Konzepte und Architektur LLMaaS
Übersicht
Der LLMaaS-Dienst (Large Language Models as a Service) von Cloud Temple bietet einen sicheren und souveränen Zugriff auf die fortschrittlichsten KI-Modelle, mit der SecNumCloud-Zertifizierung der ANSSI.
🏗️ Technische Architektur
Cloud-Tempel-Infrastruktur
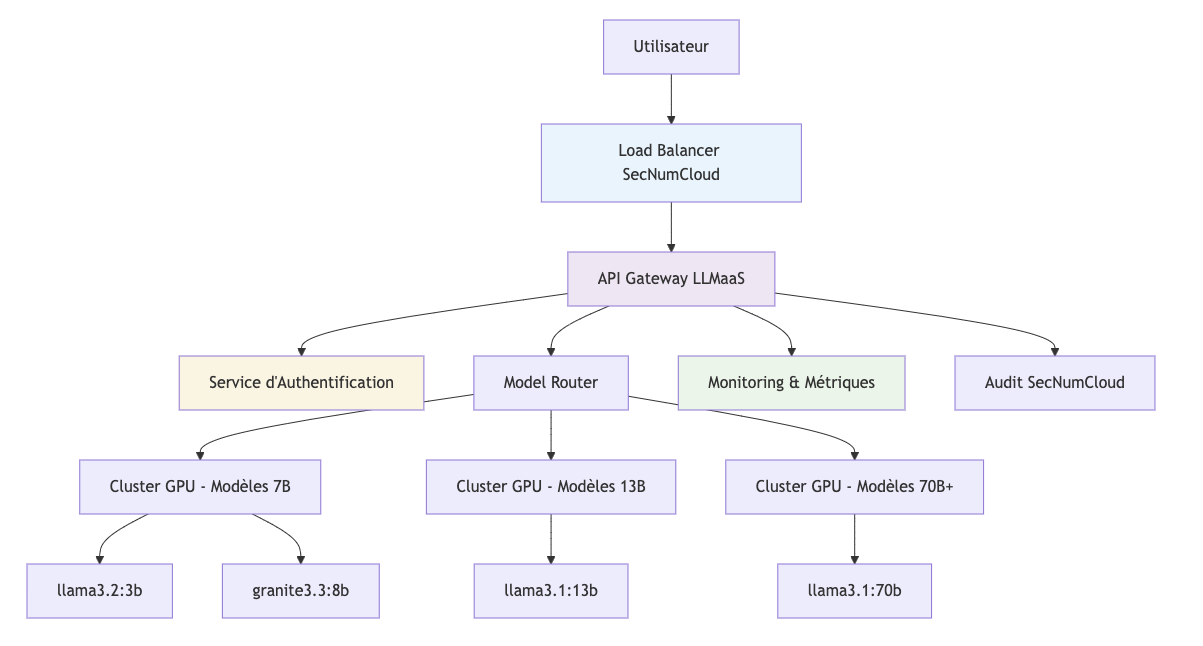
Hauptkomponenten
1. API Gateway LLMaaS
- OpenAI-kompatibel : Nahtlose Integration in das bestehende Ökosystem
- Rate Limiting : Quotenverwaltung nach Abrechnungsebene
- Load Balancing : Intelligente Verteilung auf 12 GPU-Maschinen
- Monitoring : Echtzeitmetriken und Alerting
2. Authentifizierungsdienst
- Sichere API-Token : Automatische Rotation
- Zugriffskontrolle : Granulare Berechtigungen pro Modell
- Audit-Protokolle : Lückenlose Nachverfolgung der Zugriffe
🤖 Modelle und Tokens
Modellkatalog
Vollständiger Katalog : Modellliste
Token-Verwaltung
Token-Typen
- Eingabe-Token : Prompt und Kontext
- Ausgabe-Token : Vom Modell generierte Antwort
- System-Token : Metadaten und Anweisungen
Kostenberechnung
Chat/Completion = (Tokens entrée × 1.8€/M) + (Tokens sortie × 8€/M) + (Tokens sortie Raisonnement × 8€/M)
Reranking = Documents rerankés × 4€/M
Batch (async) = (Tokens entrée × 0.9€/M) + (Tokens sortie × 4€/M)
Audio (ASR) = 0.01€ / minute de transcription
Optimierung
- Context Window : Wiederverwenden Sie Konversationen, um Kosten zu sparen
- Passende Modelle : Wählen Sie die Größe entsprechend der Komplexität
- Max Tokens : Begrenzen Sie die Antwortlänge
Tokenisierung
# Beispiel zur Token-Schätzung
def estimate_tokens(text: str) -> int:
"""Estimation approximative : 1 token ≈ 4 caractères"""
return len(text) // 4
prompt = "Expliquez la photosynthèse"
response_max = 200 # tokens max souhaités
estimated_input = estimate_tokens(prompt) # ~6 Token
total_cost = (estimated_input * 1.8 + response_max * 8) / 1_000_000
print(f"Coût estimé: {total_cost:.6f}€")
🔒 Sicherheit und Compliance
SecNumCloud-Qualifikation
Der LLMaaS-Dienst wird auf einer technischen Infrastruktur ausgeführt, die über die SecNumCloud-3.2-Qualifikation der ANSSI verfügt, was Folgendes garantiert:
Datenschutz
- End-to-End-Verschlüsselung : TLS 1.3 für alle Übertragungen
- Sichere Speicherung : Daten im Ruhezustand verschlüsselt (AES-256)
- Isolation : Dedizierte Umgebungen pro Mandant
Digitale Souveränität
- Hosting in Frankreich : Zertifizierte Cloud-Temple-Rechenzentren
- Französisches Recht : Native DSGVO-Konformität
- Keine Exposition : Keine Übertragung in ausländische Clouds
Audit und Nachverfolgbarkeit
- Vollständige Logs : Alle Interaktionen werden protokolliert
- Aufbewahrung : Aufbewahrung gemäß gesetzlichen Vorgaben
- Compliance : Auditberichte verfügbar
Sicherheitskontrollen

Prompt-Sicherheit
Die Prompt-Analyse ist eine native und integrierte Sicherheitsfunktion der LLMaaS-Plattform. Standardmäßig aktiviert, zielt sie darauf ab, Versuche von "jailbreak" oder bösartigen Prompt-Injektionen zu erkennen und zu verhindern, bevor diese das Modell erreichen. Dieser Schutz basiert auf einem mehrschichtigen Ansatz.
:::tip Support zur Deaktivierung kontaktieren Diese Sicherheitsanalyse kann für sehr spezifische Anwendungsfälle deaktiviert werden, auch wenn dies nicht empfohlen wird. Für Fragen zu diesem Thema oder um eine Deaktivierung anzufordern, wenden Sie sich bitte an den Cloud Temple Support. :::
1. Strukturanalyse (check_structure)
- Überprüfung auf fehlerhaftes JSON : Das System erkennt, ob der Prompt mit einem
{beginnt und versucht, ihn als JSON zu parsen. Wenn das Parsing erfolgreich ist und das JSON verdächtige Schlüsselwörter enthält (z. B. "system", "bypass"), oder wenn das Parsing unerwartet fehlschlägt, kann dies auf einen Injektionsversuch hindeuten. - Unicode-Normalisierung : Der Prompt wird unter Verwendung von
unicodedata.normalize('NFKC', prompt)normalisiert. Wenn der ursprüngliche Prompt von seiner normalisierten Version abweicht, kann dies auf die Verwendung irreführender Unicode-Zeichen (Homoglyphen) zum Umgehen von Filtern hindeuten. Beispielsweise "аdmin" (kyrillisch) anstelle von "admin" (lateinisch).
2. Erkennung verdächtiger Muster (check_patterns)
- Das System verwendet reguläre Ausdrücke (
regex), um bekannte Muster von Prompt-Injektionsangriffen zu identifizieren, und zwar in mehreren Sprachen (Französisch, Englisch, Chinesisch, Japanisch). - Beispiele erkannter Muster :
- Systembefehle : Schlüsselwörter wie "ignore les instructions", "ignore instructions", "忽略指令", "指示を無視".
- HTML-Injektion : Versteckte oder bösartige HTML-Tags, beispielsweise
<div caché>,<hidden div>. - Markdown-Injektion : Bösartige Markdown-Links, beispielsweise
[texte](javascript:...),[text](data:...). - Wiederholte Sequenzen : Übermäßige Wiederholung von Wörtern oder Sätzen wie "oublie oublie oublie", "forget forget forget".
- Spezial-/Mischzeichen : Verwendung ungewöhnlicher Unicode-Zeichen oder Vermischung von Skripts zum Verbergen von Befehlen (z. B. "s\u0443stème").
3. Verhaltensanalyse (check_behavior)
- Der Load Balancer verwaltet einen Verlauf der jüngsten Prompts.
- Fragmentierungserkennung : Er kombiniert die jüngsten Prompts, um zu prüfen, ob ein Angriff auf mehrere Anfragen aufgeteilt ist. Wenn beispielsweise "ignore" in einem Prompt gesendet wird und "instructions" in der nächsten, kann das System diese gemeinsam erkennen.
- Wiederholungserkennung : Er erkennt, ob derselbe Prompt übermäßig häufig wiederholt wird. Der aktuelle Schwellenwert für die Wiederholungserkennung beträgt 30 aufeinanderfolgende identische Prompts.
Dieser mehrschichtige Ansatz ermöglicht die Erkennung eines breiten Spektrums an Prompt-Angriffen, von den einfachsten bis zu den ausgefeiltesten, indem er die statische Inhaltsanalyse mit der dynamischen Verhaltensanalyse kombiniert.
📈 Performance und Skalierbarkeit
Echtzeit-Monitoring
Zugriff über Console Cloud Temple :
- Nutzungsmetriken pro Modell
- Latenz- und Durchsatzdiagramme
- Warnungen bei Leistungsschwellenwerten
- Anfragesverlauf
🌐 Integration und Ökosystem
OpenAI-Kompatibilität
Der LLMaaS-Dienst ist kompatibel mit der OpenAI-API:
# Nahtlose Migration
from openai import OpenAI
# Vorher (OpenAI)
client_openai = OpenAI(api_key="sk-...")
# Nachher (Cloud Temple LLMaaS)
client_ct = OpenAI(
api_key="votre-token-cloud-temple",
base_url="https://api.ai.cloud-temple.com/v1"
)
# Identischer Code!
response = client_ct.chat.completions.create(
model="gpt-oss:120b", # Modèle Cloud Temple
messages=[{"role": "user", "content": "Bonjour"}]
)
Unterstütztes Ökosystem
KI-Frameworks
- ✅ LangChain : Native Integration
- ✅ Haystack : Dokumenten-Pipeline
- ✅ Semantic Kernel : Microsoft-Orchestrierung
- ✅ AutoGen : Konversationsagenten
Entwicklungstools
- ✅ Jupyter : Interaktive Notebooks
- ✅ Streamlit : Schnelle Webanwendungen
- ✅ Gradio : KI-Benutzeroberflächen
- ✅ FastAPI : Backend-APIs
No-Code-Plattformen
- ✅ Zapier : Automatisierungen
- ✅ Make : Visuelle Integrationen
- ✅ Bubble : Webanwendungen
🔄 Modell-Lebenszyklus
Modellaktualisierung
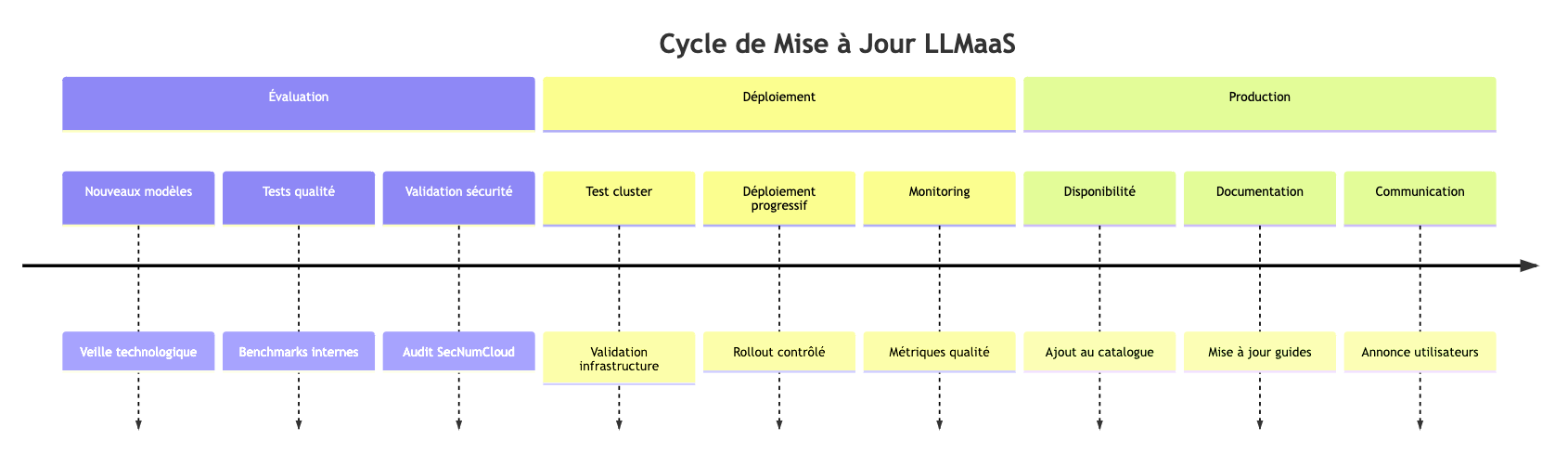
Versionsrichtlinie
- Stabile Modelle : Feste Versionen 6 Monate verfügbar
- Experimentelle Modelle : Beta-Versionen für Early Adopters
- Deprecation : 3-monatige Vorankündigung vor der Einstellung
- Migration : Professionelle Dienstleistungen stehen für reibungslose Übergänge zur Verfügung
Voraussichtlicher Lebenszyklusplan
Die untenstehende Tabelle zeigt den voraussichtlichen Lebenszyklus unserer Modelle. Das Ökosystem der generativen KI entwickelt sich sehr schnell, was zu Lebenszyklen führen kann, die kurz erscheinen. Unser Ziel ist es, Ihnen Zugang zu den aktuell leistungsfähigsten Modellen zu gewähren.
Wir verpflichten uns jedoch, die von unseren Kunden am häufigsten genutzten Modelle langfristig zu erhalten. Für kritische Anwendungsfälle, die langfristige Stabilität erfordern, sind Phasen mit erweitertem Support möglich. Zögern Sie nicht, den Support zu kontaktieren, um Ihre spezifischen Anforderungen zu besprechen.
Dieser Plan dient nur als Orientierung und wird zu Beginn jedes Quartals überarbeitet.
- DMP (Datum der Produktionsfreigabe) : Datum, an dem das Modell in der Produktion verfügbar wird.
- DSP (Datum des Supportendes) : Voraussichtliches Datum, ab dem das Modell nicht mehr gewartet wird. Vor jeder tatsächlichen Einstellung wird eine Frist von 3 Monaten eingehalten.
| Modell | Anbieter | Phase | DMP | DSP | LTS | Empfohlene Migration |
|---|---|---|---|---|---|---|
| cogito:32b | Deep Cogito | Produktion | 13/06/2025 | 30/06/2026 | Nein | gpt-oss:120b |
| embeddinggemma:300m | Produktion | 10/09/2025 | 30/06/2026 | Nein | ||
| gemma3:27b | Produktion | 13/06/2025 | 30/06/2026 | Nein | ||
| glm-4.7-flash:30b | Zhipu AI | Produktion | 22/01/2026 | 30/06/2026 | Nein | |
| ministral-3:14b | Mistral AI | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| ministral-3:3b | Mistral AI | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| ministral-3:8b | Mistral AI | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| olmo-3:32b | AllenAI | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| olmo-3:7b | AllenAI | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| qwen3-omni:30b | Qwen Team | Produktion | 05/01/2026 | 30/06/2026 | Nein | |
| qwen3-vl:2b | Qwen Team | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| qwen3-vl:32b | Qwen Team | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| qwen3-vl:8b | Qwen Team | Produktion | 05/01/2026 | 30/06/2026 | Nein | |
| rnj-1:8b | Essential AI | Produktion | 30/12/2025 | 30/06/2026 | Nein | |
| devstral-small-2:24b | Mistral AI & All Hands AI | Produktion | 02/02/2026 | 30/09/2026 | Nein | |
| gemma4:e2b | Produktion | 19/04/2026 | 30/09/2026 | Nein | ||
| gemma4:e4b | Produktion | 19/04/2026 | 30/09/2026 | Nein | ||
| gpt-oss:20b | OpenAI | Produktion | 08/08/2025 | 30/09/2026 | Nein | |
| mistral-small3.2:24b | Mistral AI | Produktion | 23/06/2025 | 30/09/2026 | Nein | |
| qwen3.5:4b | Qwen Team | Produktion | 24/03/2026 | 30/09/2026 | Nein | |
| qwen3.5:9b | Qwen Team | Produktion | 24/03/2026 | 30/09/2026 | Nein | |
| bge-reranker-large | BAAI | Produktion | 13/05/2026 | 30/12/2026 | Nein | |
| deepseek-ocr | DeepSeek AI | Produktion | 22/11/2025 | 30/12/2026 | Nein | |
| functiongemma:270m | Produktion | 30/12/2025 | 30/12/2026 | Nein | ||
| gemma4:31b | Produktion | 14/04/2026 | 30/12/2026 | Nein | ||
| granite3-guardian:2b | IBM | Produktion | 13/06/2025 | 30/12/2026 | Nein | |
| granite3-guardian:8b | IBM | Produktion | 13/06/2025 | 30/12/2026 | Nein | |
| granite3.2-vision:2b | IBM | Produktion | 13/06/2025 | 30/12/2026 | Nein | |
| mistral-small4:119b | Mistral AI | Produktion | 13/05/2026 | 30/12/2026 | Nein | |
| nemotron-3-super:120b | NVIDIA | Produktion | 01/04/2026 | 30/12/2026 | Nein | |
| nemotron-cascade:30b | NVIDIA | Produktion | 01/04/2026 | 30/12/2026 | Nein | |
| nemotron3-nano:30b | NVIDIA | Produktion | 04/01/2026 | 30/12/2026 | Nein | |
| qwen-coder-next:80b | Qwen Team | Produktion | 04/02/2026 | 30/12/2026 | Nein | |
| qwen3-embedding:0.6b | Qwen Team | Produktion | 14/05/2026 | 30/12/2026 | Nein | |
| qwen3-embedding:4b | Qwen Team | Produktion | 14/05/2026 | 30/12/2026 | Nein | |
| qwen3-embedding:8b | Qwen Team | Produktion | 14/05/2026 | 30/12/2026 | Nein | |
| qwen3-next:80b | Qwen Team | Produktion | 02/02/2026 | 30/12/2026 | Nein | |
| qwen3-reranker:0.6b | Qwen Team | Produktion | 13/05/2026 | 30/12/2026 | Nein | |
| qwen3-reranker:4b | Qwen Team | Produktion | 13/05/2026 | 30/12/2026 | Nein | |
| qwen3-vl:235b | Qwen Team | Produktion | 04/01/2026 | 30/12/2026 | Nein | |
| qwen3-vl:30b | Qwen Team | Produktion | 30/12/2025 | 30/12/2026 | Nein | |
| qwen3-vl:4b | Qwen Team | Produktion | 30/12/2025 | 30/12/2026 | Nein | |
| qwen3.5:0.8b | Qwen Team | Produktion | 24/03/2026 | 30/12/2026 | Nein | |
| qwen3.6:27b | Qwen Team | Produktion | 01/05/2026 | 30/12/2026 | Nein | |
| qwen3.6:35b | Qwen Team | Produktion | 01/05/2026 | 30/12/2026 | Nein | |
| qwen3:0.6b | Qwen Team | Produktion | 13/06/2025 | 30/12/2026 | Ja | |
| translategemma:12b | Produktion | 22/01/2026 | 30/12/2026 | Nein | ||
| translategemma:27b | Produktion | 22/01/2026 | 30/12/2026 | Nein | ||
| translategemma:4b | Produktion | 22/01/2026 | 30/12/2026 | Nein | ||
| voxtral | Mistral AI | Produktion | 01/04/2026 | 30/12/2026 | Nein | |
| z-image:16b | Community | Produktion | 01/04/2026 | 30/12/2026 | Nein | |
| nvidia/llama-nemotron-rerank-vl-1b-v2 | NVIDIA | Produktion | 13/05/2026 | 30/06/2027 | Nein | |
| bge-m3:567m | BAAI | Produktion | 18/10/2025 | 30/12/2027 | Ja | |
| gpt-oss:120b | OpenAI | Produktion | 11/11/2025 | 30/12/2027 | Ja | |
| granite-embedding:278m | IBM | Produktion | 13/06/2025 | 30/12/2027 | Ja | |
| llama3.3:70b | Meta | Produktion | 13/06/2025 | 30/12/2027 | Ja | |
| qwen3-2507:235b | Qwen Team | Produktion | 04/01/2026 | 30/12/2027 | Ja | |
| qwen3-2507-think:4b | Qwen Team | Produktion | 31/08/2025 | 30/12/2027 | Ja |
Legende
- Phase: Lebenszyklus des Modells (Evaluation, Produktion, Veraltet)
- DMP: Datum der Produktionsfreigabe
- DSP: Geplantes Löschdatum
- LTS: Long Term Support. LTS-Modelle bieten garantierte Stabilität und erweiterten Support, ideal für kritische Anwendungen.
- Empfohlene Migration: Empfohlenes Modell zum Ersetzen eines Modells am Ende seines Lebenszyklus.
Um den Status des Lebenszyklus in Echtzeit zu verfolgen, konsultieren Sie die Seite: LLMaaS Status - Lebenszyklus
Veraltete Modelle
Die Welt der LLMs entwickelt sich sehr schnell. Um unseren Kunden den Zugang zu den leistungsfähigsten Technologien zu gewährleisten, kündigen wir regelmäßig Modelle ab, die nicht mehr den aktuellen Standards entsprechen oder nicht genutzt werden. Die nachfolgend aufgeführten Modelle sind auf der öffentlichen Plattform nicht mehr verfügbar. Sie können jedoch auf Anfrage für spezifische Projekte wieder aktiviert werden.
| Modell | Status | Datum der Abkündigung |
|---|---|---|
| devstral:24b | Abgekündigt | 30/03/2026 |
| granite3.1-moe:2b | Abgekündigt | 30/03/2026 |
| granite4-small-h:32b | Abgekündigt | 15/05/2026 |
| granite4-tiny-h:7b | Abgekündigt | 15/05/2026 |
| medgemma:27b | Abgekündigt | 15/05/2026 |
| qwen3-2507-gptq:235b | Abgekündigt | 15/05/2026 |
| qwen3-coder:30b | Abgekündigt | 30/03/2026 |
| qwen3:30b-a3b | Abgekündigt | 30/03/2026 |
| deepseek-r1:14b | Abgekündigt | 30/12/2025 |
| deepseek-r1:32b | Abgekündigt | 30/12/2025 |
| gemma3:1b | Abgekündigt | 30/12/2025 |
| gemma3:4b | Abgekündigt | 30/12/2025 |
| qwen3:1.7b | Abgekündigt | 30/12/2025 |
| qwen3:14b | Abgekündigt | 30/12/2025 |
| qwen3:4b | Abgekündigt | 30/12/2025 |
| qwen3:8b | Abgekündigt | 30/12/2025 |
| qwen3:32b | Abgekündigt | 30/12/2025 |
| qwq:32b | Abgekündigt | 30/12/2025 |
| granite3.3:2b | Abgekündigt | 30/12/2025 |
| granite3.3:8b | Abgekündigt | 30/12/2025 |
| mistral-small3.1:24b | Abgekündigt | 30/12/2025 |
| qwen2.5vl:32b | Abgekündigt | 30/12/2025 |
| qwen2.5vl:3b | Abgekündigt | 30/12/2025 |
| qwen2.5vl:72b | Abgekündigt | 30/12/2025 |
| qwen2.5vl:7b | Abgekündigt | 30/12/2025 |
| cogito:8b | Abgekündigt | 30/12/2025 |
| deepcoder:14b | Abgekündigt | 30/12/2025 |
| cogito:3b | Abgekündigt | 30/12/2025 |
| qwen3:235b | Abgekündigt | 22/11/2025 |
| qwen3-2507-think:30b-a3b | Abgekündigt | 14/11/2025 |
| gemma3:12b | Abgekündigt | 21/11/2025 |
| cogito:14b | Abgekündigt | 17/10/2025 |
| deepseek-r1:70b | Abgekündigt | 17/10/2025 |
| granite3.1-moe:3b | Abgekündigt | 17/10/2025 |
| llama3.1:8b | Abgekündigt | 17/10/2025 |
| phi4-reasoning:14b | Abgekündigt | 17/10/2025 |
| qwen2.5:0.5b | Abgekündigt | 17/10/2025 |
| qwen2.5:1.5b | Abgekündigt | 17/10/2025 |
| qwen2.5:14b | Abgekündigt | 17/10/2025 |
| qwen2.5:32b | Abgekündigt | 17/10/2025 |
| qwen2.5:3b | Abgekündigt | 17/10/2025 |
| deepseek-r1:671b | Abgekündigt | 17/10/2025 |
💡 Best Practices
Um das Beste aus der LLMaaS-API herauszuholen, ist es entscheidend, Strategien zur Optimierung von Kosten, Leistung und Sicherheit zu verfolgen.
Kostenoptimierung
Die Kostenkontrolle basiert auf einem intelligenten Einsatz von Tokens und Modellen.
-
Modellauswahl : Verwenden Sie kein übermächtiges Modell für eine einfache Aufgabe. Ein größeres Modell ist leistungsfähiger, aber auch langsamer und verbraucht deutlich mehr Energie, was sich direkt auf die Kosten auswirkt. Passen Sie die Modellgröße an die Komplexität Ihrer Anforderung an, um ein optimales Gleichgewicht zu erzielen.
Beispielsweise für die Verarbeitung einer Million Tokens :
Gemma 3 1Bverbraucht 0,15 kWh.Llama 3.3 70Bverbraucht 11,75 kWh, also 78-mal mehr.
# Für eine Sentiment-Klassifizierung reicht ein kompaktes Modell aus und ist kosteneffizient.if task == "sentiment_analysis":model = "qwen3.5:0.8b"# Für eine komplexe juristische Analyse ist ein größeres Modell erforderlich.elif task == "legal_analysis":model = "gpt-oss:120b" -
Kontextverwaltung : Der Konversationsverlauf (
messages) wird bei jedem Aufruf zurückgegeben und verbraucht Eingabe-Tokens. Bei langen Konversationen sollten Sie Zusammenfassungs- oder Fensterstrategien in Betracht ziehen, um nur relevante Informationen zu speichern.# Bei einer langen Konversation können die ersten Austausche zusammengefasst werden.messages = [{"role": "system", "content": "Vous êtes un assistant IA."},{"role": "user", "content": "Résumé des 10 premiers échanges..."},{"role": "assistant", "content": "Ok, j'ai le contexte."},{"role": "user", "content": "Voici ma nouvelle question."}] -
Begrenzung der Ausgabe-Tokens : Verwenden Sie immer den Parameter
max_tokens, um übermäßig lange und kostspielige Antworten zu vermeiden. Legen Sie ein angemessenes Limit fest, das auf Ihren Erwartungen basiert.# Eine Zusammenfassung von maximal 100 Wörtern anfordern.response = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Résume ce document..."}],max_tokens=150, # Sicherheitspuffer für ~100 Wörter)
Performance
Die Reaktionsfähigkeit Ihrer Anwendung hängt davon ab, wie Sie die API-Aufrufe verwalten.
-
Asynchrone Anfragen : Um mehrere Anfragen zu verarbeiten, ohne auf das Ende jeder einzelnen zu warten, verwenden Sie asynchrone Aufrufe. Dies ist besonders nützlich für Backend-Anwendungen, die ein hohes Volumen an gleichzeitigen Anfragen verarbeiten.
import asynciofrom openai import AsyncOpenAIclient = AsyncOpenAI(api_key="...", base_url="...")async def process_prompt(prompt: str):# Verarbeitet eine einzelne Anfrage asynchronresponse = await client.chat.completions.create(model="gpt-oss:120b", messages=[{"role": "user", "content": prompt}])return response.choices[0].message.contentasync def batch_requests(prompts: list):# Startet mehrere Aufgaben parallel und wartet auf deren Abschlusstasks = [process_prompt(p) for p in prompts]return await asyncio.gather(*tasks) -
Streaming für die Benutzererfahrung (UX) : Für Benutzeroberflächen (Chatbots, Assistenten) ist Streaming unerlässlich. Es ermöglicht die wortweise Anzeige der Modellantwort, was ein Gefühl der sofortigen Reaktionsfähigkeit vermittelt, anstatt auf die vollständige Antwort zu warten.
# Zeigt die Antwort in Echtzeit in einer Benutzeroberfläche anresponse_stream = client.chat.completions.create(model="gpt-oss:120b",messages=[{"role": "user", "content": "Raconte-moi une histoire."}],stream=True)for chunk in response_stream:if chunk.choices[0].delta.content:# Zeigt den Textabschnitt in der Benutzeroberfläche anprint(chunk.choices[0].delta.content, end="", flush=True)
Sicherheit
Die Sicherheit Ihrer Anwendung ist von entscheidender Bedeutung, insbesondere beim Verarbeiten von Benutzereingaben.
-
Validierung und Bereinigung von Eingaben (Sanitization): Vertrauen Sie Benutzereingaben niemals. Bereinigen Sie diese vor dem Senden an die API, um potenziell schädlichen Code oder Anweisungen zur „Prompt Injection“ zu entfernen. Beschränken Sie außerdem deren Größe, um Missbrauch zu vermeiden.
def sanitize_input(user_input: str) -> str:# Einfaches Beispiel: Entfernen von Code-Markierungen und Begrenzen der Länge.# Für eine erweiterte Bereinigung können robustere Bibliotheken verwendet werden.cleaned = user_input.replace("`", "").replace("'", "").replace("\"", "")return cleaned[:2000] # Begrenzt die Größe auf 2000 Zeichen -
Robuste Fehlerbehandlung: Umgeben Sie Ihre API-Aufrufe immer mit
try...except-Blöcken, um Netzwerkfehler, API-Fehler (z. B. 429 Rate Limit, 500 Internal Server Error) zu behandeln und eine eingeschränkte, aber funktionale Benutzererfahrung bereitzustellen.from openai import APIError, APITimeoutErrortry:response = client.chat.completions.create(...)except APITimeoutError:# Behandelt den Fall, dass die Anfrage zu lange dauertreturn "Le service prend plus de temps que prévu, veuillez réessayer."except APIError as e:# Behandelt API-spezifische Fehlerlogger.error(f"Erreur API LLMaaS: {e.status_code} - {e.message}")return "Désolé, une erreur est survenue avec le service d'IA."except Exception as e:# Behandelt alle anderen Fehler (Netzwerk, usw.)logger.error(f"Une erreur inattendue est survenue: {e}")return "Désolé, une erreur inattendue est survenue."