipeline to use Qdrant as the vector database.
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Qdrant
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from typing import List
from langchain_core.embeddings import Embeddings
# (The LLMaaSEmbeddings class is the same as in the previous example,
# We reuse it here. Make sure it is defined in your script.)
# --- Konfiguration ---
load_dotenv()
API_KEY = os.getenv("LLMAAS_API_KEY")
BASE_URL = os.getenv("API_URL", "https://api.ai.cloud-temple.com/v1")
EMBEDDING_MODEL = "granite-embedding:278m"
LLM_MODEL = "granite3.3:8b"
QDRANT_URL = os.getenv("QDRANT_URL", "http://localhost:6333")
QDRANT_COLLECTION_NAME = "tutorial_collection"
# --- Embedding Class (reused from previous example) ---
class LLMaaSEmbeddings(Embeddings):
def __init__(self, api_key: str, model_name: str):
if not api_key: raise ValueError("API Key is required.")
self.api_key, self.model_name, self.base_url = api_key, model_name, BASE_URL
self.headers = {"Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json"}
def _embed(self, texts: List[str]) -> List[List[float]]:
import httpx
payload = {"input": texts, "model": self.model_name}
with httpx.Client(timeout=60.0) as client:
r = client.post(f"{self.base_url}/embeddings", headers=self.headers, json=payload)
r.raise_for_status()
data = r.json()['data']
data.sort(key=lambda e: e['index'])
return [item['embedding'] for item in data]
def embed_documents(self, texts: List[str]) -> List[List[float]]: return self._embed(texts)
def embed_query(self, text: str) -> List[float]: return self._embed([text])[0]
def setup_qdrant_rag_pipeline():
"""Configure and return a RAG pipeline using Qdrant."""
print("1. Initializing LLMaaS embedding client...")
embeddings = LLMaaSEmbeddings(api_key=API_KEY, model_name=EMBEDDING_MODEL)
print("2. Preparing documents...")
documents_content = [
"Cloud Temple is a French sovereign cloud provider with SecNumCloud certification.",
"LLMaaS pricing is 1.9€ for input and 8€ for output per million tokens."
]
documents = [Document(page_content=d) for d in documents_content]
print(f"3. Connecting to Qdrant and populating collection '{QDRANT_COLLECTION_NAME}'...")
vectorstore = Qdrant.from_documents(
documents,
embeddings,
url=QDRANT_URL,
collection_name=QDRANT_COLLECTION_NAME,
force_recreate=True, # Ensures a clean collection for the tutorial
)
print(" -> Collection created and populated successfully.")
print(f"4. Configuring LLM ({LLM_MODEL})...")
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=LLM_MODEL,
temperature=0.3
)
print("5. Creating RAG chain...")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
print(" -> Qdrant-based RAG pipeline ready.")
return qa_chain
# --- Execution ---
def main_qdrant():
"""Hauptfunktion zum Ausführen des RAG-Pipelines mit Qdrant."""
if not API_KEY:
print("Fehler: Die Umgebungsvariable LLMAAS_API_KEY ist nicht definiert.")
return
try:
rag_chain = setup_qdrant_rag_pipeline()
question = "Was sind die Preise der LLMaaS-API von Cloud Temple?"
print(f"\n--- Abfrage der Pipeline ---")
result = rag_chain({"query": question})
print(f"\nFrage: {question}")
print(f"Antwort: {result['result']}")
print("\nVerwendete Quellen für die Antwort:")
for source in result["source_documents"]:
print(f"- Inhalt: \"{source.page_content}\"")
except Exception as e:
print(f"\nEin Fehler ist aufgetreten: {e}")
print("Bitte stellen Sie sicher, dass der Qdrant-Container korrekt ausgeführt wird.")
if __name__ == "__main__":
main_qdrant()
4. LangChain Agents with Tools
An agent is an LLM that does more than simply answer a question—it can use a set of tools (functions, APIs, etc.) to build a more complex response. It can reason, break down a problem, select an appropriate tool, execute it, observe the result, and repeat this cycle until it arrives at a final answer.
Der Code erklärt
Dieses Beispiel erstellt einen einfachen Agenten, der zwei Tools verwenden kann: eines zur Abfrage einer (simulierten) Cloud Temple-API und eines zur Durchführung von Berechnungen.
-
Definition der Tools: Die Klassen
CloudTempleAPIToolundCalculatorToolerben vonBaseTool. Jedes Tool verfügt über:- Ein
name: Ein einfacher und beschreibender Name. - Ein
description: Kritisch – dies ist der Text, den der LLM liest, um zu entscheiden, welches Tool verwendet werden soll. Sie muss sehr klar beschreiben, was das Tool tut und wann es verwendet werden sollte. - Eine Methode
_run: Der Code, der tatsächlich ausgeführt wird, wenn der Agent dieses Tool auswählt.
- Ein
-
create_agent_with_tools:- LLM Initialization: Wir verwenden unseren Wrapper
CloudTempleLLM, der im ersten Tutorial definiert wurde. - Tool List: Wir geben dem Agenten die Liste der Tools, die er verwenden darf.
- Agent Prompt: Der Prompt ist sehr spezifisch. Es handelt sich um einen „Reasoning-Prompt“, der dem LLM anweist, wie er denken (
Thought), eine Aktion wählen (Action), eine Eingabe für diese Aktion bereitstellen (Action Input) und das Ergebnis beobachten (Observation) soll. Dies ist das zentrale Mechanismus des ReAct-Frameworks (Reasoning and Acting) verwendet hier. - Agent Creation:
create_react_agentassembles the LLM, tools, and prompt to create the agent. AgentExecutor: Dies ist der Motor, der den Agenten in einer Schleife ausführt, bis er eineFinal Answerproduziert. Der Parameterverbose=Trueist sehr nützlich, um den „inneren Dialog“ des Agenten zu sehen (seine Gedanken, Aktionen usw.).
- LLM Initialization: Wir verwenden unseren Wrapper
from langchain.agents import Tool, AgentExecutor, create_react_agent
from langchain.tools import BaseTool
from langchain.prompts import PromptTemplate
import requests
import json
import os
# (The CloudTempleLLM class is the same as in the first example)
# --- Definition der Werkzeuge ---
class CloudTempleAPITool(BaseTool):
"""Ein Werkzeug, das einen Aufruf an eine interne API simuliert, um Informationen über Dienste zu erhalten."""
name = "cloud_temple_api_checker"
description = "Nützlich, um Informationen über Dienste, Produkte und Angebote von Cloud Temple zu erhalten."
def _run(self, query: str) -> str:
# In einem echten Fall würde hier eine echte API aufgerufen werden.
print(f"--- Werkzeug CloudTempleAPITool mit der Anfrage aufgerufen: '{query}' ---")
if "service" in query.lower():
return "Cloud Temple bietet folgende Dienste an: IaaS, PaaS, LLMaaS, Managed Security."
return "Information nicht gefunden."
async def _arun(self, query: str) -> str:
# Asynchrone Implementierung ist für dieses Beispiel nicht erforderlich.
raise NotImplementedError("Das API-Werkzeug unterstützt keine asynchrone Ausführung.")
class SimpleCalculatorTool(BaseTool):
"""Ein einfaches Werkzeug zur Durchführung einfacher mathematischer Berechnungen."""
name = "simple_calculator"
description = "Nützlich zur Durchführung einfacher mathematischer Berechnungen. Erwartet einen gültigen Python-Ausdruck."
def _run(self, expression: str) -> str:
print(f"--- Werkzeug SimpleCalculatorTool mit dem Ausdruck aufgerufen: '{expression}' ---")
try:
# WARNUNG: eval() ist in der Produktion gefährlich. Nur für die Demonstration.
return str(eval(expression))
except Exception as e:
return f"Fehler bei der Berechnung: {e}"
async def _arun(self, expression: str) -> str:
raise NotImplementedError("Das Rechenwerkzeug unterstützt keine asynchrone Ausführung.")
# --- Agent Creation ---
def create_agent():
"""Configure and return a LangChain agent with the defined tools."""
print("1. Initializing the LLM for the agent...")
llm = CloudTempleLLM(api_key=os.getenv("LLMAAS_API_KEY", "your-api-key-here"))
tools = [CloudTempleAPITool(), SimpleCalculatorTool()]
# The prompt template is crucial: it guides the LLM in its reasoning.
template = """
Answer the following questions as best as you can. You have access to the following tools:
{tools}
Use the following format:
Question: the question you must answer
Thought: you must always think about what you will do
Action: the action to take, must be one of [{tool_names}]
Action Input: the input for the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation sequence can repeat)
Thought: I now know the final answer.
Final Answer: the final answer to the original question
Begin!
Question: {input}
Thought:{agent_scratchpad}
"""
prompt = PromptTemplate.from_template(template)
print("2. Creating the agent using the ReAct framework...")
agent = create_react_agent(llm, tools, prompt)
# The AgentExecutor is responsible for running the agent's cycles.
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
print(" -> Agent ready.")
return agent_executor
# --- Execution ---
def run_agent():
"""Führt den Agenten mit verschiedenen Fragen aus, um dessen Fähigkeiten zu testen."""
if os.getenv("LLMAAS_API_KEY") is None:
print("Bitte konfigurieren Sie Ihre LLMAAS_API_KEY.")
return
agent_executor = create_agent()
print("\n--- Test 1: Frage, die ein Informations-Tool erfordert ---")
question1 = "Welche Dienstleistungen bietet Cloud Temple?"
response1 = agent_executor.invoke({"input": question1})
print(f"\nEndgültige Antwort des Agents: {response1['output']}")
print("\n--- Test 2: Frage, die eine Berechnung erfordert ---")
question2 = "Was ergibt 125 * 8 + 50?"
response2 = agent_executor.invoke({"input": question2})
print(f"\nEndgültige Antwort des Agents: {response2['output']}")
if __name__ == "__main__":
run_agent()
5. OpenAI SDK-Integration
Nahtlose Migration von OpenAI
from openai import OpenAI
# Konfiguration für Cloud Temple LLMaaS
def setup_cloud_temple_client():
"""Client-Konfiguration für OpenAI für Cloud Temple"""
client = OpenAI(
api_key="your-cloud-temple-api-key",
base_url="https://api.ai.cloud-temple.com/v1"
)
return client
def test_openai_compatibility():
"""Test der Kompatibilität mit dem OpenAI SDK"""
client = setup_cloud_temple_client()
# Standard-Chat-Completion
response = client.chat.completions.create(
model="granite3.3:8b",
messages=[
{"role": "system", "content": "Du bist ein professioneller KI-Assistent."},
{"role": "user", "content": "Erkläre mir die Architektur von Cloud-Native-Systemen."}
],
max_tokens=300,
temperature=0.7
)
print(f"Antwort: {response.choices[0].message.content}")
# Streaming
stream = client.chat.completions.create(
model="granite3.3:8b",
messages=[
{"role": "user", "content": "Schreibe ein Gedicht über KI."}
],
stream=True,
max_tokens=200
)
print("Stream:")
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
print()
# Compatibility Test
test_openai_compatibility()
5. Integration von Semantic Kernel (Microsoft)
Semantic Kernel ist ein Open-Source-SDK von Microsoft, das die Integration von LLMs in .NET-, Python- und Java-Anwendungen ermöglicht. Obwohl er für die Azure OpenAI-Dienste optimiert ist, ermöglicht seine Flexibilität die Nutzung mit jeder OpenAI-kompatiblen API, einschließlich unserer eigenen.
Der Code erklärt
Dieses Beispiel benötigt nicht den vollständigen Semantic Kernel SDK. Es zeigt, wie das Konzept einer „semantischen Funktion“ durch einen einfachen Aufruf unserer API implementiert werden kann. Eine semantische Funktion ist im Wesentlichen ein strukturierter Prompt, der an ein LLM gesendet wird, um eine spezifische Aufgabe zu erfüllen.
semantic_kernel_simple(): Diese Funktion simuliert eine „Zusammenfassungsfunktion“.- Strukturierter Prompt : Wir verwenden eine
system-Nachricht, um dem LLM eine Rolle zuzuweisen („Du bist ein Experte für Zusammenfassungen“), und eineuser-Nachricht, die den zu summarisierenden Text enthält. Dies ist der Kern des Konzepts einer semantischen Funktion. - Direkter API-Aufruf : Ein einfacher
requests.post-Aufruf an unseren Endpunkt/v1/chat/completionsreicht aus, um die Funktion auszuführen.
Dieses Beispiel verdeutlicht, dass es nicht immer notwendig ist, ein schweres Framework zu verwenden. Für einfache und gut definierte Aufgaben ist ein direkter Aufruf der LLMaaS-API oft die effizienteste und leistungsfähigste Lösung.
import requests
import os
from dotenv import load_dotenv
def semantic_kernel_simulation():
"""
Simuliert eine „semantische Funktion“ zur Zusammenfassung durch direkten Aufruf der LLMaaS-API.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Bitte setzen Sie die Umgebungsvariable LLMAAS_API_KEY.")
return
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
text_to_summarize = """
Künstliche Intelligenz (KI) verändert zahlreiche industrielle Sektoren, indem sie Aufgaben automatisiert,
Prozesse optimiert und fortgeschrittene prädiktive Analysen ermöglicht.
Cloud Temple bietet mit seiner souveränen und SecNumCloud-zertifizierten LLMaaS-Angebot Unternehmen
die Möglichkeit, diese KI-Fähigkeiten zu integrieren, während die Sicherheit und Vertraulichkeit ihrer Daten gewährleistet bleibt.
"""
# Der Prompt kombiniert eine Anweisung (Systemrolle) und Daten (Benutzerrolle)
payload = {
"model": "granite3.3:8b",
"messages": [
{"role": "system", "content": "Du bist ein Assistent, der sich auf die Zusammenfassung technischer Dokumente spezialisiert hat."},
{"role": "user", "content": f"Fasse den folgenden Text in einer einzigen präzisen Satz zusammen: {text_to_summarize}"}
],
"max_tokens": 100,
"temperature": 0.5
}
try:
response = requests.post(
"https://api.ai.cloud-temple.com/v1/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
summary = result['choices'][0]['message']['content']
print("Ursprünglicher Text:\n", text_to_summarize)
print("\nGenerierter Zusammenfassung:\n", summary)
return summary
except requests.exceptions.RequestException as e:
print(f"Ein API-Fehler ist aufgetreten: {e}")
if __name__ == "__main__":
semantic_kernel_simulation()
6. Framework Haystack
Haystack ist ein weiterer leistungsstarker Open-Source-Framework zur Erstellung von Anwendungen für semantische Suche, RAG und Agenten. Wie beim Semantic Kernel kann unsere API direkt integriert werden.
Der Code erklärt
Dieses Beispiel simuliert einen grundlegenden „Pipeline“ von Haystack für die Antwortfindung im Kontext (Question Answering).
process_with_context: Diese Funktion stellt den Kern einer QA-Pipeline dar. Sie nimmt einenKontext(z. B. einen Absatz aus einem Dokument) und eineFrageentgegen.- Kontextueller Prompt: Der Prompt ist sorgfältig strukturiert, um sowohl den Kontext als auch die Frage einzuschließen. Dies ist eine zentrale Technik im RAG: Wir liefern dem LLM relevante Informationen, damit es eine faktengestützte Antwort formulieren kann.
- API-Aufruf: Ein einfacher
requests.post-Aufruf an unsere API reicht aus. Das LLM erhält Kontext und Frage und hat die Aufgabe, eine Antwort basierend ausschließlich auf den bereitgestellten Informationen zu synthetisieren.
Dieses Beispiel zeigt die Flexibilität der LLMaaS-API, die als Baustein für Textgenerierung in beliebigen Frameworks verwendet werden kann – selbst in solchen, für die keine offizielle Integration existiert.
import requests
import os
from dotenv import load_dotenv
def haystack_simulation():
"""
Simuliert eine Question-Answering-Pipeline im Stil von Haystack,
indem direkt auf die LLMaaS-API zugegriffen wird.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Bitte setzen Sie die Umgebungsvariable LLMAAS_API_KEY.")
return
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Der Kontext ist die Information, die das LLM verwenden darf.
context = """
Ein souveräner Cloud-Service ist eine Cloud-Infrastruktur, die vollständig innerhalb der Grenzen eines bestimmten Landes liegt und dessen Gesetzen unterliegt.
Die wichtigsten Vorteile sind die Gewährleistung der Datenlokalisierung, die Einhaltung lokaler Vorschriften (z. B. die DSGVO in Europa) sowie ein erhöhter Schutz vor Zugriffen durch ausländische Behörden gemäß extraterritorialen Gesetzen wie dem amerikanischen CLOUD Act.
"""
question = "Welche Vorteile bietet ein souveräner Cloud-Service?"
# Der Prompt leitet das LLM an, seine Antwort ausschließlich auf dem bereitgestellten Kontext zu basieren.
prompt = f"""
Beantworte die folgende Frage ausschließlich auf Grundlage des folgenden Kontexts.
Kontext:
---
{context}
---
Frage: {question}
"""
payload = {
"model": "granite3.3:8b",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 200,
"temperature": 0.2 # Niedrige Temperatur für eine faktengestützte Antwort
}
try:
response = requests.post(
"https://api.ai.cloud-temple.com/v1/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
result = response.json()
answer = result['choices'][0]['message']['content']
print(f"Frage: {question}")
print("\nGenerierte Antwort:\n", answer)
return answer
except requests.exceptions.RequestException as e:
print(f"Ein API-Fehler ist aufgetreten: {e}")
if __name__ == "__main__":
haystack_simulation()
7. Integration von LlamaIndex
LlamaIndex ist ein Framework, das speziell für die Entwicklung von RAG-Anwendungen (Retrieval-Augmented Generation) konzipiert wurde. Es bietet hochwertige Komponenten für die Dateninjektion, Indexierung und Abfrage. Unsere API ist mit der OpenAI-Schnittstelle kompatibel und lässt sich daher sehr einfach integrieren.
Der Code erklärt
Dieses Beispiel zeigt wie LlamaIndex so konfiguriert wird, dass die LLMaaS-API für die Textgenerierung verwendet wird, während gleichzeitig ein lokales Embedding-Modell für die Vektorisierung eingesetzt wird.
setup_and_run_llamaindex: Diese einzige Funktion koordiniert den gesamten Prozess.- LLM-Konfiguration: LlamaIndex bietet die Klasse
OpenAILike, die es ermöglicht, mit jeder API zu kommunizieren, die das OpenAI-Format unterstützt. Es genügt,api_baseund eineapi_keybereitzustellen. Dies ist die einfachste Methode, um unseren LLM kompatibel zu machen. - Embedding-Konfiguration: Für dieses Beispiel verwenden wir ein lokales Embedding-Modell (
HuggingFaceEmbedding). Dies verdeutlicht die Flexibilität von LlamaIndex, das die Kombination verschiedener Komponenten erlaubt. Sie könnten genauso gut die KlasseLLMaaSEmbeddingsaus den vorherigen Beispielen verwenden, um unsere Embedding-API zu nutzen. Settings: DasSettings-Objekt von LlamaIndex ist eine praktische Möglichkeit, Standardkomponenten (LLM, Embedding-Modell, Chunk-Größe usw.) zu konfigurieren, die von anderen LlamaIndex-Objekten verwendet werden.- Daten-Ingestion:
SimpleDirectoryReaderlädt die Dokumente aus einem Verzeichnis. - Index-Erstellung:
VectorStoreIndex.from_documentsist die hochwertige Methode von LlamaIndex. Sie verwaltet automatisch das Zerlegen in Chunks, die Vektorisierung der Chunks (unter Verwendung des imSettingskonfiguriertenembed_model) und die Erstellung des Index im Speicher. - Abfrage-Engine:
.as_query_engine()erstellt eine einfache Schnittstelle, um Fragen an unseren Index zu stellen. Wenn Sie.query()aufrufen, wird Ihre Frage vektorisiert, die relevantesten Dokumente im Index gefunden und diese zusammen mit der Frage an den LLM (wie inSettingskonfiguriert) gesendet, um eine Antwort zu generieren.
- LLM-Konfiguration: LlamaIndex bietet die Klasse
# Dependencies:
# pip install llama-index llama-index-llms-openai-like llama-index-embeddings-huggingface
import os
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai_like import OpenAILike
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import shutil
def setup_and_run_llamaindex():
"""
Configure and run a simple RAG pipeline with LlamaIndex and the LLMaaS API.
"""
load_dotenv()
api_key = os.getenv("LLMAAS_API_KEY")
if not api_key:
print("Please set the LLMAAS_API_KEY environment variable.")
return
# 1. Configure the LLM to use the LLMaaS API via the OpenAILike interface
print("1. Configuring the LLM to point to the LLMaaS API...")
llm = OpenAILike(
api_key=api_key,
api_base="https://api.ai.cloud-temple.com/v1",
model="granite3.3:8b",
is_chat_model=True,
# Sometimes it's necessary to add context window parameters for certain models
# context_window=3900,
)
# 2. Configure the embedding model (local in this example for simplicity)
print("2. Configuring the local embedding model...")
embed_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 3. Apply configurations globally via LlamaIndex's Settings object
Settings.llm = llm
Settings.embed_model = embed_model
print(" -> LLM and embedding model configured.")
# 4. Create a simple knowledge base in a temporary directory
print("4. Creating and loading a temporary knowledge base...")
temp_dir = "temp_llama_data"
os.makedirs(temp_dir, exist_ok=True)
knowledge_file = os.path.join(temp_dir, "knowledge.txt")
with open(knowledge_file, "w", encoding="utf-8") as f:
f.write("The LLMaaS offering from Cloud Temple is a sovereign generative AI solution, "
"fully operated in France and certified SecNumCloud by ANSSI.")
documents = SimpleDirectoryReader(temp_dir).load_data()
print(f" -> {len(documents)} document(s) loaded.")
# 5. Create the vector index. LlamaIndex handles chunking and embedding automatically.
print("5. Creating the vector index...")
index = VectorStoreIndex.from_documents(documents)
print(" -> Index created.")
# 6. Create the query engine and query the knowledge base
print("6. Creating the query engine and querying...")
query_engine = index.as_query_engine()
question = "What are the sovereignty guarantees of the LLMaaS offering?"
response = query_engine.query(question)
print(f"\nQuestion: {question}")
print(f"Answer: {response}")
# Clean up the temporary directory
shutil.rmtree(temp_dir)
print(f"\nTemporary directory '{temp_dir}' deleted.")
if __name__ == "__main__":
setup_and_run_llamaindex()
8. Setting up the CLINE extension for VSCode
This tutorial guides you through configuring the CLINE extension in Visual Studio Code to use Cloud Temple's language models directly from your editor.
Konfigurations-Schritte
-
CLINE-Einstellungen öffnen: Öffnen Sie in VSCode die Einstellungen der CLINE-Erweiterung.
-
Neues Modell erstellen: Fügen Sie eine neue Modellkonfiguration hinzu.
-
Felder ausfüllen: Konfigurieren Sie die Felder wie unten dargestellt, basierend auf dem Bild unten.
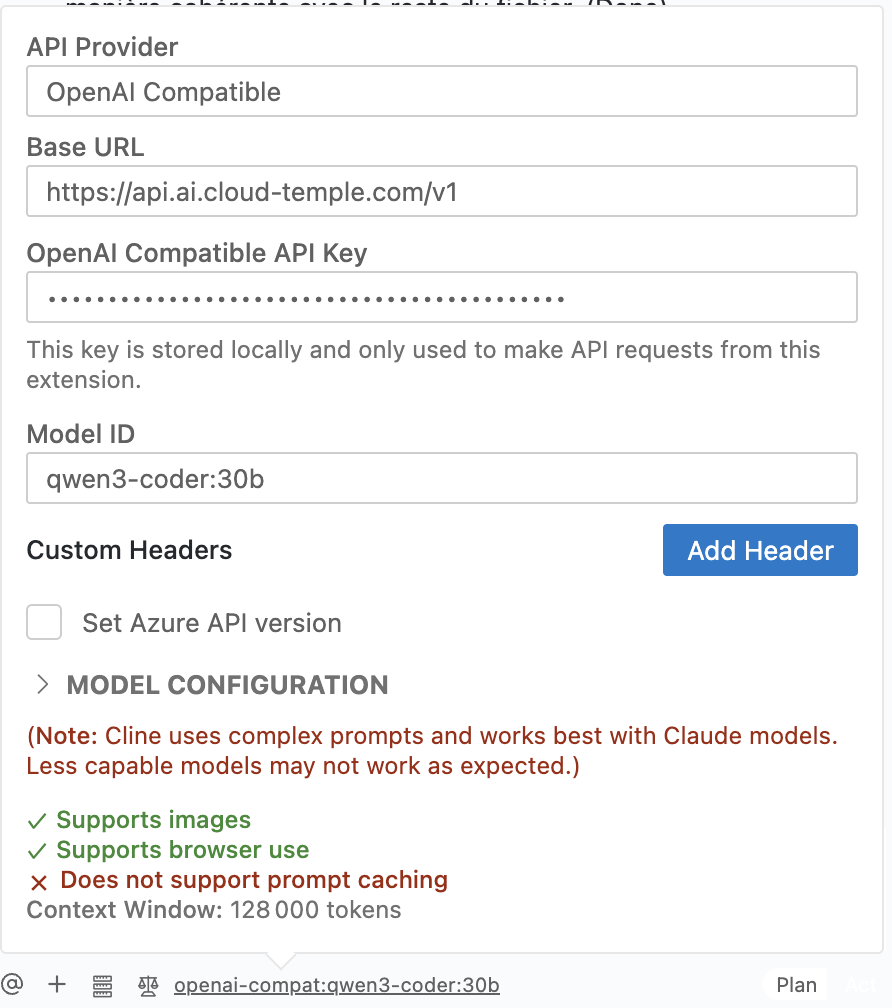
- API-Anbieter: Wählen Sie
OpenAI-kompatibel. - Basis-URL: Geben Sie den API-Endpunkt von LLMaaS von Cloud Temple ein:
https://api.ai.cloud-temple.com/v1. - OpenAI-kompatible API-Schlüssel: Fügen Sie den API-Schlüssel ein, den Sie über die Cloud Temple-Konsole generiert haben.
:::tip API-Schlüssel generieren Um Ihren API-Schlüssel zu generieren, gehen Sie in die Cloud Temple-Konsole, Bereich LLMaaS > API-Schlüssel, und klicken Sie auf "API-Schlüssel erstellen".
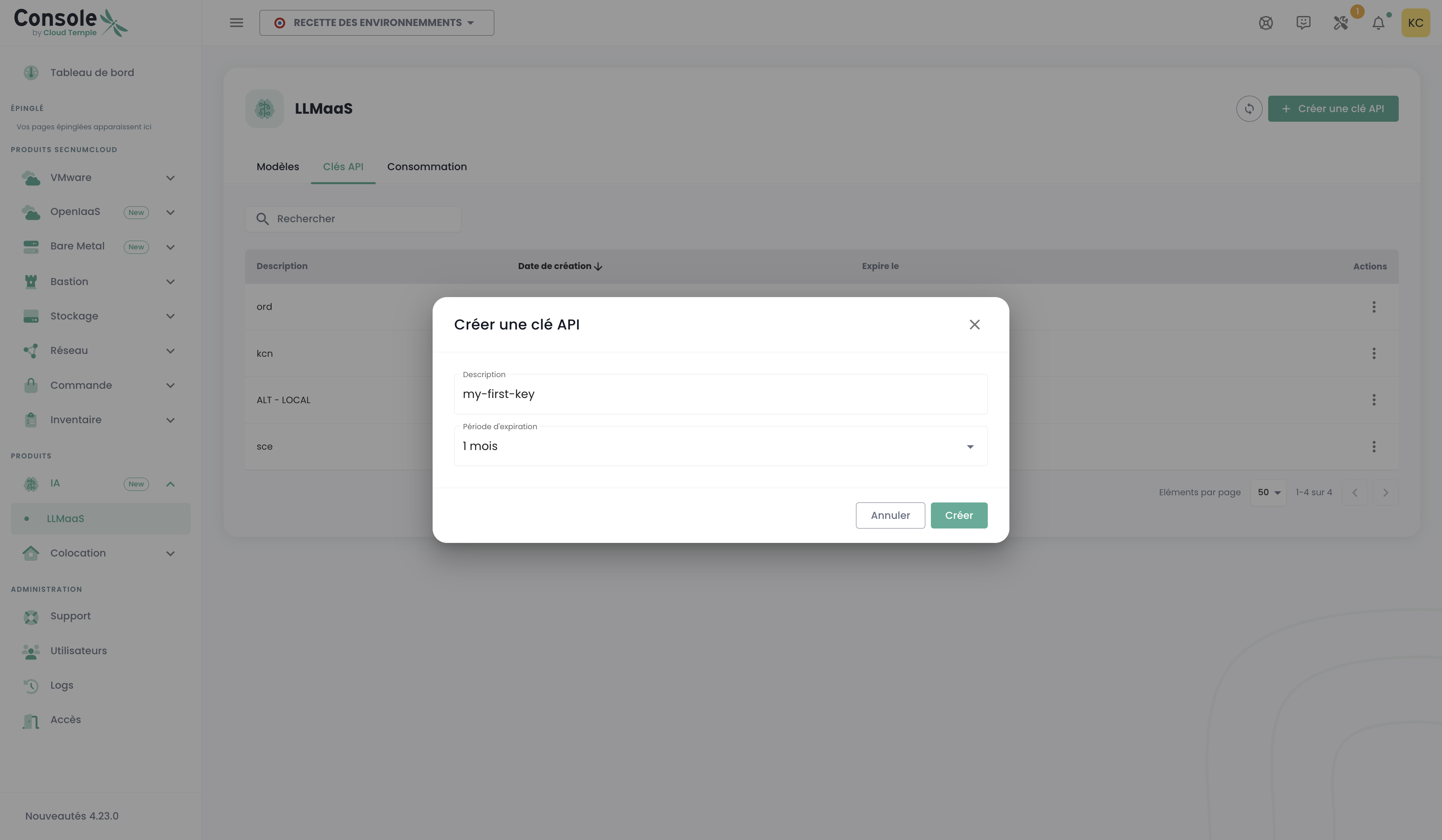 :::
:::- Modell-ID: Geben Sie das Modell an, das Sie verwenden möchten, beispielsweise
qwen3-coder:30b. Eine Liste der verfügbaren Modelle finden Sie im Abschnitt Modelle. - Modellkonfiguration:
- Unterstützt Bilder: Aktivieren Sie dieses Feld, falls das Modell Bildunterstützung bietet.
- Unterstützt Browser-Nutzung: Aktivieren Sie dieses Feld.
- Größe des Kontextfensters: Geben Sie die Größe des Kontextfensters des Modells an (z. B.
128000). - Maximale Ausgabetoken: Belassen Sie den Wert auf
-1, um eine unbeschränkte Ausgabe standardmäßig zu ermöglichen. - Temperatur: Stellen Sie die Temperatur entsprechend Ihren Anforderungen ein (z. B.
0).
- API-Anbieter: Wählen Sie
Sie können nun ein Modell in CLINE auswählen und es zum Generieren von Code, Beantworten von Fragen usw. verwenden.
💡 Advanced Examples
The GitHub directory below contains a collection of code examples and scripts demonstrating the various features and use cases of Cloud Temple's LLM as a Service (LLMaaS) offering:
Cloud-Temple/product-llmaas-how-to
You'll find practical guides for:
-
Information Extraction and Text Analysis: Ability to analyze documents and extract structured data such as entities, events, relationships, and attributes, leveraging domain-specific ontologies (e.g., legal, HR, IT).
-
Conversational Interaction and Chatbots: Development of conversational agents capable of dialogue, maintaining conversation history, using system prompts, and invoking external tools.
-
Audio Transcription (Speech-to-Text): Conversion of audio content into text, including for large files, using techniques such as segmentation, normalization, and batch processing.
-
Text Translation: Translation of documents from one language to another, managing context across multiple segments to improve coherence.
-
Model Management and Evaluation: Listing available language models via the API, reviewing their specifications, and running tests to compare performance.
-
Real-Time Response Streaming: Demonstration of the capability to receive and display model responses progressively (token by token), essential for interactive applications.
-
RAG Pipeline with In-Memory Knowledge Base: Educational RAG demonstrator illustrating the Retrieval-Augmented Generation process. Uses the LLMaaS API for embedding and generation, with vector storage in memory (FAISS) for clear understanding of the workflow.
-
RAG Pipeline with Vector Database (Qdrant): Complete, containerized RAG demonstrator using Qdrant as the vector database. The LLMaaS API is used for document embedding and generating augmented responses.
-
OCR & Document Analysis (DeepSeek-OCR): Comprehensive guide and demonstration tool to convert images and PDFs into structured Markdown, extract tables, and transcribe mathematical formulas. See the dedicated documentation.