Anleitung: OCR meistern mit DeepSeek
Diese Anleitung beschreibt die Verwendung des DeepSeek-OCR-Modells, einer hochmodernen Lösung für die optische Kontextkomprimierung und Dokumentenanalyse.
Architektur und Funktionsweise
Im Gegensatz zu herkömmlichen OCR-Systemen ist DeepSeek-OCR ein End-to-End-Vision-Language-Modell, das entwickelt wurde, um Dokumente visuell zu "lesen" und zu "verstehen".
Technische Architektur
Es kombiniert zwei innovative Komponenten:
- DeepEncoder (380M): Ein hybrider visueller Encoder, der SAM-base (für die lokale Wahrnehmung) und CLIP-large (für das globale Wissen) kombiniert, verbunden durch einen 16x konvolutionellen Kompressor. Dies ermöglicht die Verarbeitung hochauflösender Bilder mit sehr wenigen visuellen Token.
- MoE-Decoder (3B): Basierend auf DeepSeek3B-MoE (570M aktive Parameter) generiert er strukturierten Text aus den komprimierten visuellen Token.
Auflösungsmodi und Token-Verbrauch
Das Modell passt seinen Token-Verbrauch an die Bildauflösung an. Je größer das Bild ist, desto mehr Token verbraucht es, aber desto höher ist auch die Präzision.
| Modus | Auflösung (px) | Vision-Token | Empfohlene Verwendung |
|---|---|---|---|
| Tiny | 512 x 512 | 64 | Folien, sehr großer Text |
| Small | 640 x 640 | 100 | Einfache Dokumente, Tickets |
| Base | 1024 x 1024 | 256 | Standard-A4-Seiten |
| Large | 1280 x 1280 | 400 | Dichte Dokumente, kleine Zeichen |
| Gundam | Dynamisch | ~800 | Zeitungen, Baupläne, komplexe Scans |
Um Kosten und Latenz zu optimieren, ändern Sie die Größe Ihrer Bilder auf die minimale Auflösung, die erforderlich ist, damit der Text lesbar bleibt.
Multilingualer Support
Das Modell wurde an einem umfangreichen Korpus mehrsprachiger Dokumente trainiert und unterstützt die Erkennung von fast 100 Sprachen (darunter Deutsch, Englisch, Chinesisch, Arabisch usw.), mit oder ohne Layout-Erhaltung.
Prompt-Leitfaden (Prompt Engineering)
Die Qualität des Ergebnisses hängt direkt vom verwendeten Prompt ab. DeepSeek-OCR reagiert auf spezifische Anweisungen, um seine verschiedenen Funktionen zu aktivieren.
1. Standard-OCR (Markdown)
Um Text mit seiner Struktur (Überschriften, Absätze, Tabellen) zu extrahieren.
Prompt:
Konvertieren Sie das Dokument in Markdown.
Ergebnis: Strukturierter Text, formatierte Tabellen, Layout erhalten.
2. "Deep Parsing" (Abbildungen, Grafiken, Formeln)
Zur Analyse des semantischen Inhalts von Grafiken, chemischen Formeln oder geometrischen Diagrammen.
Prompt:
Analysieren Sie die Abbildung.
Funktionen:
- Grafiken (Balken/Linien/Kreisdiagramm): Konvertiert in HTML- oder Markdown-Tabelle.
- Chemische Formeln: Konvertiert in das SMILES-Format.
- Geometrie: Beschreibt geometrische Elemente.
3. Grounding (Lokalisierung)
Um die Koordinaten eines bestimmten Elements im Bild zu finden.
Prompt:
Lokalisieren Sie <|ref|>zu findendes Element<|/ref|> im Bild.
Beispiel: Lokalisieren Sie <|ref|>Gesamt<|/ref|> im Bild.
Ergebnis: Gibt die Koordinaten des Begrenzungsrahmens (Bounding Box) des Elements zurück.
4. Objekterkennung
Um alle sichtbaren Objekte aufzulisten und zu lokalisieren.
Prompt:
Identifizieren Sie alle Objekte im Bild und geben Sie sie in Begrenzungsrahmen aus.
Implementierungs-Tutorial (Python)
Hier ist ein vollständiges Beispiel, das zeigt, wie Sie Ihren API-Aufruf strukturieren, um diese Funktionen zu nutzen.
Voraussetzungen: Bildformat und Abhängigkeiten
- Format: JPEG oder PNG.
- Modus: RGB (keine Alpha-Transparenz).
- PDF: Müssen vorher in Bilder umgewandelt werden (150-300 DPI).
- Größe: Es wird empfohlen, sehr hochauflösende Bilder zu verkleinern, um Fehler aufgrund von Größenbeschränkungen (413 Payload Too Large) zu vermeiden.
Installieren Sie die erforderlichen Bibliotheken:
pip install requests Pillow
Code: Dokumentenanalyse (OCR)
Nehmen wir das Beispiel dieses Schweizer Kassenbons:

Hier ist ein robustes Skript, das die Bildgrößenänderung und die optimale Codierung verwaltet:
import base64
import io
import requests
from PIL import Image
# Konfiguration
API_KEY = "IHR_API_TOKEN"
API_URL = "https://api.ai.cloud-temple.com/v1/chat/completions"
IMAGE_PATH = "ReceiptSwiss.jpg" # Stellen Sie sicher, dass das Bild im aktuellen Verzeichnis ist
def encode_image_optimized(path):
"""
Optimiert das Bild (Größenänderung + JPEG-Kompression) für die API.
"""
with Image.open(path) as img:
# 1. Konvertierung in RGB (um Probleme mit PNG/Alpha zu vermeiden)
if img.mode != 'RGB':
img = img.convert('RGB')
# 2. Intelligente Größenänderung, wenn zu groß (> 2048px)
# Dies verhindert 413 (Payload Too Large) Fehler und beschleunigt die Verarbeitung
max_size = 2048
if max(img.size) > max_size:
img.thumbnail((max_size, max_size))
# 3. JPEG-Kompression im Speicher
buffer = io.BytesIO()
img.save(buffer, format="JPEG", quality=85)
return base64.b64encode(buffer.getvalue()).decode('utf-8')
# 1. Aufbau der multimodalen Nachricht
encoded_image = encode_image_optimized(IMAGE_PATH)
payload = {
"model": "deepseek-ai/DeepSeek-OCR",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Konvertieren Sie das Dokument in Markdown." # Standard-OCR-Prompt
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
}
}
]
}
],
"temperature": 0.0, # ENTSCHEIDEND: 0.0 für die Wiedergabetreue
"max_tokens": 4096
}
# 2. Senden
print("Sende die Anfrage...")
response = requests.post(
API_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json=payload
)
# 3. Ergebnis
if response.status_code == 200:
print("\n--- OCR-Ergebnis ---\n")
print(response.json()['choices'][0]['message']['content'])
else:
print(f"Fehler {response.status_code}: {response.text}")
Beispielausgabe:
# Berghotel
**Grosse Scheidegg**
3818 Grindelwald
Familie R. Müller
Bestell-Nr. 4572
Bar Tisch 7/01
2xLatte Macchiato à 4.50 CHF 9.00
1xGloki à 5.00 CHF 5.00
...
**Total:** CHF **54.50**
**Inkl. 7.6% MwSt** 54.50 CHF: 3.85
### Code: Grafikanalyse (Deep Parsing)
Um ein Finanzdiagramm in einem Bericht zu analysieren, ändern Sie einfach den Prompt-Text in der obigen Payload:
```python
# ... in der Payload ...
"text": "Analysieren Sie die Abbildung."
# ...
Das Modell gibt eine textliche oder tabellarische Darstellung der Diagrammdaten zurück.
Erweiterte Anwendungsfälle
Extraktion komplexer Tabellen
DeepSeek-OCR zeichnet sich durch die Konvertierung von Tabellen aus, selbst ohne klare Trennlinien.
Eingabebild:
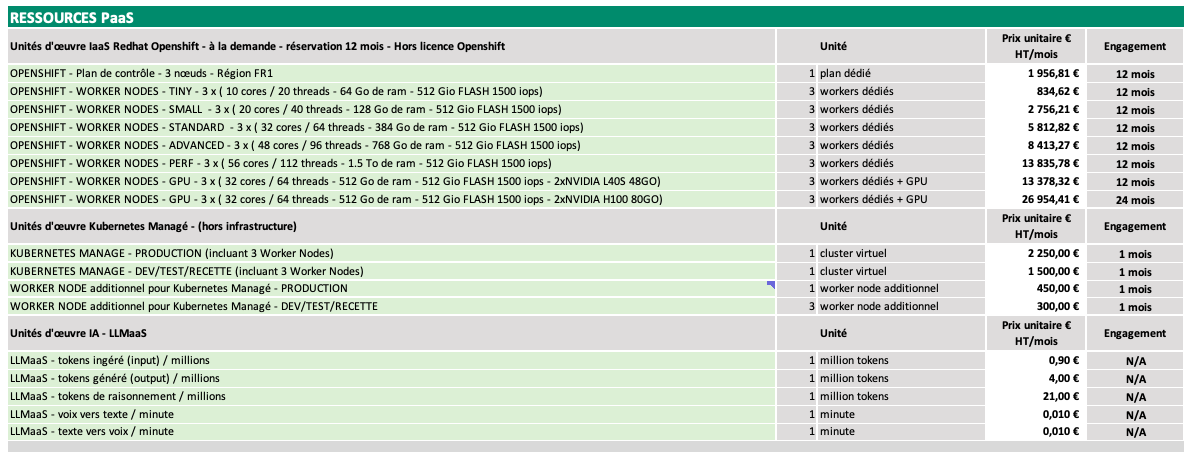
Modellausgabe (Prompt: "Convert the document to markdown table."):
# PAAS-RESSOURCEN
## Redhat Openshift laaS Workload-Einheiten - On-Demand - 12-Monats-Reservierung - Ohne Openshift-Lizenz
| | Einheit | Einzelpreis € exkl. MwSt / Monat | Engagement |
|---|---|---|---|
| OPENSHIFT - Control Plane - 3 Knoten - Region FR1 | 1 dedizierter Plan | 1.956,81 € | 12 Monate |
| OPENSHIFT - WORKER-KNOTEN - TINY - 3 x (10 Cores / 20 Threads - 64 GB RAM - 512 GB FLASH 1500 IOPS) | 3 dedizierte Worker | 834,62 € | 12 Monate |
| OPENSHIFT - WORKER-KNOTEN - SMALL - 3 x (20 Cores / 40 Threads - 128 GB RAM - 512 GB FLASH 1500 IOPS) | 3 dedizierte Worker | 2.756,21 € | 12 Monate |
| OPENSHIFT - WORKER-KNOTEN - STANDARD - 3 x (32 Cores / 64 Threads - 384 GB RAM - 512 GB FLASH 1500 IOPS) | 3 dedizierte Worker | 5.812,82 € | 12 Monate |
| OPENSHIFT - WORKER-KNOTEN - ADVANCED - 3 x (48 Cores / 96 Threads - 768 GB RAM - 512 GB FLASH 1500 IOPS) | 3 dedizierte Worker | 8.413,27 € | 12 Monate |
| OPENSHIFT - WORKER-KNOTEN - PERF - 3 x (56 Cores / 112 Threads - 1,5 TB RAM - 512 GB FLASH 1500 IOPS) | 3 dedizierte Worker | 13.835,78 € | 12 Monate |
| OPENSHIFT - WORKER-KNOTEN - GPU - 3 x (32 Cores / 64 Threads - 512 GB RAM - 512 GB FLASH 1500 IOPS - 2xNVIDIA L40S 48GB) | 3 dedizierte Worker + GPU | 13.378,32 € | 12 Monate |
| OPENSHIFT - WORKER-KNOTEN - GPU - 3 x (32 Cores / 64 Threads - 512 GB RAM - 512 GB FLASH 1500 IOPS - 2xNVIDIA H100 80GB) | 3 dedizierte Worker + GPU | 26.954,41 € | 24 Monate |
## Kubernetes Manage Workload-Einheiten - (ohne Infrastruktur)
| | Einheit | Einzelpreis € exkl. MwSt / Monat | Engagement |
|---|---|---|---|
| KUBERNETES MANAGE - PRODUKTION (inkl. 3 Worker-Knoten) | 1 virtueller Cluster | 2.250,00 € | 1 Monat |
| KUBERNETES MANAGE - ENTWICKLUNG/TEST/ABNAHME (inkl. 3 Worker-Knoten) | 1 virtueller Cluster | 1.500,00 € | 1 Monat |
| ZUSÄTZLICHER WORKER-KNOTEN für Kubernetes Manage - PRODUKTION | 1 zusätzlicher Worker-Knoten | 450,00 € | 1 Monat |
| ZUSÄTZLICHER WORKER-KNOTEN für Kubernetes Manage - ENTWICKLUNG/TEST/ABNAHME | 3 zusätzliche Worker-Knoten | 300,00 € | 1 Monat |
## KI Workload-Einheiten - LLMaas
| | Einheit | Einzelpreis € exkl. MwSt / Monat | Engagement |
|---|---|---|---|
| LLMaas - Input-Token / Million | 1 Million Token | 0,90 € | N/A |
| LLMaas - Output-Token / Million | 1 Million Token | 4,00 € | N/A |
| LLMaas - Reasoning-Token / Million | 1 Million Token | 21,00 € | N/A |
| LLMaas - Sprache-zu-Text / Minute | 1 Minute | 0,010 € | N/A |
| LLMaas - Text-zu-Sprache / Minute | 1 Minute | 0,010 € | N/A |
### Mathematische Formeln (LaTeX)
Ideal für wissenschaftliche Dokumente. Das Modell erkennt Gleichungen und gibt sie in Standard-LaTeX-Syntax aus.
**Eingabebild:**

**Modellausgabe (Prompt: "Convert to latex."):**
> Hier ist die mathematische Darstellung des OCR-Ergebnisses:
Mittlerer quadratischer Fehler:
$$
\frac{1}{T} \int_{-T/2}^{T/2} \left[ f(t) - T_N(t) \right]^2 dt = E_N \left( a_0, \ldots, a_N; b_1, \ldots, b_N \right)
$$
Bedingung für das Minimum von $E_N$:
$$
\frac{\partial E_N}{\partial a_0} = 0, \frac{\partial E_N}{\partial a_i} = 0, \ldots, \frac{\partial E_N}{\partial b_N} = 0
$$
(2n+1) Gleichungen:
$$
\frac{\partial E_N}{\partial a_i} = \frac{1}{T} \int_{-T/2}^{T/2} \frac{\partial}{\partial a_i} \left( f(t) - T_N(t) \right)^2 dt = \frac{1}{T} \int_{-T/2}^{T/2} \left\{ 2 \left( f(t) - T_N(t) \right) \frac{\partial}{\partial a_i} \left( f(t) - T_N(t) \right) \right\} dt
$$
$$
= -\frac{1}{T} \int_{-T/2}^{T/2} 2 \left( f(t) - T_N(t) \right) \cos i \omega t dt = 0 \quad \text{für stationären Punkt.}
$$
$$
\frac{2}{T} \int_{-T/2}^{T/2} f(t) \cos i \omega t dt = \frac{2}{T} \int_{-T/2}^{T/2} \left[ \frac{a_0}{2} + \sum_{n=1}^{N} \left( a_n \cos n \omega t + b_n \sin n \omega t \right) \right] \cos i \omega t dt \quad i \neq 0
$$
## Bekannte Einschränkungen
- **Orientierung**: Das Modell unterstützt keine automatische Rotation. Stellen Sie sicher, dass Ihre Bilder korrekt ausgerichtet sind (Text horizontal).
- **Handschrift**: Obwohl leistungsfähig, ist die Fehlerrate bei komplexer kursiver Handschrift höher als bei gedrucktem Text.
- **Sehr hohe Auflösung**: Bilder, die die Abmessungen des "Gundam"-Modus (~2000x2000) überschreiten, werden skaliert, wodurch mikroskopischer Text unlesbar werden kann. Teilen Sie sehr große Bilder in mehrere kleinere auf.